C#+HtmlAgilityPack—>糗事百科桌面版V2.0
最近在浏览以前自己上传的源码,发现在糗事百科桌面端源码评论区中,有人说现在程序不能用了。查看了一下源码运行情况,发现是正则表达式解析问题。由于糗百的网页版链接和网页格式稍有变化,导致解释失败。虽然可以通过更改正则表达,重新获网页的信息,但比较复杂,出错率较高(技术有限)。因此第二个版本采用HtmlAgilityPack类库解析Html。
1. HtmlAgilityPack类库
HtmlAgilityPack是一个解析Html文档的一个类库,当然也能够支持XML文件,该类库比.NET自带的XML解析库要方便灵活多,主要是HtmlAgilityPack支持XPath路径表达式,通过XPath表达式能够快速定位到文档中的某个节点。有了它,解析网页不成问题,接下来简述一下HtmlAgilityPack的使用方法。
HtmlAgilityPack 有3个比较重要的类型。
- HtmlDocument : 加载Html文档(string),并解析成有层次的对象结构。
- HtmlNode : 元素节点类型,该类型提供许多非常有用的方法,下面会将重点的方法都介绍一遍。
- HtmlNodeCollection : html节点集合类型。
通过例子来讲解这三个类型的使用,可能会更加的清晰,html源码,如下:
<div>
<div id="content" class="c1">
<p id="p1" class="pStyle" title="HtmlAgility">段落1</p>
<p id="p2" class= "pStyle">段落2</p>
</div>
<div id="content2" class="c1">
<p class="pStyle">段落3</p>
<span>
<h1>hello</h1>
<span>
<div>
</div>
使用HtmlDocument类型解析上面的html源码。
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(htmlStr);
HtmlNode rootNode = htmlDoc.DocumentNode;//获取文档的根节点
通过该类型的 LoadHtml 方法解析html字符串,然后获取html文档的根节点,当然该类型还有一个 Load方法,支持从文件中,url 或者流中加载html文档。获取了HtmlNode 类型的根节点之后,利用根节点与XPath路径表达可以获取文档中任意的节点。
获取所有class=pStyle的p节点
string xpath = "//p[@class='pStyle']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
利用HtmlNode类型的SelectNodes(xpath)方法可以获取所有class为pStyle的p标签。但是这次会把文档中所有的样式类为pStyle的p标签都获取到。如果只想获取“div id="content"”容器下面的。只需要更改xpath路径表达式即可做到。
string xpath = "//div[@id='content']/p[@class='pStyle']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
通过在之前的路径上加上div[@id='content']进行限定即可。如果只想找"div id="content"”容器下面的class=pStyle 且 title=HtmlAgility的p标签代码如下。
string xpath = @"//div[@id='content']/p[@class='pStyle' and @title='HtmlAgility']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
通过XPath可以很方便的定位到文档中的节点,并通过节点类型的属性或者方法来获取节点的属性值和文本值以及内部html。
获取节点的文本和class属性值,代码如下:
string xpath = @"//div[@id='content']/p[@class='pStyle' and @title='HtmlAgility']";
