MySQL全面瓦解28:分库分表
1 为什么要分库分表
2 垂直拆分(Scale Up 纵向扩展)
垂直拆分分为垂直分库和垂直分表,主要按功能模块拆分,以解决各个库或者各个表之间的资源竞争。比如分为订单库、商品库、用户库...这种方式,多个数据库之间的表结构是不同的。
2.1 垂直分库
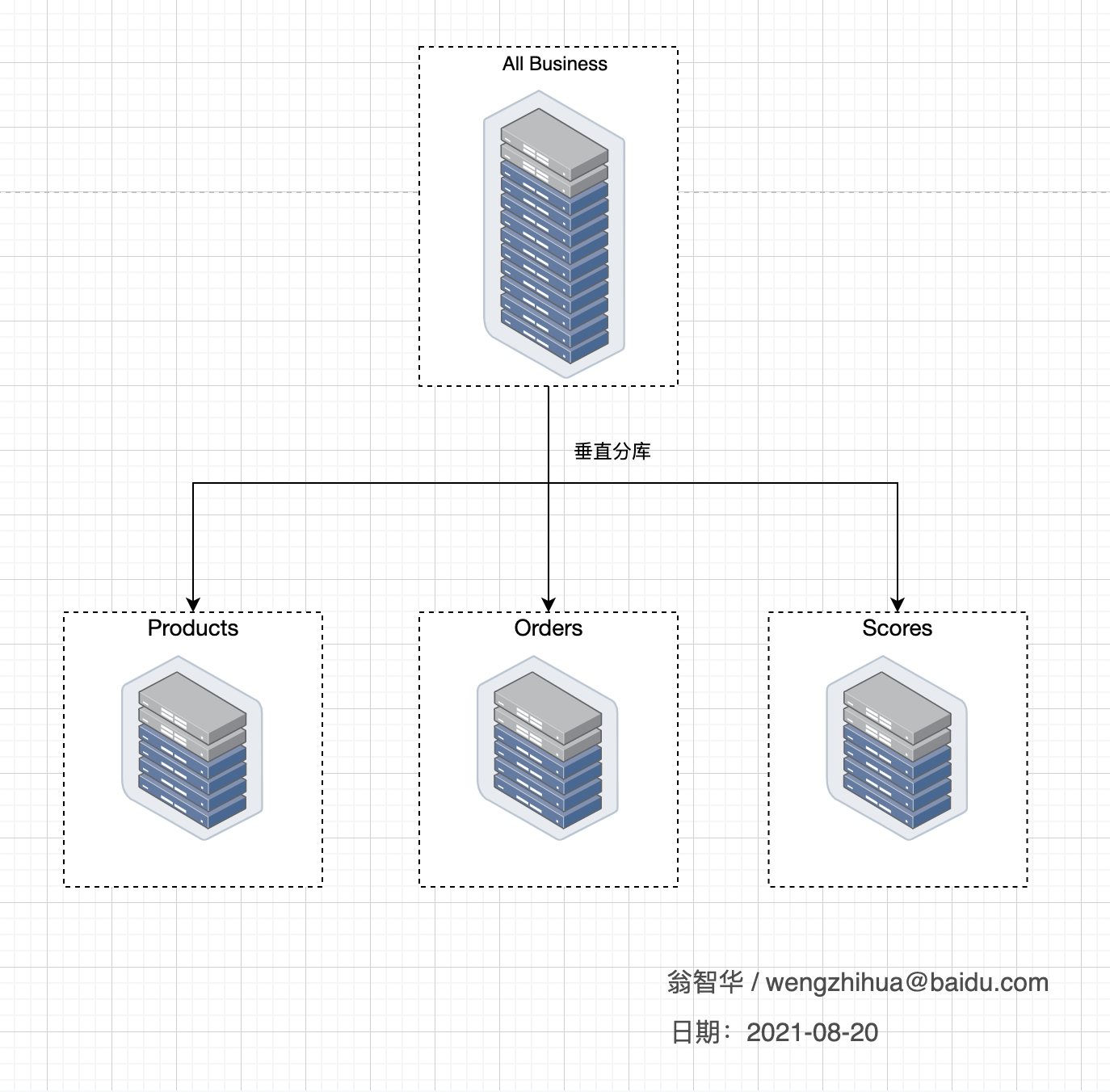
2.2 垂直分表
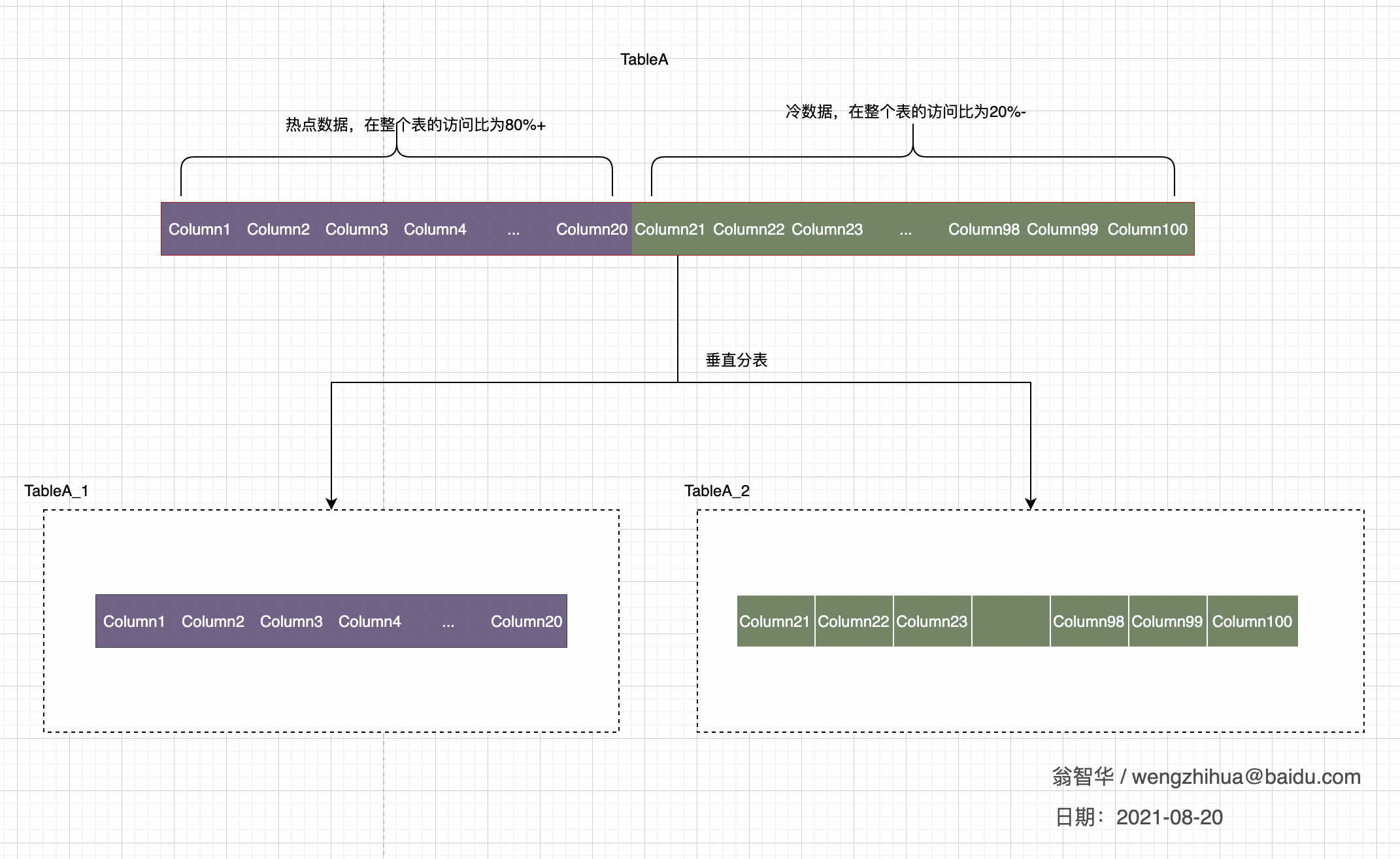
- 跟随业务进行分割,类似微服务的分治理念,方便解耦之后的管理及扩展。
- 高并发的场景下,垂直拆分使用多台服务器的CPU、I/O、内存能提升性能,同时对单机数据库连接数、一些资源限制也得到了提升,能实现冷热数据的分离。
- 部分业务表无法join,应用层需要很大的改造,只能通过聚合的方式来实现。增加了开发的难度。
- 单表数据量膨胀的问题依然没有得到有效的解决。分布式事务也是一个难题。
3 水平拆分(Scale Out 横向扩展)
水平拆分又分为库内分表和分库分表,来解决单表中数据量增长出现的压力,这些数据库中的表结构完全相同。
3.1 库内分表

关于水平分表的时机,业内的标准不是很统一,阿里的Java 开发手册的标准是当单表行数超过 500万行或者单表容量超过 2 GB时,才推荐进行分库分表。百度的则是1000 W行的进行分表,这个是百度的DBA经过测试推算出的结果。
但是这边忽略了单表的字段数和字段类型,如果字段数很多,超过50列,对性能影响也是不小的,我们曾经有个业务,表字段是随着业务的增长而自动扩增的,到了后期,字段越来越多,查询性能也越来越慢。
所以个人觉得不必拘泥于500W 还是1000W,开发人员在使用过程中,如果压测发现因为数据基数变大而导致执行效率慢下来,就可以开始考虑分表了。
3.2 库内分表的实现策略
目前在MySql中支持四种表分区的方式,分别为HASH、RANGE、LIST及KEY,当然在其它的类型数据库中,分区的实现方式略有不同,但是分区的思想原理是相同,具体如下:
3.2.1 HASH(哈希)
HASH分区主要用来确保数据在预先确定数目的分区中平均分布,而在RANGE和LIST分区中,必须明确指定一个给定的列值或列值集合应该保存在哪个分区中,而在HASH分区中,MySQL自动完成这些工作,
你所要做的只是基于将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。 示例如下:
