深度学习(四) softmax函数
softmax函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
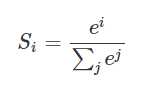
更形象的如下图表示:
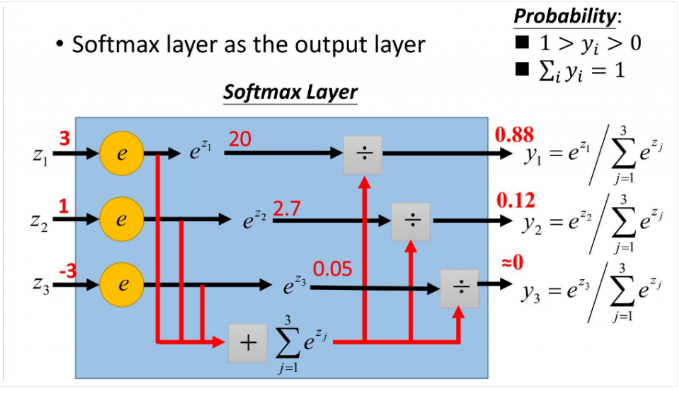
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
softmax相关求导
当我们对分类的Loss进行改进的时候,我们要通过梯度下降,每次优化一个step大小的梯度,这个时候我们就要求Loss对每个权重矩阵的偏导,然后应用链式法则。那么这个过程的第一步,就是对softmax求导传回去,不用着急,我后面会举例子非常详细的说明。在这个过程中,你会发现用了softmax函数之后,梯度求导过程非常非常方便!
下面我们举出一个简单例子,原理一样,目的是为了帮助大家容易理解!
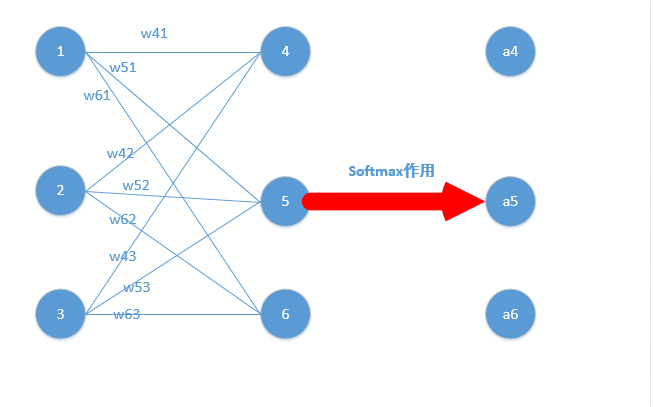
我们能得到下面公式:
z4 = w41*o1+w42*o2+w43*o3
z5 = w51*o1+w52*o2+w53*o3
z6 = w61*o1+w62*o2+w63*o3
z4,z5,z6分别代表结点4,5,6的输出,01,02,03代表是结点1,2,3往后传的输入.
那么我们可以经过softmax函数得到
好了,我们的重头戏来了,怎么根据求梯度,然后利用梯度下降方法更新梯度!
要使用梯度下降,肯定需要一个损失函数,这里我们使用交叉熵作为我们的损失函数,为什么使用交叉熵损失函数,不是这篇文章重点,后面有时间会单独写一下为什么要用到交叉熵函数(这里我们默认选取它作为损失函数)
交叉熵函数形式如下:
其中y代表我们的真实值,a代表我们softmax求出的值。i代表的是输出结点的标号!在上面例子,i就可以取值为4,5,6三个结点(当然我这里只是为了简单,真实应用中可能有很多结点)
现在看起来是不是感觉复杂了,居然还有累和,然后还要求导,每一个a都是softmax之后的形式!
但是实际上不是这样的,我们往往在真实中,如果只预测一个结果,那么在目标中只有一个结点的值为1,比如我认为在该状态下,我想要输出的是第四个动作(第四个结点),那么训练数据的输出就是a4 = 1,a5=0,a6=0,哎呀,这太好了,除了一个为1,其它都是0,那么所谓的求和符合,就是一个幌子,我可以去掉啦!
为了形式化说明,我这里认为训练数据的真实输出为第j个为1,其它均为0!
