[Scikit-learn] 2.1 Clustering - Variational Bayesian Gaussian Mixture
最重要的一点是:Bayesian GMM为什么拟合的更好?
PRML 这段文字做了解释:

Ref: http://freemind.pluskid.org/machine-learning/deciding-the-number-of-clusterings/
链接中提到了一些其他的无监督聚类。
From: http://scikit-learn.org/stable/modules/mixture.html#variational-bayesian-gaussian-mixture
Due to its Bayesian nature, the variational algorithm needs more hyper- parameters than expectation-maximization,
the most important of these being the concentration parameter weight_concentration_prior.
- Specifying a low value for the concentration prior will make the model put most of the weight on few components set the remaining components weights very close to zero.
- High values of the concentration prior will allow a larger number of components to be active in the mixture.
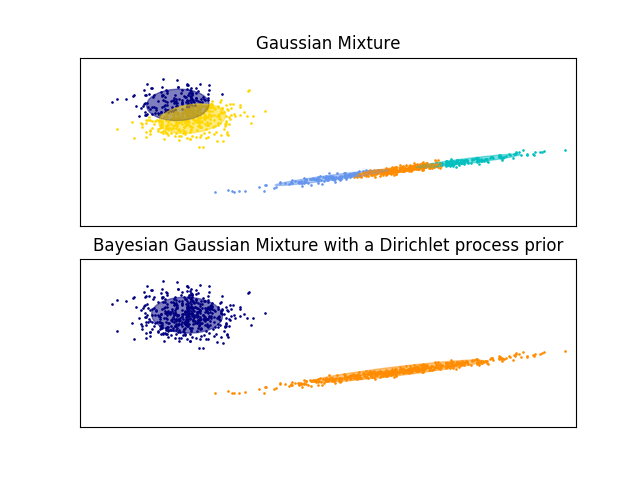
The examples below compare Gaussian mixture models with a fixed number of components, to the variational Gaussian mixture models with a Dirichlet process prior. Here, a classical Gaussian mixture is fitted with 5 components on a dataset composed of 2 clusters.
We can see that the variational Gaussian mixture with a Dirichlet process prior is able to limit itself to only 2 components whereas the Gaussian mixture fits the data with a fixed number of components that has to be set a priori by the user. In this case the user has selected n_components=5 which does not match the true generative distribution of this toy dataset. Note that with very little observations, the variational Gaussian mixture models with a Dirichlet process prior can take a conservative stand, and fit only one component.
Dirichlet distribution 具有自动的特征选取的作用,找出起主要作用的components。
5 for GMM
[ 0.1258077 0.23638361 0.23330578 0.26361639 0.14088652]
5 for Bayesian GMM
[ 0.001019 0.00101796 0.49948856 0.47955123 0.01892325]
问题来了:
为什么dirichlet会让三个的权重偏小,而GMM却没有,难道是收敛速度不同?
应该跟速度没有关系。加了先验后,后验变为了dirichlet,那么参数的估计过程中便具备了dirichlet的良好性质。
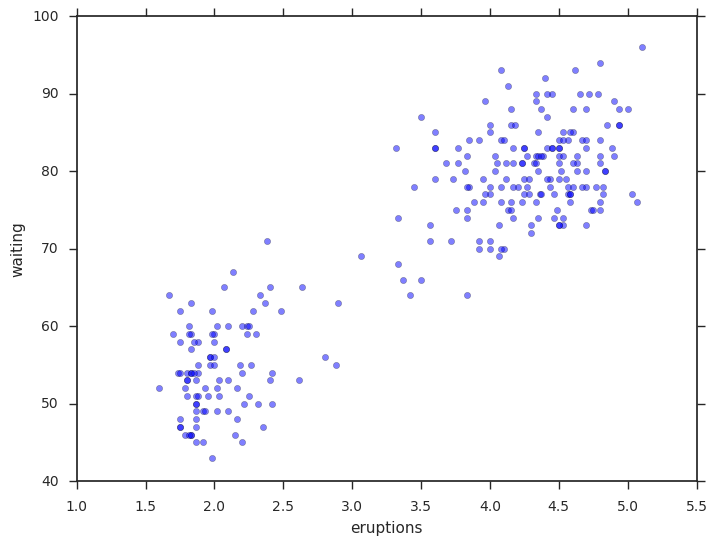
原始数据
Our data set will be the classic Old Faithful dataset.