1 drop table if EXISTS `t_userinfo`;
2 CREATE TABLE `t_userinfo` (
3 `id` int(10) unsigned NOT NULL,
4 `personcode` varchar(20) DEFAULT NULL,
5 `personname` varchar(100) DEFAULT NULL,
6 `depcode` varchar(100) DEFAULT NULL,
7 `depname` varchar(500) DEFAULT NULL,
8 `gwcode` int(11) DEFAULT NULL,
9 `gwname` varchar(200) DEFAULT NULL,
10 `gravalue` varchar(20) DEFAULT NULL,
11 `createtime` DateTime NOT NULL
12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8
13 PARTITION BY HASH(YEAR(createtime))
14 PARTITIONS 10;
上面的例子,使用HASH函数对createtime日期进行HASH运算,并根据这个日期来分区数据,这里共分为10个分区。
建表语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回整数的表达式,它可以是字段类型为MySQL 整型的一列的名字,也可以是返回非负数的表达式。
另外,可能需要在后面再添加一个“PARTITIONS num”子句,其中num 是一个非负的整数,它表示表将要被分割成分区的数量。
3.2.2 RANGE(范围)
基于属于一个给定连续区间的列值,把多行分配给同一个分区,这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。示例如下:
1 drop table if EXISTS `t_userinfo`;
2 CREATE TABLE `t_userinfo` (
3 `id` int(10) unsigned NOT NULL,
4 `personcode` varchar(20) DEFAULT NULL,
5 `personname` varchar(100) DEFAULT NULL,
