java从pdf中提取文本
一(单文件转换):下载pdfbox包,百度搜pdfbox.(fontbox-1.8.16.jar和pdfbox-app-1.8.16.jar)
package pdf; import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter; import org.apache.pdfbox.pdfparser.PDFParser;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFTextStripper; /**
*
* @author 大汉
*
*/
public class PdfToTxt { public PdfToTxt() {
super();
// TODO Auto-generated constructor stub
} /**
*
* @param filename
* @return
* @throws Exception
*/
public String GetTextFromPdf(String filename) throws Exception { String content = null;
PDDocument pdfdocument = null; FileInputStream is = new FileInputStream(filename);
PDFParser parser = new PDFParser(is); parser.parse();
pdfdocument = parser.getPDDocument();
PDFTextStripper stripper = new PDFTextStripper();
content = stripper.getText(pdfdocument);
return content;
} /**
*
* @param args
*/
public static void main(String[] args) {
PdfToTxt pdfToTxt = new PdfToTxt();
try {
//获取pdf文件路径
String pdf = pdfToTxt.GetTextFromPdf("E:/2019a.pdf");
//输出到txt文件
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("E:/aa.txt"));
osw.write(pdf);
osw.flush();
osw.close();
}catch (Exception e){
e.printStackTrace();
} } }
还可以这样:(第二种方法)
package pdf; import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
import java.net.MalformedURLException;
import java.net.URL; import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFTextStripper; /**
* 批量转换
* @author 大汉
*
*/
public class BatchPdfToTxt { public BatchPdfToTxt() {
super();
// TODO Auto-generated constructor stub
} public static void readPdf(String file) throws Exception {
// 是否排序
boolean sort = false;
// pdf文件名
String pdfFile = file;
// 输入文本文件名称
String textFile = null;
// 编码方式
String encoding = "UTF-8";
// 开始提取页数
int startPage = 1;
// 结束提取页数
int endPage = Integer.MAX_VALUE;
// 文件输入流,生成文本文件
Writer output = null;
// 内存中存储的PDF Document
PDDocument document = null;
try {
try {
// 首先当作一个URL来装载文件,如果得到异常再从本地文件系统//去装载文件
URL url = new URL(pdfFile);
//注意参数已不是以前版本中的URL.而是File。
document = PDDocument.load(pdfFile);
// 获取PDF的文件名
String fileName = url.getFile();
// 以原来PDF的名称来命名新产生的txt文件
if (fileName.length() > 4) {
File outputFile = new File(fileName.substring(0, fileName.length() - 4)+ ".txt");
textFile ="E:/"+outputFile.getName();
}
} catch (MalformedURLException e) {
// 如果作为URL装载得到异常则从文件系统装载
//注意参数已不是以前版本中的URL.而是File。
document = PDDocument.load(pdfFile);
if (pdfFile.length() > 4) {
textFile = pdfFile.substring(0, pdfFile.length() - 4)+ ".txt";
}
}
// 文件输入流,写入文件倒textFile
output = new OutputStreamWriter(new FileOutputStream(textFile),encoding);
// PDFTextStripper来提取文本
PDFTextStripper stripper = null;
stripper = new PDFTextStripper();
// 设置是否排序
stripper.setSortByPosition(sort);
// 设置起始页
stripper.setStartPage(startPage);
// 设置结束页
stripper.setEndPage(endPage);
// 调用PDFTextStripper的writeText提取并输出文本
stripper.writeText(document, output); System.out.println(textFile + " 输出成功!");
} finally {
if (output != null) {
// 关闭输出流
output.close();
}
if (document != null) {
// 关闭PDF Document
document.close();
}
}
}
/**
*
* @param args
*/
public static void main(String[] args) {
try {
//注意此处的绝对地址格式,最好要用这一种。
readPdf("E:/用户行为排序算法.pdf");
} catch (Exception e) {
e.printStackTrace();
}
}
}
效果图:
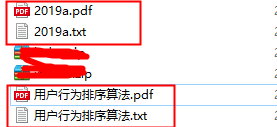

總結:唯一的缺點是不能顯示圖片,請看下一篇:----------------------->>>>>>>>PDF转WORD.
java从pdf中提取文本的更多相关文章
- Java 读取PDF中的文本和图片
本文将介绍通过Java程序来读取PDF文档中的文本和图片的方法.分别调用方法extractText()和extractImages()来读取. 使用工具:Free Spire.PDF for Ja ...
