NEURAL NETWORKS, PART 3: THE NETWORK
NEURAL NETWORKS, PART 3: THE NETWORK
We have learned about individual neurons in the previous section, now it’s time to put them together to form an actual neural network.
The idea is quite simple – we line multiple neurons up to form a layer, and connect the output of the first layer to the input of the next layer. Here is an illustration:
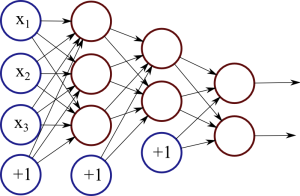 Figure 1: Neural network with two hidden layers.
Figure 1: Neural network with two hidden layers.
Each red circle in the diagram represents a neuron, and the blue circles represent fixed values. From left to right, there are four columns: the input layer, two hidden layers, and an output layer. The output from neurons in the previous layer is directed into the input of each of the neurons in the next layer.
We have 3 features (vector space dimensions) in the input layer that we use for learning: x1, x2 and x3. The first hidden layer has 3 neurons, the second one has 2 neurons, and the output layer has 2 output values. The size of these layers is up to you – on complex real-world problems we would use hundreds or thousands of neurons in each layer.
The number of neurons in the output layer depends on the task. For example, if we have a binary classification task (something is true or false), we would only have one neuron. But if we have a large number of possible classes to choose from, our network can have a separate output neuron for each class.
The network in Figure 1 is a deep neural network, meaning that it has two or more hidden layers, allowing the network to learn more complicated patterns. Each neuron in the first hidden layer receives the input signals and learns some pattern or regularity. The second hidden layer, in turn, receives input from these patterns from the first layer, allowing it to learn “patterns of patterns” and higher-level regularities. However, the cost of adding more layers is increased complexity and possibly lower generalisation capability, so finding the right network structure is important.
Implementation
I have implemented a very simple neural network for demonstration. You can find the code here: SimpleNeuralNetwork.java
The first important method is initialiseNetwork(), which sets up the necessary structures:
|
1
2
3
4
5
6
7
8
9
|
public void initialiseNetwork(){ input = new double[1 + M]; // 1 is for the bias hidden = new double[1 + H]; weights1 = new double[1 + M][H]; weights2 = new double[1 + H]; input[0] = 1.0; // Setting the bias hidden[0] = 1.0;} |
M is the number of features in the feature vectors, H is the number of neurons in the hidden layer. We add 1 to these, since we also use the bias constants.
We represent the input and hidden layer as arrays of doubles. For example, hidden[i] stores the current output value of the i-th neuron in the hidden layer.
The first set of weights, between the input and hidden layer, are stored as a matrix. Each of the (1+M) neurons in the input layer connects to H neurons in the hidden layer, leading to a total of (1+M)×H weights. We only have one output neuron, so the second set of weights between hidden and output layers is technically a (1+H)×1 matrix, but we can just represent that as a vector.
The second important function is forwardPass(), which takes an input vector and performs the computation to reach an output value.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public void forwardPass(){ for(int j = 1; j < hidden.length; j++){ hidden[j] = 0.0; for(int i = 0; i < input.length; i++){ hidden[j] += input[i] * weights1[i][j-1]; } hidden[j] = sigmoid(hidden[j]); } output = 0.0; for(int i = 0; i < hidden.length; i++){ output += hidden[i] * weights2[i]; } output = sigmoid(output);} |
The first for-loop calculates the values in the hidden layer, by multiplying the input vector with the weight vector and applying the sigmoid function. The last part calculates the output value by multiplying the hidden values with the second set of weights, and also applying the sigmoid.
Evaluation
To test out this network, I have created a sample dataset using the database at quandl.com. This dataset contains sociodemographic statistics for 141 countries:
- Population density (per suqare km)
- Population growth rate (%)
- Urban population (%)
- Life expectancy at birth (years)
- Fertility rate (births per woman)
- Infant mortality (deaths per 1000 births)
- Enrolment in tertiary education (%)
- Unemployment (%)
- Estimated control of corruption (score)
- Estimated government effectiveness (score)
- Internet users (per 100)
Based on this information, we want to train a neural network that can predict whether the GDP per capita is more than average for that country (label 1 if it is, 0 if it’s not).
I’ve separated the dataset for training (121 countries) and testing (40 countries). The values have been normalised, by subtracting the mean and dividing by the standard deviation, using a script from a previous article. I’ve also pre-trained a model that we can load into this network and evaluate. You can download these from here: original data, training data, test data,pretrained model.
