Hadoop(十二)MapReduce概述
前言
前面以前把关于HDFS集群的所有知识给讲解完了,接下来给大家分享的是MapReduce这个Hadoop的并行计算框架。
一、背景
1)爆炸性增长的Web规模数据量
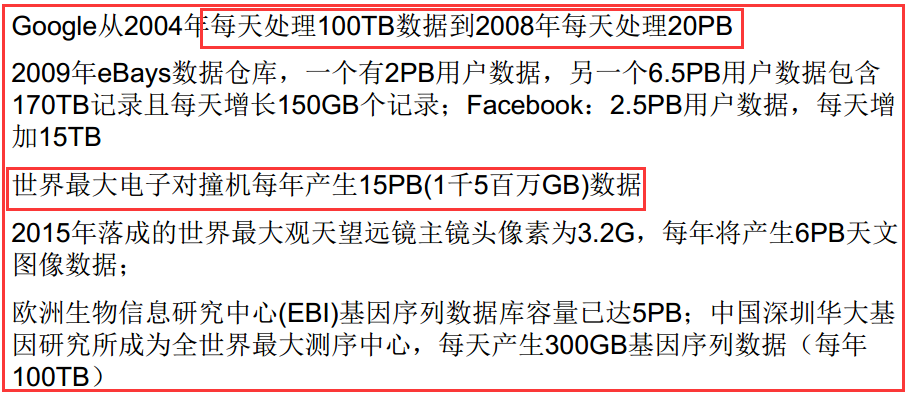
2)超大的计算量/计算复杂度

3)并行计算大趋所势

二、大数据的并行计算
1)一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度最好的办法就是并行计算。
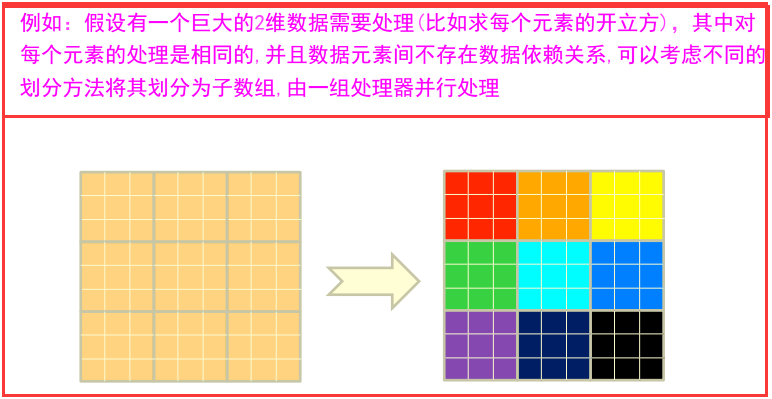
2)大数据并行计算
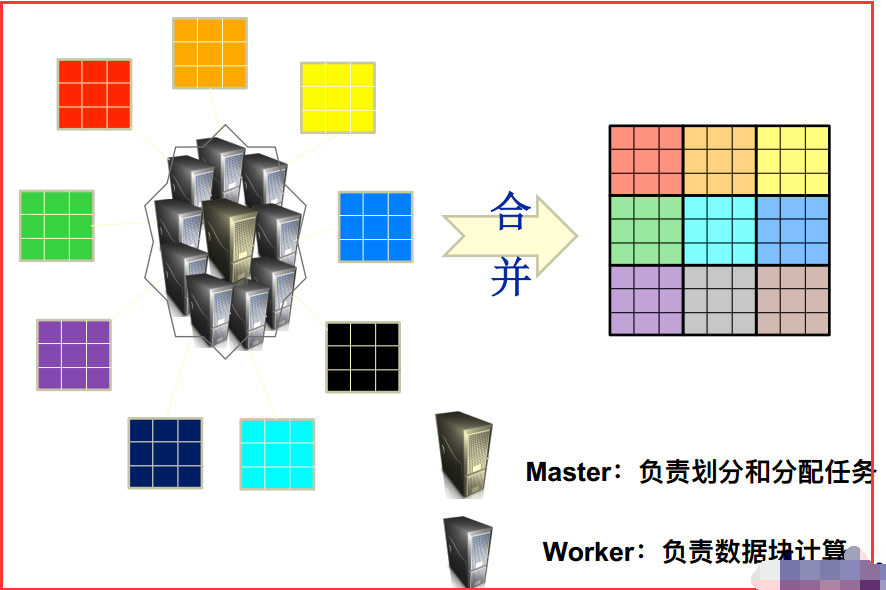
三、Hadoop的MapReduce概述
3.1、需要MapReduce原因