- Java 设置PDF中的文本旋转、倾斜
本文介绍通过Java程序在PDF文档中设置文本旋转.倾斜的方法.设置文本倾斜时,通过定义方法TransformText(page);并设置page.getCanvas().skewTransform( ...
- 用PDFMiner从PDF中提取文本文字
1.下载并安装PDFMiner 从https://pypi.python.org/pypi/pdfminer/下载PDFMineer wget https://pypi.python.org/pack ...
- Java 在PDF中添加水印——文本/图片水印
水印是一种十分常用的防伪手段,常用于各种文档.资料等.常见的水印,包括文字类型的水印.图片或logo类型的水印.以下Java示例,将分别使用insertTextWatermark(PdfPageBas ...
- 如何使用免费PDF控件从PDF文档中提取文本和图片
如何使用免费PDF控件从PDF文档中提取文本和图片 概要 现在手头的项目有一个需求是从PDF文档中提取文本和图片,我以前也使用过像iTextSharp, PDFBox 这些免费的PD ...
- java itext替换PDF中的文本
itext没有提供直接替换PDF文本的接口,我们可以通过在原有的文本区域覆盖一个遮挡层,再在上面加上文本来实现. 所需jar包: 1.先在PDF需要替换的位置覆盖一个白色遮挡层(颜色可根据PDF文字背 ...
- 利用java从docx文档中提取文本内容
利用java从docx文档中提取文本内容 使用Apache的第三方jar包,地址为https://poi.apache.org/ docx文档内容如图: 目录结构: 每个文件夹的名称为日期加上来源,例 ...
- 从PDF中提取信息----PDFMiner
今天由于某种原因需要将pdf中的文本提取出来,就去搜了下资料,发现PDFMiner是针对 内容提取的,虽然最后发现pdf里面的文本全都是图片,就没整成功,不过试了个文本可复制的 那种pdf文件,发现还 ...
- C# 设置或验证 PDF中的文本域格式
概述 PDF中的文本域可以通过设置不同格式,用于显示数字.货币.日期.时间.邮政编码.电话号码和社保号等等.Adobe Acrobat提供了许多固定的JavaScripts用来设置和验证文本域的格式, ...
随机推荐
- SkyReach 团队团队展示
班级:软件工程1916|W 作业:团队作业第一次-团队展示 团队名称:SkyReach 目标:展示团队风采,磨合团队 队员姓名与学号 队员学号 队员姓名 个人博客地址 备注 221600107 陈某某 ...
- Python爬虫基础之Cookie
一.Cookie会话 简单地说,cookie就是存储在用户浏览器中的一小段文本文件.Cookies是纯文本形式,它们不包含任何可执行代码.一个Web页面或服务器告之浏览器来将这些信息存储并且基于一系列 ...
- maven父子模块deploy 问题
1.问题描述:直接 deploy 子某块,但第三者确不能引用 jar(jar down不下来,但pom不报错) 原因:父子模块项目必须保证父模块pom deploy后,再 deploy 子模块才能被引 ...
- python vs C++ 类
1. 什么是动态语言(wikipedia) 在运行时,可以进行一些操作(静态语言在编译时执行),比如扩展对象的定义.修改类型等 2. 定义类和创建对象 C++ python class A{ publ ...
- 对于JavaBean+Servlet+SqlServer的代码总结和打包调用
日期:2019.3.24 博客期:049 星期日 说起来我已经说过很多次前台的应用技术了呢!这一次我是要将这一部分打包,做成配套的制作工具: 当前我已经打包成功,想要下载的同学可以进入我的GitHub ...
- spring5.0.2.RELEASE源码环境构建
Spring5 源码下载注意事项 首先你的JDK 需要升级到1.8 以上.Spring3.0 开始,Spring 源码采用github 托管,不再提供官网下载链接.大家可自行去github 网站下载, ...
- js |竖线字符串全部替换 replace
一般人解决方案: 'a|b|c'.replace(/\|/g, ','); 神经病解决方案: 'a|b|c'.split('|').join(',');
- php 通过curl header传值
下面是自己整理的通过curl header传值 方式是post $url = 'http://www.***.com';//此处为传值需要访问的地址 $header = array('token:J ...
- 禁止Centos7系统yum自动下载更新
安装Centos7后,系统自动更新状态默认为开启,若禁止系统自动更新需要手动关闭. 1.进入yum目录 [root@localhost ~]$ cd /etc/yum 2.编辑yum-cron.co ...
- Go之十大经典排序算法
1.冒泡排序 func bubble_sort(li []int) { for i := 0; i < len(li)-1; i++ { exchange := false for j := 0 ...