那么Loss就变成了,累和已经去掉了,太好了。现在我们要开始求导数了!
我们在整理一下上面公式,为了更加明白的看出相关变量的关系:
其中,那么形式变为
那么形式越来越简单了,求导分析如下:
参数的形式在该例子中,总共分为w41,w42,w43,w51,w52,w53,w61,w62,w63.这些,那么比如我要求出w41,w42,w43的偏导,就需要将Loss函数求偏导传到结点4,然后再利用链式法则继续求导即可,举个例子此时求w41的偏导为:
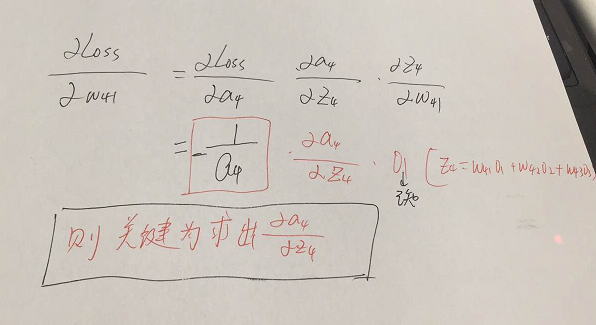
w51.....w63等参数的偏导同理可以求出,那么我们的关键就在于Loss函数对于结点4,5,6的偏导怎么求,如下:
这里分为俩种情况:
一:当选定的节点(我们要求误差项的节点)是我们期望的节点,则它的误差项为:
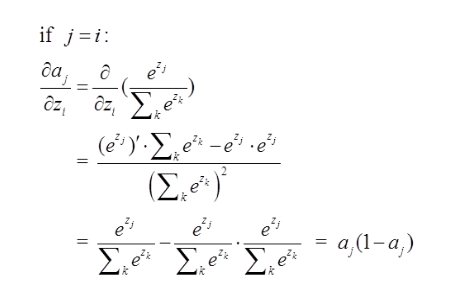
那么由上面求导结果再乘以交叉熵损失函数求导
,它的导数为
,与上面
相乘为
(形式非常简单,这说明我只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果减1即可,后面还会举例子!)那么我们可以得到Loss对于4结点的偏导就求出了了(这里假定4是我们的预计输出)
二:当节点不上真正的期望节点,则它的误差项(梯度)求法如下:
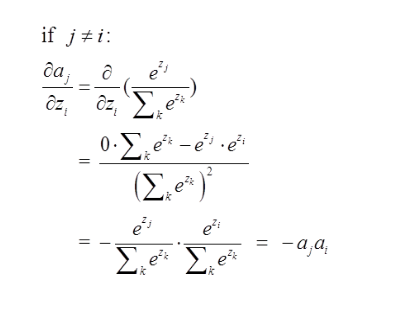
那么由上面求导结果再乘以交叉熵损失函数求导
,它的导数为
,与上面
相乘为
(形式非常简单,这说明我只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果保存即可,后续例子会讲到)这里就求出了除4之外的其它所有结点的偏导,然后利用链式法则继续传递过去即可!我们的问题也就解决了!
下面我举个例子来说明为什么计算会比较方便,给大家一个直观的理解
举个例子,通过若干层的计算,最后得到的某个训练样本的向量的分数是[ 2, 3, 4 ],
那么经过softmax函数作用后概率分别就是=[
,,
] = [0.0903,0.2447,0.665],如果这个样本正确的分类是第二个的话,那么计算出来的偏导就是[0.0903,0.2447-1,0.665]=[0.0903,-0.7553,0.665],是不是非常简单!!然后再根据这个进行back propagation就可以了。
深度学习(四) softmax函数的更多相关文章
- 从极大似然估计的角度理解深度学习中loss函数
从极大似然估计的角度理解深度学习中loss函数 为了理解这一概念,首先回顾下最大似然估计的概念: 最大似然估计常用于利用已知的样本结果,反推最有可能导致这一结果产生的参数值,往往模型结果已经确定,用于 ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 【深度学习】softmax回归——原理、one-hot编码、结构和运算、交叉熵损失
1. softmax回归是分类问题 回归(Regression)是用于预测某个值为"多少"的问题,如房屋的价格.患者住院的天数等. 分类(Classification)不是问&qu ...