plt.scatter(data['eruptions'], data['waiting'], alpha=0.5);
plt.xlabel('eruptions');
plt.ylabel('waiting');
如何拟合?
from sklearn.mixture import BayesianGaussianMixture mixture_model = BayesianGaussianMixture(
n_components=10,
random_state=5, # control the pseudo-random initialization
weight_concentration_prior_type='dirichlet_distribution',
weight_concentration_prior=1.0, # parameter of the Dirichlet component prior
max_iter=200, # choose this to be big in case it takes a long time to fit
)
mixture_model.fit(data);
Ref: http://scikit-learn.org/stable/auto_examples/mixture/plot_concentration_prior.html
可直接调用该程式:
plot_ellipses(ax1, model.weights_, model.means_, model.covariances_) def plot_ellipses(ax, weights, means, covars):
"""
Given a list of mixture component weights, means, and covariances,
plot ellipses to show the orientation and scale of the Gaussian mixture dispersal.
"""
for n in range(means.shape[0]):
eig_vals, eig_vecs = (covars[n])
unit_eig_vec = eig_vecs[0] / np.linalg.norm(eig_vecs[0])
angle = np.arctan2(unit_eig_vec[1], unit_eig_vec[0])
# Ellipse needs degrees
angle = 180 * angle / np.pi
# eigenvector normalization
eig_vals = 2 * np.sqrt(2) * np.sqrt(eig_vals)
ell = mpl.patches.Ellipse(
means[n], eig_vals[0], eig_vals[1],
180 + angle,
edgecolor=None,)
ell2 = mpl.patches.Ellipse(
means[n], eig_vals[0], eig_vals[1],
180 + angle,
edgecolor='black',
fill=False,
linewidth=1,)
ell.set_clip_box(ax.bbox)
ell2.set_clip_box(ax.bbox)
ell.set_alpha(weights[n])
ell.set_facecolor('#56B4E9')
ax.add_artist(ell)
ax.add_artist(ell2)
plot_results(
