java从pdf中提取文本
一(单文件转换):下载pdfbox包,百度搜pdfbox.(fontbox-1.8.16.jar和pdfbox-app-1.8.16.jar)
package pdf; import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter; import org.apache.pdfbox.pdfparser.PDFParser;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFTextStripper; /**
*
* @author 大汉
*
*/
public class PdfToTxt { public PdfToTxt() {
super();
// TODO Auto-generated constructor stub
} /**
*
* @param filename
* @return
* @throws Exception
*/
public String GetTextFromPdf(String filename) throws Exception { String content = null;
PDDocument pdfdocument = null; FileInputStream is = new FileInputStream(filename);
PDFParser parser = new PDFParser(is); parser.parse();
pdfdocument = parser.getPDDocument();
PDFTextStripper stripper = new PDFTextStripper();
content = stripper.getText(pdfdocument);
return content;
} /**
*
* @param args
*/
public static void main(String[] args) {
PdfToTxt pdfToTxt = new PdfToTxt();
try {
//获取pdf文件路径
String pdf = pdfToTxt.GetTextFromPdf("E:/2019a.pdf");
//输出到txt文件
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("E:/aa.txt"));
osw.write(pdf);
osw.flush();
osw.close();
}catch (Exception e){
e.printStackTrace();
} } }
还可以这样:(第二种方法)
package pdf; import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
import java.net.MalformedURLException;
import java.net.URL; import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFTextStripper; /**
* 批量转换
* @author 大汉
*
*/
public class BatchPdfToTxt { public BatchPdfToTxt() {
super();
// TODO Auto-generated constructor stub
} public static void readPdf(String file) throws Exception {
// 是否排序
boolean sort = false;
// pdf文件名
String pdfFile = file;
// 输入文本文件名称
String textFile = null;
// 编码方式
String encoding = "UTF-8";
// 开始提取页数
int startPage = 1;
// 结束提取页数
int endPage = Integer.MAX_VALUE;
// 文件输入流,生成文本文件
Writer output = null;
// 内存中存储的PDF Document
PDDocument document = null;
try {
try {
// 首先当作一个URL来装载文件,如果得到异常再从本地文件系统//去装载文件
URL url = new URL(pdfFile);
//注意参数已不是以前版本中的URL.而是File。
document = PDDocument.load(pdfFile);
// 获取PDF的文件名
String fileName = url.getFile();
// 以原来PDF的名称来命名新产生的txt文件
if (fileName.length() > 4) {
File outputFile = new File(fileName.substring(0, fileName.length() - 4)+ ".txt");
textFile ="E:/"+outputFile.getName();
}
} catch (MalformedURLException e) {
// 如果作为URL装载得到异常则从文件系统装载
//注意参数已不是以前版本中的URL.而是File。
document = PDDocument.load(pdfFile);
if (pdfFile.length() > 4) {
textFile = pdfFile.substring(0, pdfFile.length() - 4)+ ".txt";
}
}
// 文件输入流,写入文件倒textFile
output = new OutputStreamWriter(new FileOutputStream(textFile),encoding);
// PDFTextStripper来提取文本
PDFTextStripper stripper = null;
stripper = new PDFTextStripper();
// 设置是否排序
stripper.setSortByPosition(sort);
// 设置起始页
stripper.setStartPage(startPage);
// 设置结束页
stripper.setEndPage(endPage);
// 调用PDFTextStripper的writeText提取并输出文本
stripper.writeText(document, output); System.out.println(textFile + " 输出成功!");
} finally {
if (output != null) {
// 关闭输出流
output.close();
}
if (document != null) {
// 关闭PDF Document
document.close();
}
}
}
/**
*
* @param args
*/
public static void main(String[] args) {
try {
//注意此处的绝对地址格式,最好要用这一种。
readPdf("E:/用户行为排序算法.pdf");
} catch (Exception e) {
e.printStackTrace();
}
}
}
效果图:
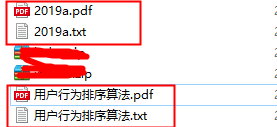

總結:唯一的缺點是不能顯示圖片,請看下一篇:----------------------->>>>>>>>PDF转WORD.
java从pdf中提取文本的更多相关文章
- Java 读取PDF中的文本和图片
本文将介绍通过Java程序来读取PDF文档中的文本和图片的方法.分别调用方法extractText()和extractImages()来读取. 使用工具:Free Spire.PDF for Ja ...