You can then execute the neural network (remember to compile and link the binaries):
|
1
|
java neuralnet.SimpleNeuralNetwork data/model.txt data/countries-classify-gdp-normalised.test.txt |
The output should be something like this:
|
1
2
3
4
5
6
7
8
9
10
|
Label: 0 Prediction: 0.01Label: 0 Prediction: 0.00Label: 1 Prediction: 0.99Label: 0 Prediction: 0.00...Label: 0 Prediction: 0.20Label: 0 Prediction: 0.01Label: 1 Prediction: 0.99Label: 0 Prediction: 0.00Accuracy: 0.9 |
The network is in verbose mode, so it prints out the labels and predictions for each test item. At the end, it also prints out the overall accuracy. The test data contains 14 positive and 26 negative examples; a random system would have had accuracy 50%, whereas a biased system would have accuracy 65%. Our network managed 90%, which means it has learned some useful patterns in the data.
In this case we simply loaded a pre-trained model. In the next section, I will describe how to learn this model from some training data.
NEURAL NETWORKS, PART 3: THE NETWORK的更多相关文章
- 神经网络第三部分:网络Neural Networks, Part 3: The Network
NEURAL NETWORKS, PART 3: THE NETWORK We have learned about individual neurons in the previous sectio ...
- [C3] Andrew Ng - Neural Networks and Deep Learning
About this Course If you want to break into cutting-edge AI, this course will help you do so. Deep l ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- 课程一(Neural Networks and Deep Learning),第四周(Deep Neural Networks) —— 3.Programming Assignments: Deep Neural Network - Application
Deep Neural Network - Application Congratulations! Welcome to the fourth programming exercise of the ...
- 课程一(Neural Networks and Deep Learning),第二周(Basics of Neural Network programming)—— 4、Logistic Regression with a Neural Network mindset
Logistic Regression with a Neural Network mindset Welcome to the first (required) programming exerci ...
- 【转】Artificial Neurons and Single-Layer Neural Networks
原文:written by Sebastian Raschka on March 14, 2015 中文版译文:伯乐在线 - atmanic 翻译,toolate 校稿 This article of ...
- Deep Learning 23:dropout理解_之读论文“Improving neural networks by preventing co-adaptation of feature detectors”
理论知识:Deep learning:四十一(Dropout简单理解).深度学习(二十二)Dropout浅层理解与实现.“Improving neural networks by preventing ...
- 一天一经典Reducing the Dimensionality of Data with Neural Networks [Science2006]
别看本文没有几页纸,本着把经典的文多读几遍的想法,把它彩印出来看,没想到效果很好,比在屏幕上看着舒服.若用蓝色的笔圈出重点,这篇文章中几乎要全蓝.字字珠玑. Reducing the Dimensio ...
- Stanford机器学习笔记-5.神经网络Neural Networks (part two)
5 Neural Networks (part two) content: 5 Neural Networks (part two) 5.1 cost function 5.2 Back Propag ...
随机推荐
- 基于windows的ngnix基础使用
前言 今天组长一大早心血来潮的跟我说,我希望我们小组电脑做web站点的服务器集群,你搞一搞,就用ngnix吧. 君要臣死,臣不得不死.顺便写个文章做个笔记. 简介 Nginx 是一个高性能的HTTP和 ...
- ngnix apache tomcat集群负载均衡配置
http://w.gdu.me/wiki/Java/tomcat_cluster.html 参考: Tomcat与Apache或Nginx的集群负载均衡设置: http://huangrs.blog. ...
- hadoop错误INFO util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
报如下错误: 解决方法: 1.增加调试信息 在HADOOP_HOME/etc/hadoop/hadoop-env.sh文件中添加如下信息 2.再执行一次操作,看看报什么错误 上面信息显示,需要2.14 ...
- react native web
http://rawgit.com/taobaofed/react-web/master/pages/uiexplorer.html#/scene_1?_k=7vm99j
- Android(java)学习笔记172:BroadcastReceiver之 Android广播机制
Android广播机制 android系统中有各式各样的广播,各种广播在Android系统中运行,当"系统/应用"程序运行时便会向Android注册各种广播.Android接收到广 ...
- Linux同步时间命令ntpdate
转自:http://orgcent.com/linux-ntpdate/ 由于要同步Linux服务器的时间,为了保证时间的高度准确性,放弃date命令而转向ntpdate(同步时间命令). 方案如下: ...
- MyBatis的学习总结三:优化MyBatis配置文件中的配置
一.优化Mybatis配置文件conf.xml中数据库的信息 1.添加properties的配置文件,存放数据库的信息:mysql.properties具体代码: driver=com.mysql.j ...
- Angularjs总结(二)过滤器使用
html页面: <table> <thead> <tr> <td class="td">序号</td> <td c ...
- iOS中打印系统详细日志
Q:如何打印当前的函数和行号? A:我们可以在打印时使用一些预编译宏作为打印参数,来打印当前的函数和行号.如: 1 NSLog(@"%s:%d obj=%@", __func__, ...
- Object-C — KVO & oc通知
键值观察(KVO)是基于键值编码的一种技术. 利用键值观察可以注册成为一个对象的观察者,在该对象的某个属性变化时收到通知. 被观察对象需要编写符合KVC标准的存取方法,编写键值观察分为以下三步: (1 ...