mixture_model,
data['eruptions'], data['waiting'],
'weight_concentration_prior={}'.format(1.0)) def plot_results(model, x, y, title, plot_title=False): fig, ax = plt.subplots(3, 1, sharex=False)
# 上面是ax没用,以下重新定义了ax1 ax2
gs = gridspec.GridSpec(3, 1) # 自定义子图位置
ax1 = plt.subplot(gs[0:2, 0])
# 以下四行是固定套路
ax1.set_title(title)
ax1.scatter(x, y, s=5, marker='o', alpha=0.8)
ax1.set_xticks(())
ax1.set_yticks(())
n_components = model.get_params()['n_components'] plot_ellipses(ax1, model.weights_, model.means_, model.covariances_)
# ax1:画椭圆
# ax2:画权重
ax2 = plt.subplot(gs[2, 0])
ax2.get_xaxis().set_tick_params(direction='out')
ax2.yaxis.grid(True, alpha=0.7)
for k, w in enumerate(model.weights_):
ax2.bar(k, w, width=0.9, color='#56B4E9', zorder=3,
align='center', edgecolor='black')
ax2.text(k, w + 0.007, "%.1f%%" % (w * 100.),
horizontalalignment='center')
ax2.set_xlim(-.6, n_components - .4)
ax2.set_ylim(0., 1.1)
ax2.tick_params(axis='y', which='both', left='off',
right='off', labelleft='off')
ax2.tick_params(axis='x', which='both', top='off') if plot_title:
ax1.set_ylabel('Estimated Mixtures')
ax2.set_ylabel('Weight of each component')
查看拟合过程:
lower_bounds = []
mixture_model = BayesianGaussianMixture(
n_components =10,
covariance_type ='full',
max_iter =1,
random_state =2,
weight_concentration_prior_type ='dirichlet_distribution',
warm_start =True,
)
# 设置model.fit为只递归一次
for i in range(200):
mixture_model.fit(data)
if mixture_model.converged_: break
lower_bounds.append(mixture_model.lower_bound_)
if i%5==0 and i<60:
plt.figure();
plot_results(
mixture_model,
