深度学习(一)cross-entropy softmax overfitting regularization dropout
一.Cross-entropy
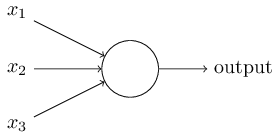
简单模型: 输入为1时, 输出为0
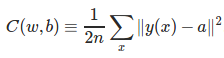
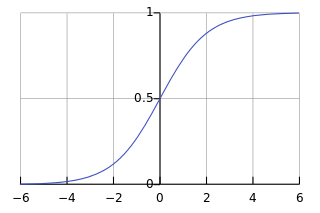
当神经元的输出接近1或0时,曲线很平缓,
因而会使偏导数 ∂C/∂w 和 ∂C/∂b 值小
学习很慢,如何增快学习?
因此神经网络引入交叉熵代价函数cross-entropy函数
是为了弥补 sigmoid 型函数的导数形式易发生饱和(saturate,梯度更新的较慢)的缺陷。
首先来看平方误差函数(squared-loss function),对于一个神经元(单输入单输出),定义其代价函数:
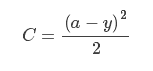
其中 a=σ(z),z=wx+b,然后根据对权值(w)和偏置(b)的偏导(为说明问题的需要,不妨将 x=1,y=0):
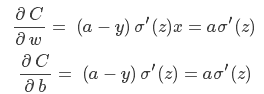
根据偏导计算权值和偏置的更新:
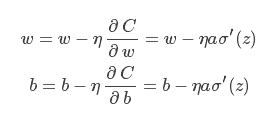
无论如何简化,sigmoid 型函数的导数形式 σ′(z) 始终阴魂不散,上文说了 σ′(z) 较容易达到饱和,这会严重降低参数更新的效率。
为了解决参数更新效率下降这一问题,我们使用交叉熵代价函数替换传统的平方误差函数。
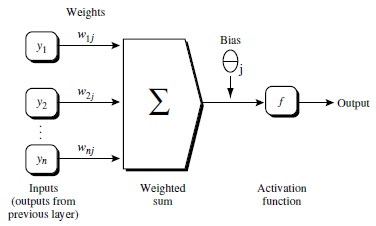
对于多输入单输出的神经元结构而言,如下图所示:

我们将其损失函数定义为:
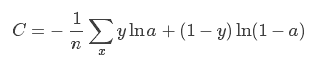
其中:
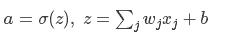
最终求导得:
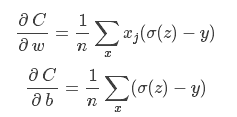
二.softmax和overfitting
另外一种类型的输出层函数:
第一步:和sigmoid一样
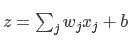
第二步:softmax函数
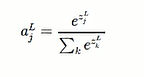
分母是将每层所有的神经元的输出值加起来
分子是指第L层第J个神经元的输出
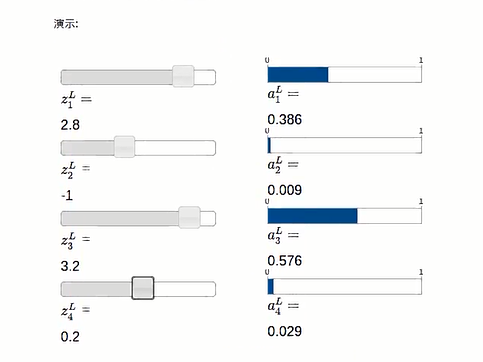
定义log-likelyhood函数
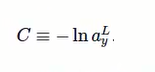
假设输入的是手写数字7的图片,输出比较确定接近7,对于对应的输出7的神经元,概率a接近1,对数C接近0,反之,对数C比较大,所有适合做Cost
是否存在学习慢的问题取决于:
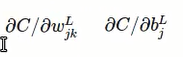
求偏导数,得到:
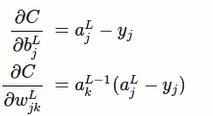
对比之前用的cross-entropy得到的偏导公式
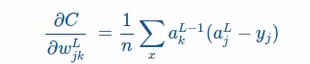 一样,除了之前是平均值
一样,除了之前是平均值
Overfitting
过度拟合
1)对于机器来说,在使用学习算法学习数据的特征的时候,样本数据的特征可以分为局部特征和全局特征,全局特征就是任何你想学习的那个概念所对应的数据都具备的特征,而局部特征则是你用来训练机器的样本里头的数据专有的特征.
(2)在学习算法的作用下,机器在学习过程中是无法区别局部特征和全局特征的,于是机器在完成学习后,除了学习到了数据的全局特征,也可能习得一部分局部特征,而习得的局部特征比重越多,那么新样本中不具有这些局部特征但具有所有全局特征的样本也越多,于是机器无法正确识别符合概念定义的“正确”样本的几率也会上升,也就是所谓的“泛化性”变差,这是过拟合会造成的最大问题.
(3)所谓过拟合,就是指把学习进行的太彻底,把样本数据的所有特征几乎都习得了,于是机器学到了过多的局部特征,过多的由于噪声带来的假特征,造成模型的“泛化性”和识别正确率几乎达到谷点,于是你用你的机器识别新的样本的时候会发现就没几个是正确识别的.
(4)解决过拟合的方法,其基本原理就是限制机器的学习,使机器学习特征时学得不那么彻底,因此这样就可以降低机器学到局部特征和错误特征的几率,使得识别正确率得到优化.
其实不完全是噪声和假规律会造成过拟合。
1)打个形象的比方,给一群天鹅让机器来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个“2”且略大于鸭子.这时候你的机器已经基本能区别天鹅和其他动物了。
(2)然后,很不巧你的天鹅全是白色的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅.
(3)好,来分析一下上面这个例子:(1)中的规律都是对的,所有的天鹅都有的特征,是全局特征;然而,(2)中的规律:天鹅的羽毛是白的.这实际上并不是所有天鹅都有的特征,只是局部样本的特征。机器在学习全局特征的同时,又学习了局部特征,这才导致了不能识别黑天鹅的情况.
三.正则化(regularization)
如何解决Overfitting?

