用PDFMiner从PDF中提取文本文字
1、下载并安装PDFMiner
从https://pypi.python.org/pypi/pdfminer/下载PDFMineer
wget https://pypi.python.org/packages/57/4f/e1df0437858188d2d36466a7bb89aa024d252bd0b7e3ba90cbc567c6c0b8/pdfminer-20140328.tar.gz#md5=dfe3eb1b7b7017ab514aad6751a7c2ea
加压并安装
tar -zxvf pdfminer-.tar.gz
cd pdfminer-/
make cmap #防止中文乱码,否则处理中文会出现一大堆(CID:xxx)
sudo python setup.py install
2、提取文本文字
from cStringIO import StringIO
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
import sys
import string def convert_pdf_2_text(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec='utf-8', laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
with open(path, 'rb') as fp:
for page in PDFPage.get_pages(fp, set()):
interpreter.process_page(page)
text = retstr.getvalue()
device.close()
retstr.close()
return text text = convert_pdf_2_text(sys.argv[1])
open('real?.txt','wb').write(text)
3、测试结果
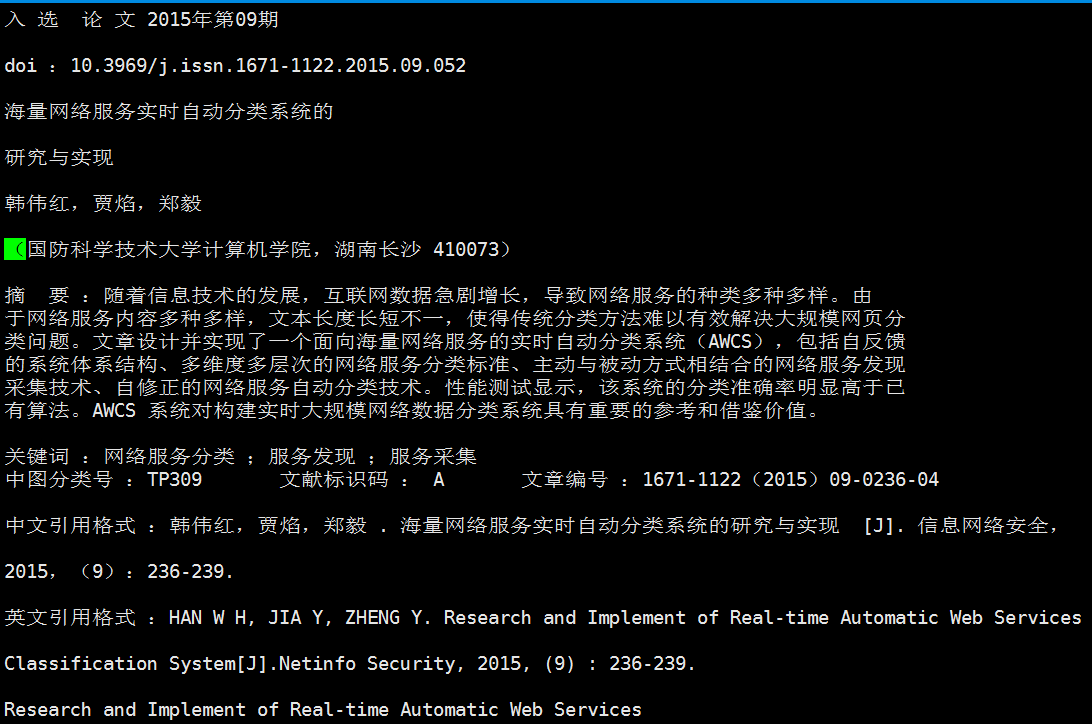
【1】http://www.unixuser.org/~euske/python/pdfminer/#source
【2】https://www.zhihu.com/question/31586273
用PDFMiner从PDF中提取文本文字的更多相关文章
- java从pdf中提取文本
一(单文件转换):下载pdfbox包,百度搜pdfbox.(fontbox-1.8.16.jar和pdfbox-app-1.8.16.jar) package pdf; import java.io. ...