data['eruptions'], data['waiting'],
'EM step={}, lower_bound={}'.format(
i, mixture_model.lower_bound_)
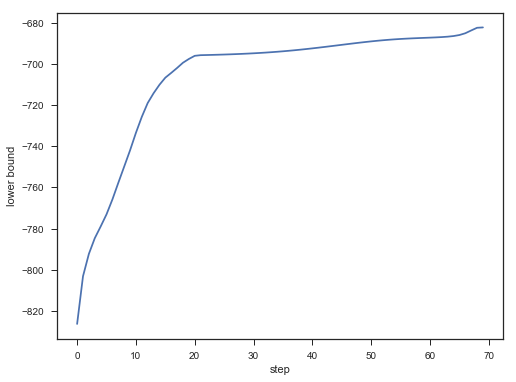
); plt.figure();
plt.plot(lower_bounds);
plt.gca().set_xlabel('step')
plt.gca().set_ylabel('lower bound')
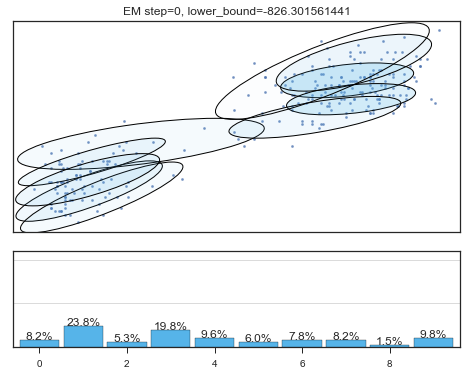
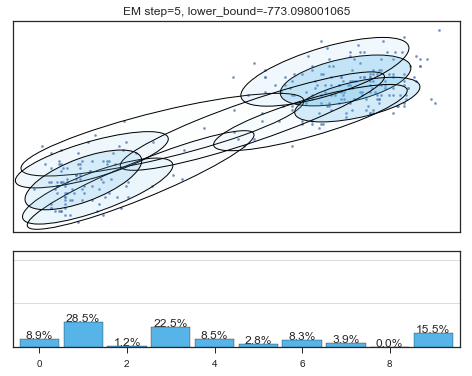
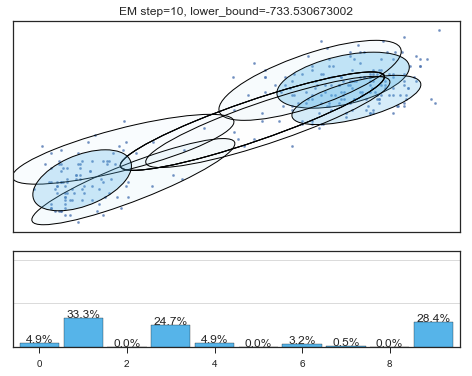
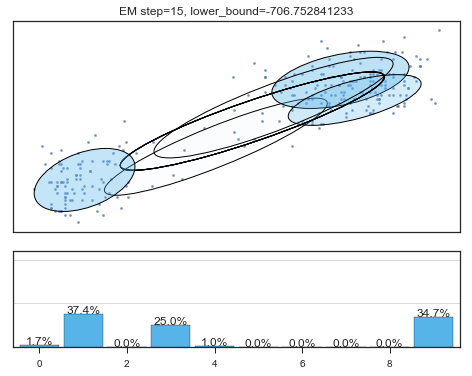
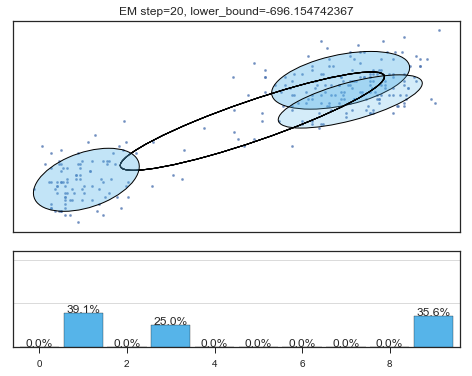
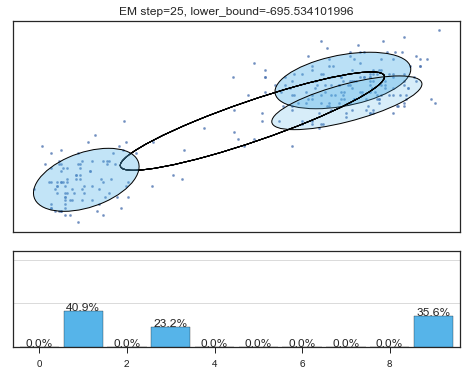
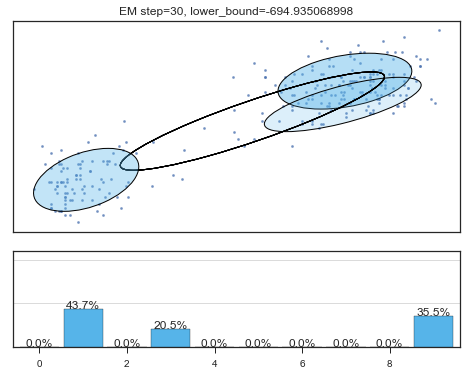
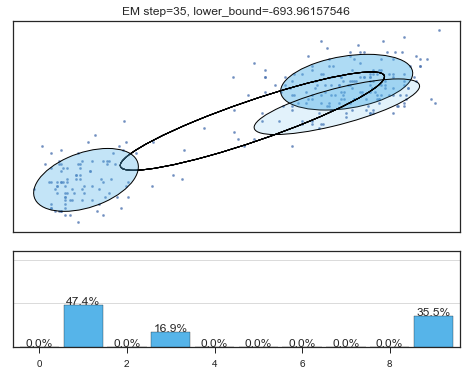
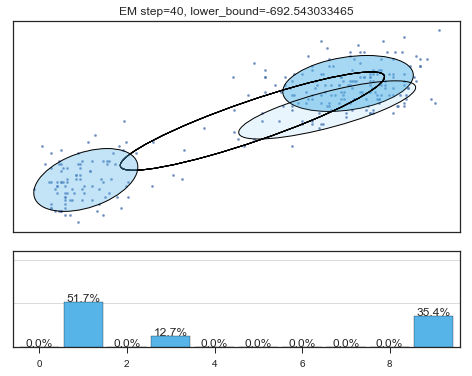

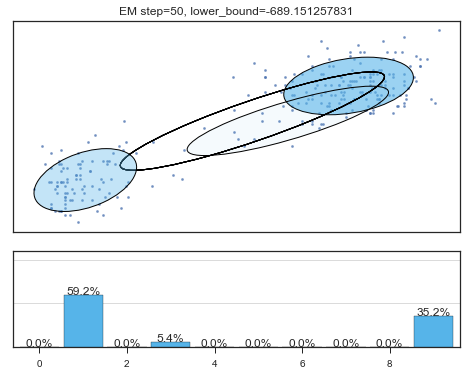
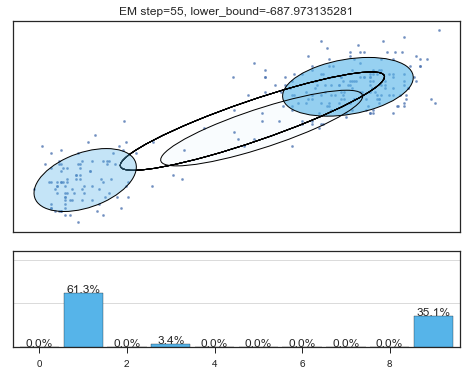
Lower bound 逐渐增加。
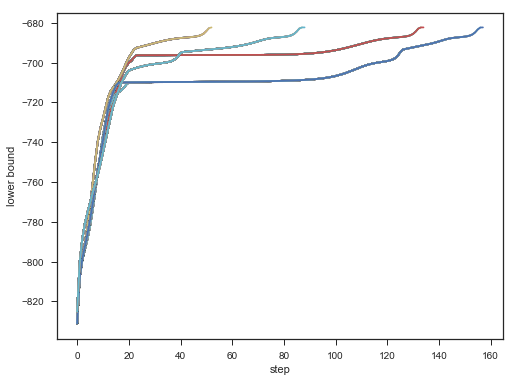
不同初始,效果对比:
for seed in range(6,11):
lower_bounds = []
mixture_model = BayesianGaussianMixture(
n_components=10,
covariance_type='full',
max_iter=1,
random_state=seed,
weight_concentration_prior_type='dirichlet_distribution',
warm_start=True,
)
for i in range(200):
mixture_model.fit(data)
if mixture_model.converged_: break
lower_bounds.append(mixture_model.lower_bound_)
plt.plot(lower_bounds);
plt.gca().set_xlabel('step')
plt.gca().set_ylabel('lower bound');
Result:
[Scikit-learn] 2.1 Clustering - Variational Bayesian Gaussian Mixture的更多相关文章
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- [Scikit-learn] 2.1 Clustering - Gaussian mixture models & EM
原理请观良心视频:机器学习课程 Expectation Maximisation Expectation-maximization is a well-founded statistical algo ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- 漫谈 Clustering (3): Gaussian Mixture Model