增加一项:权重之和(对于神经网络里面所有权重W相加)
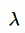 :regularization参数
:regularization参数
n :训练集实例的个数
对于二次Cost:
regularization 二次Cost:
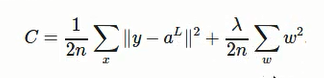
综上:可以概括表示为
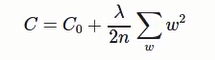
regularization的cost偏向神经网络学习比较小的权重W
:调整两项的相对重要程度, 较小的λ倾向于让第一项Co最小化. 较大的λ倾向与最小化增大的项(权重之和).

根据梯度下降算法,更新法则为:

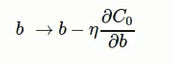

加入regularization不仅减小了overfitting, 还对避免陷入局部最小点 (local minimum), 更容易重现实验结果
为什么regularization可以减少overfitting?
L1 Regularization



2 Dropout


下面给出Dropout的Python代码:
注意:由于Dropout在训练的时候是用了一部分的神经元去做训练,在在测试阶段由于我们是用整个网络去训练,因此我们需要注意在训练的时候为每个存活下来的神经元做同采样比例的放大(除以p),注意,这只在训练时候做,用以保证训练得到的权重在组合之后不会太大;另外一种选择就是把测试结果根据采样比例缩小(乘于p)。
def dropout_forward(x, dropout_param):
"""
Performs the forward pass for (inverted) dropout.
Inputs:
- x: Input data, of any shape
- dropout_param: A dictionary with the following keys:
- p: Dropout parameter. We drop each neuron output with probability p.
- mode: 'test' or 'train'. If the mode is train, then perform dropout;
if the mode is test, then just return the input.
- seed: Seed for the random number generator. Passing seed makes this
function deterministic, which is needed for gradient checking but not in
real networks.
Outputs:
- out: Array of the same shape as x.
- cache: A tuple (dropout_param, mask). In training mode, mask is the dropout
mask that was used to multiply the input; in test mode, mask is None.
"""
p, mode = dropout_param['p'], dropout_param['mode']
if 'seed' in dropout_param:
np.random.seed(dropout_param['seed'])
mask = None
out = None
if mode == 'train':
mask = (np.random.rand(*x.shape) < p)/p
out = x*mask
pass
elif mode == 'test':
out = x*(np.random.rand(*x.shape) < p)/p
pass
cache = (dropout_param, mask)
out = out.astype(x.dtype, copy=False)
return out, cache
def dropout_backward(dout, cache):
"""
Perform the backward pass for (inverted) dropout.
Inputs:
- dout: Upstream derivatives, of any shape
- cache: (dropout_param, mask) from dropout_forward.
"""
dropout_param, mask = cache
mode = dropout_param['mode']
dx = None
if mode == 'train':
dx = dout * mask
pass
elif mode == 'test':
dx = dout
return dx
深度学习(一)cross-entropy softmax overfitting regularization dropout的更多相关文章
- Deep Learning 6_深度学习UFLDL教程:Softmax Regression_Exercise(斯坦福大学深度学习教程)
前言 练习内容:Exercise:Softmax Regression.完成MNIST手写数字数据库中手写数字的识别,即:用6万个已标注数据(即:6万张28*28的图像块(patches)),作训练数 ...