- 从PDF中提取信息----PDFMiner
今天由于某种原因需要将pdf中的文本提取出来,就去搜了下资料,发现PDFMiner是针对 内容提取的,虽然最后发现pdf里面的文本全都是图片,就没整成功,不过试了个文本可复制的 那种pdf文件,发现还 ...
- 如何使用免费PDF控件从PDF文档中提取文本和图片
如何使用免费PDF控件从PDF文档中提取文本和图片 概要 现在手头的项目有一个需求是从PDF文档中提取文本和图片,我以前也使用过像iTextSharp, PDFBox 这些免费的PD ...
- 在线提取PDF中图片和文字
无需下载软件,你就可以在线提取PDF中图片和文字,http://www.extractpdf.com/不仅可以获取本地PDF文档的图片和文字,还能获取远程PDF文档的图片和文字.如下图所示:结果本人测 ...
- java itext替换PDF中的文本
itext没有提供直接替换PDF文本的接口,我们可以通过在原有的文本区域覆盖一个遮挡层,再在上面加上文本来实现. 所需jar包: 1.先在PDF需要替换的位置覆盖一个白色遮挡层(颜色可根据PDF文字背 ...
- 利用java从docx文档中提取文本内容
利用java从docx文档中提取文本内容 使用Apache的第三方jar包,地址为https://poi.apache.org/ docx文档内容如图: 目录结构: 每个文件夹的名称为日期加上来源,例 ...
- C# 设置或验证 PDF中的文本域格式
概述 PDF中的文本域可以通过设置不同格式,用于显示数字.货币.日期.时间.邮政编码.电话号码和社保号等等.Adobe Acrobat提供了许多固定的JavaScripts用来设置和验证文本域的格式, ...
- 使用itext直接替换PDF中的文本
直接说问题,itext没有直接提供替换PDF中文本的接口(查看资料得到的结论是PDF不支持这种操作),不过存在解决思路:在需要替换的文本上覆盖新的文本.按照这个思路我们需要解决以下几个问题: itex ...
- Java 读取PDF中的文本和图片
本文将介绍通过Java程序来读取PDF文档中的文本和图片的方法.分别调用方法extractText()和extractImages()来读取. 使用工具:Free Spire.PDF for Ja ...
随机推荐
- 使用Java绘制验证码
效果图: JDemo.java import java.io.File; import java.io.IOException; import static java.lang.System.out; ...
- iOS开发中对于一些常用的相对路径(持续更新)
1.iOS开发的证书的描述文件放置地点 ~/Library/MobileDevice/Provisioning Profiles 2.$(SRCROOT)代表的是这个项目文件夹所在的位置 $(PR ...
- ios 短音效的使用
1.通用短音效ID的获取 #import <Foundation/Foundation.h> @interface MJAudioTool : NSObject /** * 播放音效 * ...
- gnss到底是什么呢
GNSS Global Navigation Satellite System 全球卫星导航系统:提到这个很多人会不明白GNSS倒是是个啥东西呢,和北斗,GPS, GLONASS,Galileo系统有 ...
- mongodb mongod 参数解释
基本配置----------------------------------------------------------------------------------quiet # 安静输出-- ...
- jsp的4大作用域
jsp的4大作用域 首先要声明一点,所谓“作用域”就是“信息共享的范围”,也就是说一个信息能够在多大的范围内有效.4个JSP内置对象的作用域分别为:application.session.reques ...
- UUIDUtils
package com.cc.hkjc.util; import java.util.UUID; /** * 字符串工具类 * * @author:匿名 * */public class UUID ...
- 安装YouCompleteMe时,编译依赖的python版本不对
启动vim打开文件时出错: The ycmd server SHUT DOWN (restart with ':YcmRestartServer'). YCM core library compile ...
- 【扬中集训DAY1T1】 微信群
[题目链接] 点击打开链接 [算法] 对问题稍加分析后,发现其实要求的就是 : C(N,K) + C(N,K+1) + C(N,K+2) + ... + C(N,N) 因为N最大10^9,K最大10^ ...
- 初学者遇到的PostgreSQL字符集问题的解决
当初学者在使用PostgreSQL数据库,输入中文时,会遇到“ERROR: invalid byte sequence for encoding "UTF8": 0xd6d0”的 ...