HtmlNodeCollection pNodes = rootNode.SelectNodes(xpath);
string nodeText=pNodes[0].InnerText;
string classValue = pNodes[0].GetAttributeValue("class", "");
HtmlNode类型的属性和方法如下:
InnerText : 节点的文本值
InnerHtml: 节点内部的html字符串
GetAttributeValue :通过节点的属性名字获取属性值,该方法有三个重载的版本,可以获取分别返回bool,string、int 三种类型的属性值。
上面都在简介HtmlAgilityPack类库的使用,下面简单介绍一下XPath。
- // 所有后代节点,从根部开始,跟SelectNodes方法前面的节点没关系 例子://div: 所有名为div的节点
- . 表示当前节点,与SelectNodes方法前面的节点相关 例子:./div :当前节点下的所有名为div节点
- .. 表示父节点,与SelectNodes方法前面的节点相关 例子: ../div :当前节点的父节点下的div节点
- @ 选取属性 例子://div/@id:所有包含id属性的div
XPath不仅仅可以通过路径定位,还可以对定位后的节点集做一些限制,使得选择更加精准。
- /root/book[1] 节点集中的第一个节点
- /root/book[last()] 节点集中最后一个节点
- /root/book[position() - 2] 节点集中倒数第三个节点集
- /root/book[position() < 5] 节点集中前五个节点集
- /root/book[@id] 节点集中含有属性id的节点集
- /root/book[@id='chinese'] 节点集中id属性值为chinese的节点集
- /root/book[price > 35]/title 节点集中book的price元素值大于35的title节点集
XPath对于路径匹配,谓语限制都可以使用通配符。
- /div/* div节点下面的所有节点类型
- //div[@*] div下面的所有属性
此外XPath还能进行逻辑运算
- | ——例:/root/book[1] | /root/book[3]:两个节点集的合并—— (
+,*) - //div[@id='test1' and @class='divStyle']—— 找寻所有 id=test1 和class=divStyle 的div节点
- //div[not(@class)]——找寻不包括class属性div节点
(or, and, not, =, !=, >, <, >=)
最后在提供一个小技巧,在网页中打开开发者工具,可以直接定位到相应的html节点,然后右键可以直接获取该节点在文档中的XPath路径,如下图:
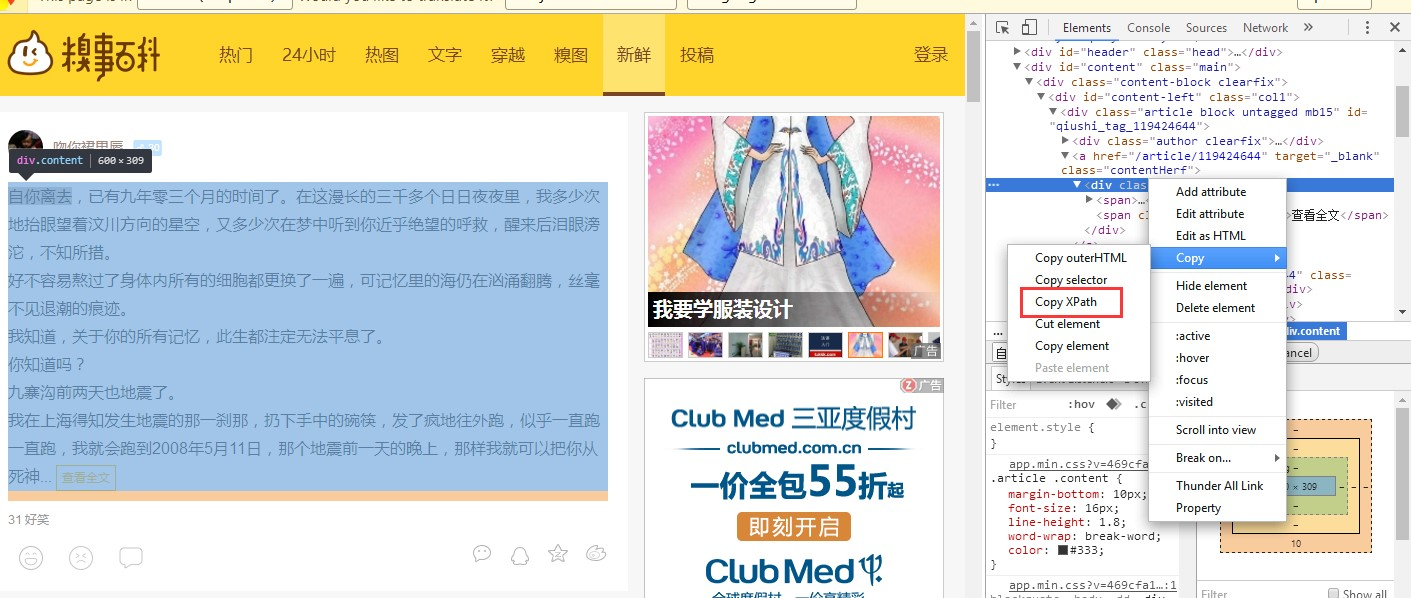
好了, HtmlAgilityPack类库的使用就介绍到这里。
2. 使用HtmlAgilityPack解析糗百
关于糗百的网页结构分析,在这篇文章使用HttpGet协议与正则表达实现桌面版的糗事百科 已经详细介绍了,在此就不在赘述了,下面简介一下抓取糗百段子的关键代码。
/// <summary>
/// 获取笑话列表
/// </summary>
/// <param name="htmlContent"></param>
public static List<JokeItem> GetJokeList(int pageIndex)
{
string htmlContent=GetUrlContent(GetWBJokeUrl(pageIndex));
List<JokeItem> jokeList = new List<JokeItem>();
HtmlDocument htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(htmlContent);
HtmlNode rootNode=htmlDoc.DocumentNode;
string xpathOfJokeDiv = "//div[@class='article block untagged mb15']";
string xpathOfJokeContent = "./a/div[@class='content']/span";