3.2、MapReduce简介
1)产生MapReduce背景

2)整体认识
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题。
MapReduce分成了两个部分:
1)映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
2)化简(Reducing)遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
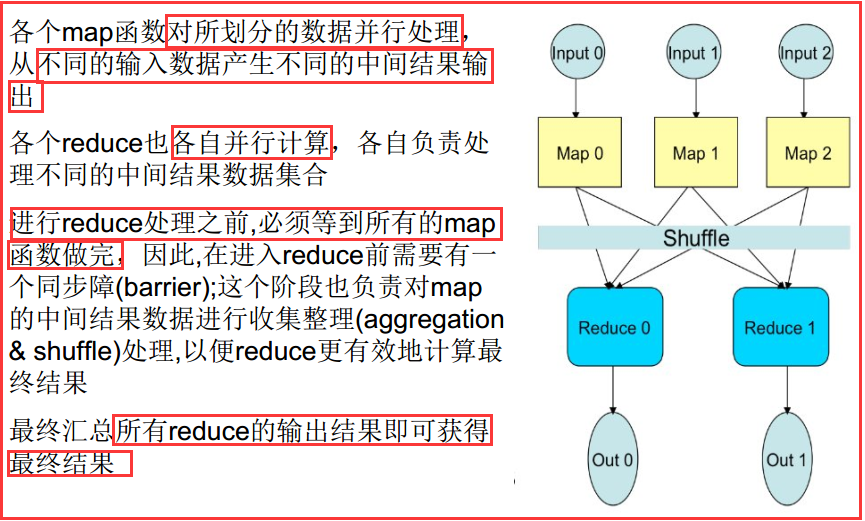
你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,
每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。
Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
MapReduce的伟大之处就在于编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
3.3、MapReduce编程模型
1)MapReduce借鉴了函数式程序设计语言Lisp中的思想,定义了如下的Map和Reduce两个抽象的编程接口。由用户去编程实现:

注意:Map是一行一行去处理数据的。
2)详细的处理过程
四、编写MapReduce程序
4.1、数据样式与环境
1)环境
我使用的是Maven,前面 有我配置的pom.xml文件。
2)数据样式
这是一个专利引用文件,格式是这样的:
专利ID:被引用专利ID
1,2
1,3
2,3
3,4
2,4
4.2、需求分析
1)需求
计算出被引用专利的次数
2)分析
从上面的数据分析出,我们需要的是一行数据中的后一个数据。分析一下:
在map函数中,输入端v1代表的是一行数据,输出端的k2可以代表是被引用的专利,在一行数据中所以v2可以被赋予为1。
在reduce函数中,k2还是被引用的专利,而[v2]是一个数据集,这里是将k2相同的键的v2数据合并起来。最后输出的是自己需要的数据k3代表的是被引用的专利,v3是引用的次数。
画图分析:

4.3、代码实现
1)编写一个解析类,用来解析数据文件中一行一行的数据。
import org.apache.hadoop.io.Text;
public class PatentRecordParser {
//1,2
//1,3
//2,3
//表示数据中的第一列
private String patentId;
//表示数据中的第二列
private String refPatentId;
//表示解析的当前行的数据是否有效
private boolean valid;
public void parse(String line){
String[] strs = line.split(",");
if (strs.length==){
patentId = strs[].trim();
refPatentId = strs[].trim();
if (patentId.length()>&&refPatentId.length()>){
valid = true;
}
}
}
public void parse(Text line){
parse(line.toString());
}
public String getPatentId() {
return patentId;
}
public void setPatentId(String patentId) {
this.patentId = patentId;
}
public String getRefPatentId() {
return refPatentId;
}
public void setRefPatentId(String refPatentId) {
this.refPatentId = refPatentId;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
}
2)编写PatentReference_0011去实现真正的计算
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.io.IOException; public class PatentReference_0011 extends Configured implements Tool { //-Dinput=/data/patent/cite75_99.txt
public static class PatentMapper
extends Mapper<LongWritable,Text,Text,IntWritable>{
private PatentRecordParser parser = new PatentRecordParser();
private Text key = new Text();
//把进入reduce的value都设置成1
private IntWritable value = new IntWritable(); //进入map端的数据,每次进入一行。
//MapReduce都是具有一定结构的数据,有一定含义的数据。
//进入时候map的k1(该行数据首个字符距离整个文档首个字符的距离),v1(这行数据的字符串)
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValid()){
this.key.set(parser.getRefPatentId());
context.write(this.key,this.value);
}
}
} public static class PatentReducer
extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = ;
for (IntWritable iw:values){
count+=iw.get();
}
context.write(key,new IntWritable(count));
//注意:在map或reduce上面的打印语句是没有办法输出的,但会记录到日志文件当中。
}
}
@Override
public int run(String[] args) throws Exception {
//构建作业所处理的数据的输入输出路径
Configuration conf = getConf();
Path input = new Path(conf.get("input"));
Path output = new Path(conf.get("output"));
//构建作业配置
Job job = Job.getInstance(conf,this.getClass().getSimpleName()+"Lance");//如果不指定取的名字就是当前类的类全名 //设置该作业所要执行的类
job.setJarByClass(this.getClass()); //设置自定义的Mapper类以及Map端数据输出时的类型
job.setMapperClass(PatentMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //设置自定义的Reducer类以及输出时的类型
job.setReducerClass(PatentReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //设置读取最原始数据的格式信息以及
//数据输出到HDFS集群中的格式信息
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); //设置数据读入和写出的路径到相关的Format类中
TextInputFormat.addInputPath(job,input);
TextOutputFormat.setOutputPath(job,output); //提交作业
return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception {
System.exit(
ToolRunner.run(new PatentReference_0011(),args)
);;
}
}
3)使用Maven打包好,上传到安装配置好集群客户端的Linux服务器中
4)运行测试