上一次我们谈到了用 k-means 进行聚类的方法,这次我们来说一下另一个很流行的算法:Gaussian Mixture Model (GMM).事实上,GMM 和 k-means 很像,不过 GMM ...
- [zz] 混合高斯模型 Gaussian Mixture Model
聚类(1)——混合高斯模型 Gaussian Mixture Model http://blog.csdn.net/jwh_bupt/article/details/7663885 聚类系列: 聚类( ...
随机推荐
- 利用angularJs自定义指令(directive)实现在页面某一部分内滑块随着滚动条上下滑动
最近老大让我一个效果实现在页面某一部分内滑块随着滚动条上下滑动,说明一下我们项目使用技术angularJs.大家都知道,使用jquery很好实现. 那么angular如何实现呢,我用的是自定义指令(d ...
- Server in ASP.NET-Core
.NET-Core Series Server in ASP.NET-Core DI in ASP.NET-Core Routing in ASP.NET-Core Error Handling in ...
- JAVA设计模式总结之六大设计原则
从今年的七月份开始学习设计模式到9月底,设计模式全部学完了,在学习期间,总共过了两篇:第一篇看完设计模式后,感觉只是脑子里面有印象但无法言语.于是决定在看一篇,到9月份第二篇设计模式总于看完了,这一篇 ...
- Spark官方1 ---------Spark SQL和DataFrame指南(1.5.0)
概述 Spark SQL是用于结构化数据处理的Spark模块.它提供了一个称为DataFrames的编程抽象,也可以作为分布式SQL查询引擎. Spark SQL也可用于从现有的Hive安装中读取数据 ...
- Twitter的分布式系统中ID生成方法——Snowflake
Twitter-Snowflake算法产生的背景相当简单,为了满足Twitter每秒上万条消息的请求,每条消息都必须分配一条唯一的id,这些id还需要一些大致的顺序(方便客户端排序),并且在分布式系统 ...
- bzoj1051(明星奶牛)
这道就是明星奶牛,A了一次又一次了,(⊙o⊙)-(⊙o⊙)- 去年pas就打了不下5次,就是强联通缩点,然后求出度为0的块 判断有多个的话就无解,一个就输出块的大小. #include<cstd ...
- 大数据开发 | MapReduce介绍
1. MapReduce 介绍 1.1MapReduce的作用 假设有一个计算文件中单词个数的需求,文件比较多也比较大,在单击运行的时候机器的内存受限,磁盘受限,运算能力受限,而一旦将单机版程序扩展 ...
- java远程备份mysql数据库关键问题(限windows环境,亲测解决)
其它环境同理也可解决. 条件:为了使用mysql命令,本机要安装mysql ,我本机安装的是mysql 5.5. 错误1:使用命令 mysqldump -h192.168.1.50 -u root - ...
- Python实战之IO多路复用select的详细简单练习
IO多路复用 I/O多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作. select 它通过一个select()系统调用来 ...
- Java面向对象 异常
Java面向对象 异常 知识概要: (1)异常的概述 (2)异常的体系 (3)异常的处理 ...