6 `depcode` varchar(100) DEFAULT NULL,
7 `depname` varchar(500) DEFAULT NULL,
8 `gwcode` int(11) DEFAULT NULL,
9 `gwname` varchar(200) DEFAULT NULL,
10 `gravalue` varchar(20) DEFAULT NULL,
11 `createtime` DateTime NOT NULL
12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8
13 PARTITION BY RANGE(gwcode) (
14 PARTITION P0 VALUES LESS THAN(101) ,
15 PARTITION P1 VALUES LESS THAN(201) ,
16 PARTITION P2 VALUES LESS THAN(301) ,
17 PARTITION P3 VALUES LESS THAN MAXVALUE
18 );
上面的示例,使用了范围RANGE函数对岗位编号进行分区,共分为4个分区,
岗位编号为1~100 的对应在分区P0中,101~200的编号在分区P1中,依次类推即可。那么类别编号大于300,可以使用MAXVALUE来将大于300的数据统一存放在分区P3中即可。
3.2.3 LIST(预定义列表)
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择分区的。LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr” 是某列值或一个基于某个列值、并返回一个整数值的表达式,
然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。 示例如下:
1 drop table if EXISTS `t_userinfo`;
2 CREATE TABLE `t_userinfo` (
3 `id` int(10) unsigned NOT NULL,
4 `personcode` varchar(20) DEFAULT NULL,
5 `personname` varchar(100) DEFAULT NULL,
6 `depcode` varchar(100) DEFAULT NULL,