- Java 设置PDF中的文本旋转、倾斜
本文介绍通过Java程序在PDF文档中设置文本旋转.倾斜的方法.设置文本倾斜时,通过定义方法TransformText(page);并设置page.getCanvas().skewTransform( ...
- 用PDFMiner从PDF中提取文本文字
1.下载并安装PDFMiner 从https://pypi.python.org/pypi/pdfminer/下载PDFMineer wget https://pypi.python.org/pack ...
- Java 在PDF中添加水印——文本/图片水印
水印是一种十分常用的防伪手段,常用于各种文档.资料等.常见的水印,包括文字类型的水印.图片或logo类型的水印.以下Java示例,将分别使用insertTextWatermark(PdfPageBas ...
- 如何使用免费PDF控件从PDF文档中提取文本和图片
如何使用免费PDF控件从PDF文档中提取文本和图片 概要 现在手头的项目有一个需求是从PDF文档中提取文本和图片,我以前也使用过像iTextSharp, PDFBox 这些免费的PD ...
- java itext替换PDF中的文本
itext没有提供直接替换PDF文本的接口,我们可以通过在原有的文本区域覆盖一个遮挡层,再在上面加上文本来实现. 所需jar包: 1.先在PDF需要替换的位置覆盖一个白色遮挡层(颜色可根据PDF文字背 ...
- 利用java从docx文档中提取文本内容
利用java从docx文档中提取文本内容 使用Apache的第三方jar包,地址为https://poi.apache.org/ docx文档内容如图: 目录结构: 每个文件夹的名称为日期加上来源,例 ...
- 从PDF中提取信息----PDFMiner
今天由于某种原因需要将pdf中的文本提取出来,就去搜了下资料,发现PDFMiner是针对 内容提取的,虽然最后发现pdf里面的文本全都是图片,就没整成功,不过试了个文本可复制的 那种pdf文件,发现还 ...
- C# 设置或验证 PDF中的文本域格式
概述 PDF中的文本域可以通过设置不同格式,用于显示数字.货币.日期.时间.邮政编码.电话号码和社保号等等.Adobe Acrobat提供了许多固定的JavaScripts用来设置和验证文本域的格式, ...
随机推荐
- XAMARIN 安卓程序闪退问题
参考:https://forums.xamarin.com/discussion/25780/unfortunately-app-name-has-stopped 在VS 2017中使用Xamarin ...
- 【interview】汉诺塔学递归
https://www.cnblogs.com/yanlingyin/archive/2011/11/14/2247594.html https://www.cnblogs.com/dmego/p/5 ...
- Mysql 反向解析 导致远程访问慢
在云端部署了mysql后,发现远程连接的响应速度非常慢(3-10s) 但是在本地访问数据库却没有问题 经过一番google这才知道原来mysql默认会进行反向解析,即通过ip地址反向向ISP申请获取域 ...
- FhqTreap的区间翻转
学 Fhq 就是为了尽量不去写某毒瘤数据结构,所以自然要来杠一杠某数据结构的经典操作:区间反转 听起来玄乎,但只需要一个小 trick 就行了:把原来的区间以下标作为权值建成 Treap , 这样整棵 ...
- (转)python 开发 sqlite 绝对完整
'''SQLite数据库是一款非常小巧的嵌入式开源数据库软件,也就是说 没有独立的维护进程,所有的维护都来自于程序本身. 在python中,使用sqlite3创建数据库的连接,当我们指定的数据库文件不 ...
- Tomcat8.0.11优化相关
Tomcat 8.0.X: 要了解tomcat的优化,我们先看看Tomcat的官方定义:The Apache Tomcat® software is an open source implementa ...
- ansible-mysql
ansible mysql -m command -a "yum -y install https://www.percona.com/downloads/percona-monitorin ...
- Android Q 变更和新特性
安全和隐私变更 隐私保护是Android Q重要的主题之一,Android Q带来了一系列增强用户隐私保护的变更. 1 应用文件存储空间限制 应用访问限制是Android Q影响最大变更之一.在And ...
- mysql8.0 定时创建分区表记录 每天定时创建下一天的分区表
因单表数据太大, 需要表按时间分区 分区字段 pay_out_date 按天分 要求自动创建 1. 创建分区表 MYSQL的分区字段,必须包含在主键字段内 常见错误提示 错误提示:#1503 A PR ...
- 使用Fiddler完成Android和IOS手机抓包Https
实现原理 Fiddler是PC端有名的HTTP抓包工具,利用它我们可以轻松实现对主机上所有http/https网络请求的捕捉.查看和修改操作. 同时它也提供了代理模式,其它主机由它代理发送的网络请求也 ...