- 深度学习之softmax回归
前言 以下内容是个人学习之后的感悟,转载请注明出处~ softmax回归 首先,我们看一下sigmod激活函数,如下图,它经常用于逻辑回归,将一个real value映射到(0, ...
- go微服务框架go-micro深度学习(四) rpc方法调用过程详解
上一篇帖子go微服务框架go-micro深度学习(三) Registry服务的注册和发现详细解释了go-micro是如何做服务注册和发现在,服务端注册server信息,client获取server的地 ...
- 深度学习TensorFlow常用函数
tensorflow常用函数 TensorFlow 将图形定义转换成分布式执行的操作, 以充分利用可用的计算资源(如 CPU 或 GPU.一般你不需要显式指定使用 CPU 还是 GPU, Tensor ...
- 深度学习四从循环神经网络入手学习LSTM及GRU
循环神经网络 简介 循环神经网络(Recurrent Neural Networks, RNN) 是一类用于处理序列数据的神经网络.之前的说的卷积神经网络是专门用于处理网格化数据(例如一个图像)的神经 ...
- 深度学习:Sigmoid函数与损失函数求导
1.sigmoid函数 sigmoid函数,也就是s型曲线函数,如下: 函数: 导数: 上面是我们常见的形式,虽然知道这样的形式,也知道计算流程,不够感觉并不太直观,下面来分析一下. 1.1 ...
- 深度学习中的batch_size,iterations,epochs等概念的理解
在自己完成的几个有关深度学习的Demo中,几乎都出现了batch_size,iterations,epochs这些字眼,刚开始我也没在意,觉得Demo能运行就OK了,但随着学习的深入,我就觉得不弄懂这 ...
- go微服务框架go-micro深度学习-目录
go微服务框架go-micro深度学习(一) 整体架构介绍 go微服务框架go-micro深度学习(二) 入门例子 go微服务框架go-micro深度学习(三) Registry服务的注册和发现 go ...
随机推荐
- Oracle EBS FND User Info API
1. 与用户信息相关API PKG. --和用户处理有关的API FND_USER_PKG; --和用户密码处理有关的API FND_WEB_SEC; --和用户职责处理有关的API ...
- Android-FileUtils-工具类
FileUtils-工具类 是对文件操作处理的方法进行了封装,提供了公共的方法: package common.library.utils; import android.annotation.Sup ...
- vs2015上使用github进行版本控制
我是用的是vs2015企业版 一.首先创建项目,右下角选择新建git存储库 二.在工具栏选择团队-管理连接,打开团队资源管理器,点击同步 . 三.选择下面的发布选项 四.在gitgub上新建仓库,得到 ...
- 10-12Linux流编程的一些知识点
第五章 Linux 的流编程 Linux流操作基础 流和文件的关系:流相当于一个缓冲区,可以将文件描述符和流关联,获得相应的缓冲区,以此来提高系统对磁盘的存取速度. 流的结构和操作 ...
- C# SM加密
using System; using System.Collections.Generic; using System.Linq; using System.Text; using Org.Boun ...
- Mycat SqlServer 技术栈 实现 主从分离
先说明下版本:SqlServer2008R2 + MyCat 1.6 现在主从分离 一主一从 用的是 代码 写死的方式 转换下思路 一主两从 或者多从 怎么实现 负载均衡 或者 按权重调用相应库呢 ...
- dockerfile 构建tomcat
事先下载好tomcat和jdk的二进制包. 下载地址https://pan.baidu.com/s/1kWWHGEV 值得一说的是 tomcat的官方镜像 剪切了很多jdk和系统命令,所以生产环境建议 ...
- Yaoge’s maximum profit HDU - 5052
Yaoge’s maximum profit Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/ ...
- P3357 最长k可重线段集问题 网络流
P3357 最长k可重线段集问题 题目描述 给定平面 x-O-yx−O−y 上 nn 个开线段组成的集合 II,和一个正整数 kk .试设计一个算法,从开线段集合 II 中选取出开线段集合 S\sub ...
- “全栈2019”Java第九十四章:局部内部类详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...