7 `depname` varchar(500) DEFAULT NULL,
8 `gwcode` int(11) DEFAULT NULL,
9 `gwname` varchar(200) DEFAULT NULL,
10 `gravalue` varchar(20) DEFAULT NULL,
11 `createtime` DateTime NOT NULL
12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8
13 PARTITION BY LIST(`gwcode`) (
14 PARTITION P0 VALUES IN (46,77,89) ,
15 PARTITION P1 VALUES IN (106,125,177) ,
16 PARTITION P2 VALUES IN (205,219,289) ,
17 PARTITION P3 VALUES IN (302,317,458,509,610)
18 );
上面的例子,使用了列表匹配LIST函数对员工岗位编号进行分区,共分为4个分区,编号为46,77,89的对应在分区P0中,106,125,177类别在分区P1中,依次类推即可。
不同于RANGE的是,LIST分区的数据必须匹配列表中的岗位编号才能进行分区,所以这种方式只是适合比较区间值确定并少量的情况。
3.2.4 KEY(键值)
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。 示例如下:
1 drop table if EXISTS `t_userinfo`;
2 CREATE TABLE `t_userinfo` (
3 `id` int(10) unsigned NOT NULL,
4 `personcode` varchar(20) DEFAULT NULL,
5 `personname` varchar(100) DEFAULT NULL,
6 `depcode` varchar(100) DEFAULT NULL,
7 `depname` varchar(500) DEFAULT NULL,
8 `gwcode` int(11) DEFAULT NULL,
9 `gwname` varchar(200) DEFAULT NULL,
10 `gravalue` varchar(20) DEFAULT NULL,