string xpathOfImg = "./div[@class='author clearfix']/a/img";
try
{
HtmlNodeCollection jokeCollection = rootNode.SelectNodes(xpathOfJokeDiv);
int jokeCount = jokeCollection.Count;
JokeItem joke;
foreach (HtmlNode jokeNode in jokeCollection)
{
joke = new JokeItem();
HtmlNode contentNode = jokeNode.SelectSingleNode(xpathOfJokeContent);
if (contentNode != null)
{
joke.JokeContent = Regex.Replace(contentNode.InnerText, "(\r\n)+", "\r\n");
}
else
{
joke.JokeContent = "";
}
HtmlNode imgornameNode = jokeNode.SelectSingleNode(xpathOfImg);
if (imgornameNode != null)
{
joke.NickName = imgornameNode.GetAttributeValue("alt", "");
joke.HeadImage = GetWebImage("http:"+imgornameNode.GetAttributeValue("src", ""));
joke.HeadImage = joke.HeadImage != null ? new Bitmap(joke.HeadImage, 50, 50) : null;
}
else
{
joke.NickName = "匿名用户";
joke.HeadImage = null;
}
jokeList.Add(joke);
}
}
catch{}
return jokeList;
}
下载图片的代码如下:
private static Image GetWebImage(string webUrl)
{
try
{
Encoding encode = Encoding.GetEncoding("utf-8");//网页编码==Encoding.UTF8
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(new Uri(webUrl));
HttpWebResponse ress = (HttpWebResponse)req.GetResponse();
Stream sstreamRes = ress.GetResponseStream();
return System.Drawing.Image.FromStream(sstreamRes);
}
catch { return null; }
}
需要注意的是:
获取糗百头像的地址为://pic.qiushibaike.com/system/avtnew/3281/32814675/medium/2017070317185381.JPEG" ,一定要在前面加上"http:" 才能正确的下载头像。
{kind=link}
效果如下:
3. 小结
通过HtmlAgilityPack来解析文档,很轻巧灵活,主要是不容易出错。觉得这个解析包和Python的Beautiful Soup 库有异曲同工之妙,都是解析网页的好工具。
本文的源码下载链接:https://github.com/StartAction/qbDesktop
C#+HtmlAgilityPack—>糗事百科桌面版V2.0的更多相关文章
- python_爬虫一之爬取糗事百科上的段子
目标 抓取糗事百科上的段子 实现每按一次回车显示一个段子 输入想要看的页数,按 'Q' 或者 'q' 退出 实现思路 目标网址:糗事百科 使用requests抓取页面 requests官方教程 使用 ...
- Python爬虫爬取糗事百科段子内容
参照网上的教程再做修改,抓取糗事百科段子(去除图片),详情见下面源码: #coding=utf-8#!/usr/bin/pythonimport urllibimport urllib2import ...
