python-爬虫(3)---lxml匹配css
百度首页 部分代码
<div class="s_tab_inner">
<b>网页</b>
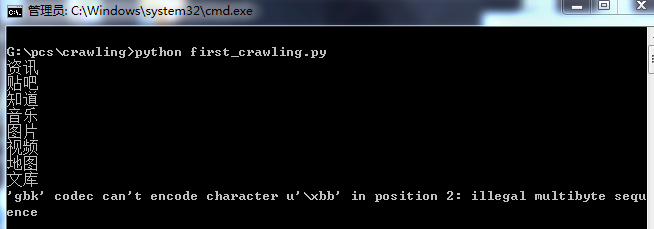
<a href="//www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=" wdfield="word" onmousedown="return c({'fm':'tab','tab':'news'})" sync="true">资讯</a>
<a href="http://tieba.baidu.com/f?kw=&fr=wwwt" wdfield="kw" onmousedown="return c({'fm':'tab','tab':'tieba'})">贴吧</a>
<a href="http://zhidao.baidu.com/q?ct=17&pn=0&tn=ikaslist&rn=10&word=&fr=wwwt" wdfield="word" onmousedown="return c({'fm':'tab','tab':'zhidao'})">知道</a>
<a href="http://music.taihe.com/search?fr=ps&ie=utf-8&key=" wdfield="key" onmousedown="return c({'fm':'tab','tab':'music'})">音乐</a>
<a href="http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=" wdfield="word" onmousedown="return c({'fm':'tab','tab':'pic'})">图片</a>
<a href="http://v.baidu.com/v?ct=301989888&rn=20&pn=0&db=0&s=25&ie=utf-8&word=" wdfield="word" onmousedown="return c({'fm':'tab','tab':'video'})">视频</a>
<a href="http://map.baidu.com/m?word=&fr=ps01000" wdfield="word" onmousedown="return c({'fm':'tab','tab':'map'})">地图</a>
<a href="http://wenku.baidu.com/search?word=&lm=0&od=0&ie=utf-8" wdfield="word" onmousedown="return c({'fm':'tab','tab':'wenku'})">文库</a>
<a href="//www.baidu.com/more/" onmousedown="return c({'fm':'tab','tab':'more'})">更多»</a>
</div>

根据css查找符合条件的内容
python-爬虫(3)---lxml匹配css的更多相关文章
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python爬虫基础——HTML、CSS、JavaScript、JQuery网页前端技术
一.HTML HTML是Hyper Text Markup Language(超文本标记语言)的缩写. HTML不是一种编程语言,而是标记语言. HTML的语法 双标签: 单标签: HTML的元素和属 ...
- Python爬虫-换行的匹配
之前在学习爬虫的时候遇到了匹配内容时发现存在换行,这时没法匹配了,后来在网上找到了一种方法,当时懒得记录,今天突然有遇到了这种情况,想想还是在这里记录一下吧. 当时爬取的时csdn首页博客,如下图 看 ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
- [爬虫]Windows下如何安装python第三方库lxml
lxml是个非常有用的python库,它可以灵活高效地解析xml与BeautifulSoup.requests结合,是编写爬虫的标准姿势. 但是,当lxml遇上Windows,简直是个巨坑.掉在安装陷 ...
- python爬虫入门(三)XPATH和BeautifulSoup4
XML和XPATH 用正则处理HTML文档很麻烦,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素. XML 指可扩展标记语言(EXtensible Ma ...
- 【转】Python爬虫:抓取新浪新闻数据
案例一 抓取对象: 新浪国内新闻(http://news.sina.com.cn/china/),该列表中的标题名称.时间.链接. 完整代码: from bs4 import BeautifulSou ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
随机推荐
- MSB4064 错误
把项目从vs2008转成vs 2012 后,受用msbuild 编译出错 错误Code:MSB4064 修改 把msbuild 的路径从 %windir%\Microsoft.NET\Framewor ...
- PostgreSQL自学笔记:5 数据类型和运算符
5 数据类型和运算符 5.1 PostgreSQL 数据类型介绍 5.1.1 整数类型 整型类型 字节 取值范围 smallint 2字节 -2^15 ~ 2^15 int integer 4字节 - ...
- 关于在虚拟机上安装ubuntu输入不了中文的问题
打开终端后,无法输入中文,按照网络上的教程 1.安装语言包 System Settings–>Language Support–>Install/Remove Languages 选中ch ...
- JQuery 绑定单击事件到某个函数的的方法
<script> function 我会在加载完页面马上执行() { alert('我会在加载完页面马上执行'); } function 我只会在按钮点击时才执行() { alert('我 ...
- CentOS下的Mysql的安装和使用
1.使用安装命令 :yum -y install mysql mysql-server mysql-devel 安装完成却发现Myserver安装缺失,在网上找原因,原来是因为CentOS 7上把My ...
- Linux搭建git服务端
1.安装$ yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel perl-devel$ yum inst ...
- PHP使用 strpos() 注意事项
返回字符出现的第一个位置, 如果字符在被搜索字符串的开头, 则会返回 ‘0’ 因此, 在使用此函数判断 字符串是否包含 某一个字符时 使用: if(strpos('string','str') != ...
- 变量类型-Number
教程:一:数字类型 (1)int 没有限制大小,有以下的四种表现形式: 1:2进制:以'0b'开头---bin 2:8进制:以'0o'开头---oct 3:1 ...
- node 学习(一)
什么是 Node.js Node.js就是运行在服务端的JavaScript. Node.js是一个基于Chrome JavaScript运行时建立的一个平台. Node.js是一个事件驱动 I/O ...
- php抓取图片进行内容提取解析,文字性pdf进行内容文字提取解析
2018年7月7日18:52:17 php是用纯算法,自己是提取图片内容不是不行,可以但是优化起来很麻烦还得设计学习库,去矫正数据的正确率 对于大多数项目来说,如果不是做ocr服务,就不必要做需求工具 ...