11 `createtime` DateTime NOT NULL
12 ) ENGINE=InnoDB DEFAULT CHARSET=utf8
13 PARTITION BY KEY(gwcode)
14 PARTITIONS 10;
注意:此种分区算法目前使用的比较少,使用服务器提供的哈希函数有不确定性,对于后期数据统计、整理存在会更复杂,所以我们更倾向于使用由我们定义表达式的Hash,大家知道其存在和怎么使用即可。
3.2.5 Composite(复合模式)
Composite是上面几种模式的组合使用,比如你在Range的基础上,再进行Hash 哈希分区。
3.3 分库分表
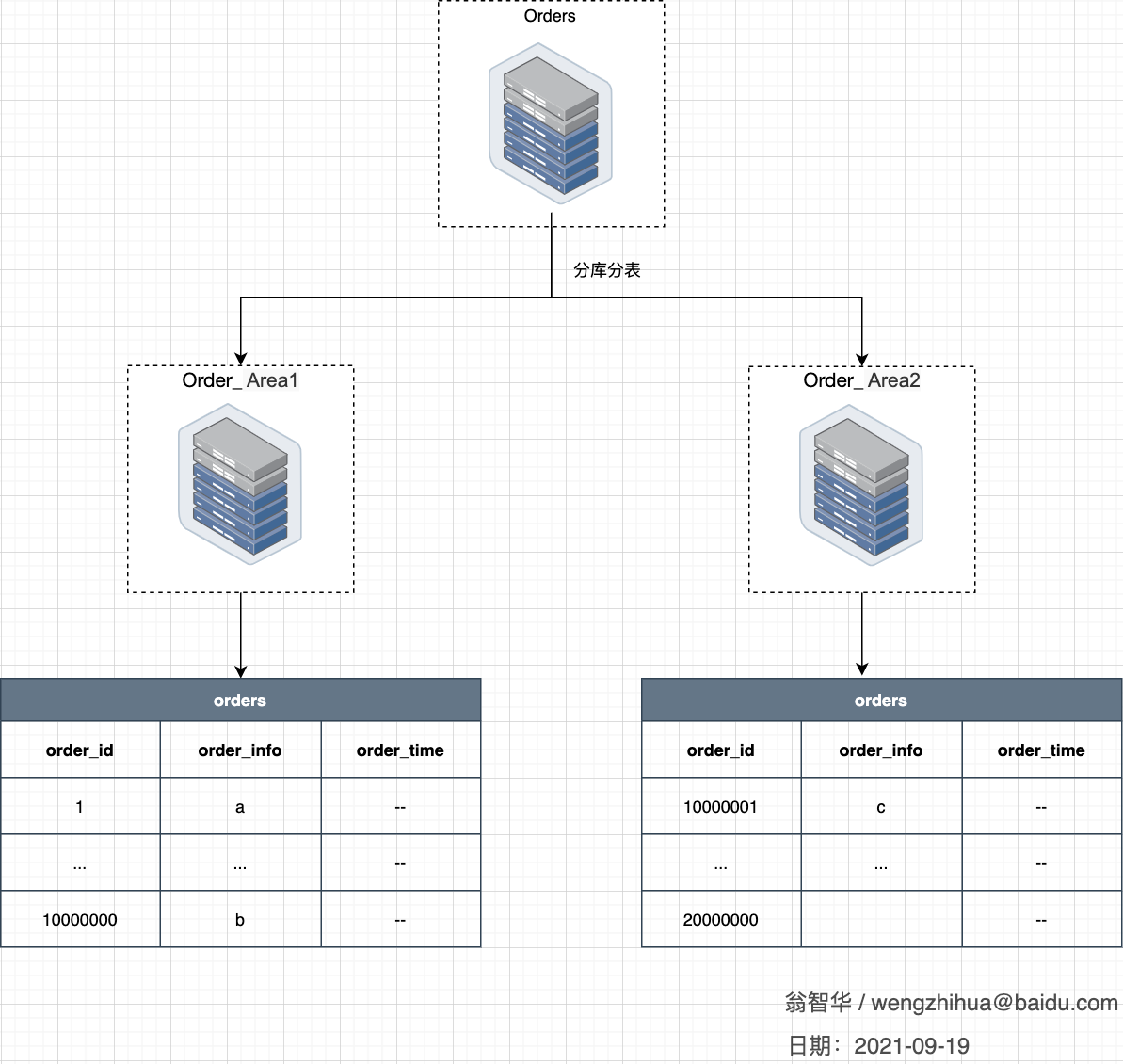
4 分库分表存在的问题
4.1 事务问题
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
4.2 跨库跨表的join问题
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
4.3 额外的数据管理负担和数据运算压力
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,
只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
MySQL全面瓦解28:分库分表的更多相关文章
- MYSQL性能优化分享(分库分表)
1.分库分表 很明显,一个主表(也就是很重要的表,例如用户表)无限制的增长势必严重影响性能,分库与分表是一个很不错的解决途径,也就是性能优化途径,现在的案例是我们有一个1000多万条记录的用户表mem ...
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一.前言 在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个: 1. 分布式全局唯一id 2. 分片规则和策略 3. 跨分片技术问题 4. 跨分片事物 ...
- Mycat数据库中间件对Mysql读写分离和分库分表配置
Mycat是一个开源的分布式数据库系统,不同于oracle和mysql,Mycat并没有存储引擎,但是Mycat实现了mysql协议,前段用户可以把它当做一个Proxy.其核心功能是分表分库,即将一个 ...