- 利用python的爬虫技术爬去糗事百科的段子
初次学习爬虫技术,在知乎上看了如何爬去糗事百科的段子,于是打算自己也做一个. 实现目标:1,爬取到糗事百科的段子 2,实现每次爬去一个段子,每按一次回车爬取到下一页 技术实现:基于python的实现, ...
- Python爬取糗事百科
import urllib import urllib.request from bs4 import BeautifulSoup """ 1.抓取糗事百科所有纯 ...
- Python爬虫(十七)_糗事百科案例
糗事百科实例 爬取糗事百科段子,假设页面的URL是: http://www.qiushibaike.com/8hr/page/1 要求: 使用requests获取页面信息,用XPath/re做数据提取 ...
- Python爬虫(十八)_多线程糗事百科案例
多线程糗事百科案例 案例要求参考上一个糗事百科单进程案例:http://www.cnblogs.com/miqi1992/p/8081929.html Queue(队列对象) Queue是python ...
- python3 爬虫---爬取糗事百科
这次爬取的网站是糗事百科,网址是:http://www.qiushibaike.com/hot/page/1 分析网址,参数''指的是页数,第二页就是'/page/2',以此类推... 一.分析网页 ...
- python 爬取糗事百科 gui小程序
前言:有时候无聊看一些搞笑的段子,糗事百科还是个不错的网站,所以就想用Python来玩一下.也比较简单,就写出来分享一下.嘿嘿 环境:Python 2.7 + win7 现在开始,打开糗事百科网站,先 ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
随机推荐
- ajax数据请求2(json格式)
ajax数据请求2(json格式) <!DOCTYPE html> <html> <head> <meta charset="UTF-8" ...
- 基于邮件系统的远程实时监控系统的实现 Python版
人生苦短,我用Python~ 界内的Python宣传标语,对Python而言,这是种标榜,实际上,Python确实是当下最好用的开发语言之一. 在相继学习了C++/C#/Java之后,接触Python ...
- iOS 实时录音和播放
需求:最近公司需要做一个楼宇对讲的功能:门口机(连接WIFI)拨号对室内机(对应的WIFI)的设备进行呼叫,室内机收到呼叫之后将对收到的数据进行UDP广播的转发,手机(连接对应的WIFI)收到视频流之 ...
- Django+MySQL开发项目:内容管理系统cms(一)
Baker-Miller Pink被科学方法证实可以平静情绪并且抑制食欲的颜色,具有amazing的效果.基百里面说实验结果表明该颜色具有: "a marked effect on lowe ...
- ubuntu主机名修改
1.查看主机名 在Ubuntu系统中,快速查看主机名有多种方法: 其一,打开一个GNOME终端窗口,在命令提示符中可以看到主机名,主机名通常位于"@"符号后: 其二,在终端窗口中输 ...
- 分享一次Oracle数据导入导出经历
最近工作上有一个任务要修改一个比较老的项目,分公司这边没有这个项目数据库相关的备份,所以需要从正式环境上面导出数据库备份出来在本地进行部署安装,之前在其它项目的时候也弄过这个数据库的部署和安装,也写了 ...
- Java自学手记——集合
- Javascript 判断变量类型的陷阱 与 正确的处理方式
Javascript 由于各种各样的原因,在判断一个变量的数据类型方面一直存在着一些问题,其中最典型的问题恐怕就是 typeof null 会返回 object 了吧.因此在这里简单的总结一下判断数据 ...
- My sql添加远程用户root密码为password
添加远程用户root密码为password grant all privileges on *.* to root@localhost identified by '123321' with gran ...
- 如何清除img图片下面有一片空白
最近在做项目突然发现用了img后有个空白区,如下图: 真的很影响美观,那么是什么原因造成的呢? 右键查看元素查看上下文的margin和padding也没有找到这个空白的来源. 只好上网看看别人是怎么说 ...