执行上面的语句,注意指定输出路径的时候,一定是集群中的路径并且目录要预先不存在,因为程序会自动去创建这个目录。
5)然后我们可以去Web控制页面去观察htttp://ip:8088去查看作业的进度
喜欢就点“推荐”哦!
Hadoop(十二)MapReduce概述的更多相关文章
- Hadoop MapReduce编程 API入门系列之多个Job迭代式MapReduce运行(十二)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- JAVA之旅(三十二)——JAVA网络请求,IP地址,TCP/UDP通讯协议概述,Socket,UDP传输,多线程UDP聊天应用
JAVA之旅(三十二)--JAVA网络请求,IP地址,TCP/UDP通讯协议概述,Socket,UDP传输,多线程UDP聊天应用 GUI写到一半电脑系统挂了,也就算了,最多GUI还有一个提示框和实例, ...
- JAVA之旅(二十二)——Map概述,子类对象特点,共性方法,keySet,entrySet,Map小练习
JAVA之旅(二十二)--Map概述,子类对象特点,共性方法,keySet,entrySet,Map小练习 继续坚持下去吧,各位骚年们! 事实上,我们的数据结构,只剩下这个Map的知识点了,平时开发中 ...
- Hadoop(二):MapReduce程序(Java)
Java版本程序开发过程主要包含三个步骤,一是map.reduce程序开发:第二是将程序编译成JAR包:第三使用Hadoop jar命令进行任务提交. 下面拿一个具体的例子进行说明,一个简单的词频统计 ...
- 我是如何一步步编码完成万仓网ERP系统的(十二)库存 1.概述
https://www.cnblogs.com/smh188/p/11533668.html(我是如何一步步编码完成万仓网ERP系统的(一)系统架构) https://www.cnblogs.com/ ...
- hadoop(二MapReduce)
hadoop(二MapReduce) 介绍 MapReduce:其实就是把数据分开处理后再将数据合在一起. Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理.可以进行拆分的前提是这 ...
- hadoop系列三:mapreduce的使用(一)
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/7224772.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的 ...
- Mapreduce概述和WordCount程序
一.Mapreduce概述 Mapreduce是分布式程序编程框架,也是分布式计算框架,它简化了开发! Mapreduce将用户编写的业务逻辑代码和自带默认组合整合成一个完整的分布式运算程序,并发的运 ...
随机推荐
- 网络配置之基本网络配置(cenos6)
目录: 关于IP的管理 Linux网卡的卸载与装载 配置网络接口 网络IP配置文件路由管理 路由管理命令 配置动态路由(简介) route的配置文件netstat命令IP命令 ip link 查看网络 ...
- OSGi-入门篇之生命周期层(03)
前言 生命周期层在OSGi框架中属于模块层上面的一层,它的运作是建立在模块层的功能之上的.生命周期层一个主要的功能就是让你能够从外部管理应用或者建立能够自我管理的应用(或者两者的结合),并且给了应用本 ...
- 来自projecteuler.net网站的练习题1
0.题目如下: By listing the first six prime numbers: 2, 3, 5, 7, 11, and 13, we can see that the 6th prim ...
- 极化码之tal-vardy算法(2)
上一节我们了解了tal-vardy算法的大致原理,对所要研究的二元输入无记忆对称信道进行了介绍,并着重介绍了能够避免输出爆炸灾难的合并操作,这一节我们来关注信道弱化与强化操作. [1]<Chan ...
- 系统学习java高并发系列三
转载请注明原创出处,谢谢! 首先需要说说线程安全?关于线程安全一直在提,比如StringBuilder和StringBuffer有什么区别? 经常就会出现关于线程安全与线程非安全,可能一直在提自己没有 ...
- 引入Log4j
1. pom文件添加依赖 <!-- log start --> <dependency> <groupId>log4j</groupId> <ar ...
- 【转】Spark运行过程
http://www.cnblogs.com/1130136248wlxk/articles/6289717.html
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
- 均值滤波去除图像噪声的matlab程序
所谓均值滤波实际上就是用均值替代原图像中的各个像素值. 均值滤波的方法是:对待处理的当前像素,选择一个模板,该模板为其近邻的若干像素组成,用模板中的像素的均值来替代原像素. 优点:算法简单,计算速度快 ...
- 关于如何更好地使用Github的一些建议
关于如何更好地使用Github的一些建议 原文(Github repository形式): https://github.com/Wasdns/github-example-repo 本文记录了我对于 ...