- 深度学习中 --- 解决过拟合问题(dropout, batchnormalization)
过拟合,在Tom M.Mitchell的<Machine Learning>中是如何定义的:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比 ...
- 深度学习(四) softmax函数
softmax函数 softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类! 假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素 ...
- Reading | 《TensorFlow:实战Google深度学习框架》
目录 三.TensorFlow入门 1. TensorFlow计算模型--计算图 I. 计算图的概念 II. 计算图的使用 2.TensorFlow数据类型--张量 I. 张量的概念 II. 张量的使 ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- 深度学习与CV教程(12) | 目标检测 (两阶段,R-CNN系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- Tensorflow2(一)深度学习基础和tf.keras
代码和其他资料在 github 一.tf.keras概述 首先利用tf.keras实现一个简单的线性回归,如 \(f(x) = ax + b\),其中 \(x\) 代表学历,\(f(x)\) 代表收入 ...
- softmax、cross entropy和softmax loss学习笔记
之前做手写数字识别时,接触到softmax网络,知道其是全连接层,但没有搞清楚它的实现方式,今天学习Alexnet网络,又接触到了softmax,果断仔细研究研究,有了softmax,损失函数自然不可 ...
- 最大似然估计 (Maximum Likelihood Estimation), 交叉熵 (Cross Entropy) 与深度神经网络
最近在看深度学习的"花书" (也就是Ian Goodfellow那本了),第五章机器学习基础部分的解释很精华,对比PRML少了很多复杂的推理,比较适合闲暇的时候翻开看看.今天准备写 ...
随机推荐
- SQL语句:Group By总结
1. Group By 语句简介: Group By语句从英文的字面意义上理解就是"根据(by)一定的规则进行分组(Group)".它的作用是通过一定的规则将一个数据集划分成若干个 ...
- 一篇文章学会Spring4.0
spring概述 spring 是一个开源框架. Spring 为简化企业级应用开发而生. 使用 Spring 可以使简单的 JavaBean 实现以前只有 EJB 才能实现的功能. Spring 是 ...
- Centos7.2 编译安装方式搭建 phpMyAdmin
1. 下载 编译 安装 pcre tar zxvf pcre-8.41.tar.gz cd pcre-8.41 ./configure --prefix=/opt/local/pcre-8.41 ma ...
- 再起航,我的学习笔记之JavaScript设计模式15(组合模式)
组合模式 组合模式(Composite): 又称部分-整体模式,将对象组合成树形结构以表示"部分整体"的层次结构.组合模式使得用户对单个对象和组合对象的使用具有一致性. 如果有一个 ...
- Eclipse知识
http://www.runoob.com/eclipse/eclipse-create-jar-files.html Eclipse 生成jar包 打开 Jar 文件向导 Jar 文件向导可用于将项 ...
- 现在开始学习WPF了,mongodb在整理一下
回忆一下自己学习mongodb的过程 1安装 2增删改查 3数据类型转换 4GridFS 5权限管理--开启权限之前先建立一个超级用户(admin库中),开启权限,用该用户登陆,进入admin数据库( ...
- [2013-03-14]使用wiki维护产品文档
word文档作为产品文档的问题: word文档本身的设计是为了打印: word文档的编辑较为繁琐: 作为产品文档的word文档往往长达百页以上,难以维护,且容易分散注意力,不利于查阅: 没有一个简单易 ...
- 模仿Spring实现注解注入
写这个极其蛋疼,我一直在想我们用SSM写项目时,写Service和Controller的时候,会给Service和Controller私有属性,比如Service需要dao,Controller需要S ...
- 打造基于Clang LibTooling的iOS自动打点系统CLAS(三)
1. 源码变换 第一章我们提到过,CLAS的本质是对源码做一次非常简单的变换(有些文章里称作变形),即Source-Source-Transformation,将打点代码精确地插入到目标函数的首部,保 ...
- Redis[三] @Hash 哈希
Redis的哈希值是字符串字段和字符串值之间的映射,所以他们是表示对象的完美数据类型 在Redis中的哈希值,可存储超过400十亿键值对. redis 提供了2套操纵 一种是批量 一种是非批量 假设需 ...