- 3.Mysql集群------Mycat分库分表
前言: 分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的. 只是把字段散列的分到不同的库中. 实践: 1.修改schema.xml 这里是在同一台服务器上建立了4个数据库db1,db ...
- 【MySQL】数据库(分库分表)中间件对比
分区:对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表 ...
- MySQL系列(八)--数据库分库分表
在互联网公司或者一些并发量比较大的项目,虽然有各种项目架构设计.NoSQL.MQ.ES等解决比较高的并发访问,但是对于数据库来说,压力 还是太大,这时候即使数据库架构.表结构.索引等都设计的很好了,但 ...
- MySQL:互联网公司常用分库分表方案汇总!
转载别人 一.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值.在业务Service来看就是,可用数据库连接少甚至无连接可用 ...
- MySQL:互联网公司常用分库分表方案汇总!
一.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值.在业务Service来看就是,可用数据库连接少甚至无连接可用.接下来就 ...
- 数据字符集mysql主从数据库,分库分表等笔记
文章结束给大家来个程序员笑话:[M] 1.mysql的目录:在rpm或者yum安装时:/var/lib/mysql 在编译安装时默许目录:/usr/local/mysql 2.用rpm包安装的MyS ...
- MySQL主从复制&读写分离&分库分表
MySQL主从复制 MySQL的主从复制只能保证主机对外提供服务,从机是不提供服务的,只是在后台为主机进行备份数据 首先我们说说主从复制的原理,这个是必须要理解的玩意儿: 理解: MySQL之间的数据 ...
随机推荐
- Ysoserial Commons Collections7分析
Ysoserial Commons Collections7分析 写在前面 CommonsCollections Gadget Chains CommonsCollection Version JDK ...
- python flask1
以这个服务端代码为例,简单了解一下flask的运用. 1.app = Flask(__name__)记住就好了 2.@app.route("/")记住就好了:注意括号里的是调用这个 ...
- logstash处理多行日志-处理java堆栈日志
logstash处理多行日志-处理java堆栈日志 一.背景 二.需求 三.实现思路 1.分析日志 2.实现,编写pipeline文件 四.注意事项 五.参考文档 一.背景 在我们的java程序中,经 ...
- echart3 力引导布局实现节点的提示和折叠
最近在项目中需要开发一个图表来显示人员的各种属性,类似于一种树形的结构进行显示数据.如果多个人员有同一个属性,那么需要将相同的属性进行连线,即关联起来.即形成一个关系图,由于我自身对echarts稍微 ...
- 斐波那契数列 牛客网 剑指Offer
斐波那契数列 牛客网 剑指Offer 题目描述 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0). n<=39 class Solution: ...
- 从0到1搭建自己的组件(vue-code-view)库(下)
0x00 前言 书接上文,本文将从源码功能方面讲解下 vue-code-view 组件核心逻辑,您可以了解以下内容: 动态组件的使用. codeMirror插件的使用. 单文件组件(SFC,singl ...
- 非对称加密和linux上的 ssh-keygen 工具使用
rsa :创造非对称加密的三个人名.原理是两个1024到2048之间的素数,以此为乘积.等... a*b=c 一般a*b为私钥端,c为公钥端.因为 c非常难算出a和b. ssh-keygen -t ...
- Linux 文本三剑客之 sed
Linux 系统中一切皆文件. 文件是个文本.可以读.可以写,如果是二进制文件,还能执行. 在使用Linux的时候,大都是要和各式各样文件打交道.熟悉文本的读取.编辑.筛选就是linux系统管理员的必 ...
- TCP粘"包"问题浅析及解决方案Golang代码实现
一.粘"包"问题简介 在socket网络编程中,都是端到端通信,客户端端口+客户端IP+服务端端口+服务端IP+传输协议就组成一个可以唯一可以明确的标识一条连接.在TCP的sock ...
- url,href,src 之间的区别
url 统一资源定位符 <style> #bg{ background-image:url("img/bg.png"); } </style> 区别: sr ...