Stacking:Catboost、Xgboost、LightGBM、Adaboost、RF etc
python风控评分卡建模和风控常识(博客主亲自录制视频教程)

http://www.360doc.com/content/18/1015/10/60075508_794857307.shtml
http://www.sohu.com/a/259742009_787107
任务 :精品旅行服务成单预测
提供了5万多名用户在境外旅行APP(黄包车)中的浏览行为记录和历史订单记录(具体数据和字段如下五张表所示),其中用户在浏览APP之后有三种可能,购买精品旅游服务,或普通旅行服务,还有部分用户则不会下单。需要分析用户的个人信息、历史记录和浏览行为等,预测用户是否会在短期内购买精品旅游服务。
(训练集浏览记录一百三十三万条,测试集33万条)
- Tab1 用户个人信息表(用户id、性别、省份、年龄段)
- Tab2 用户浏览记录表(用户id、行为类型、发生时间)
- Tab3 用户历史订单表(用户id、订单id、订单时间、订单类型、旅游城市、国家、大陆)
- Tab4 待预测订单表(id、订单类型 1 精品 0普通)
- Tab4 用户评论数据(用户id、订单id、评分、标签、评论内容)
比赛成绩
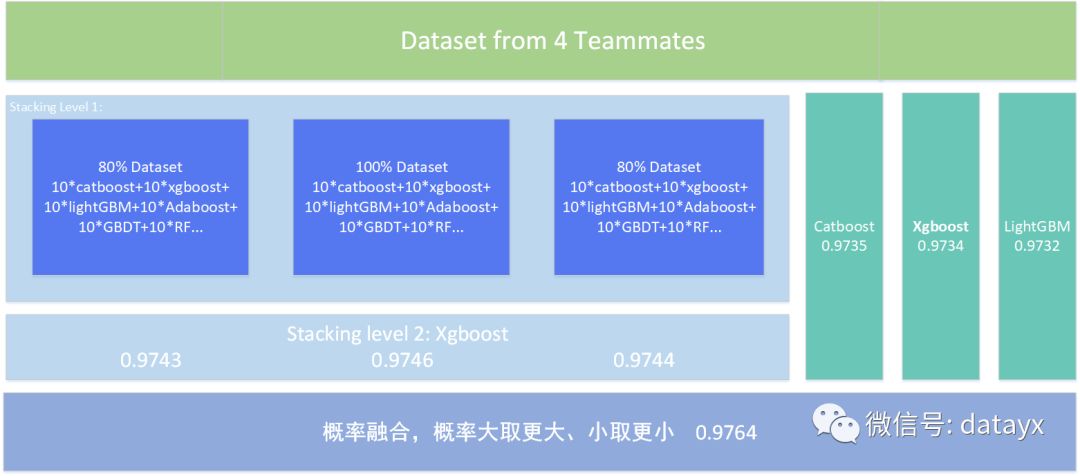
- 2018-02-08 AUC: 0.9764 B榜 Rank 2(Stacking:Catboost、Xgboost、LightGBM、Adaboost、RF etc.)
- 2018-02-07 AUC: 0.9589 A榜 Rank 3(Weight Average:0.65 * Catboost + 0.35 * XGBoost)
- 2018-01-21 AUC: 0.9733 半程冠军 (Single model:Catboost)
代码获取:
比赛方案
- 数据预处理:首先对数据进行清洗处理缺失值,浏览记录表中的1-4类无顺序,5-9类有顺序,一方面对567*9这种补齐8操作,另一方面发现订单历史记录中的下单时间戳和浏览记录的7操作时间一样,对于历史订单有订单但在浏览记录中对应时间点没有7操作的记录补齐7操作,还有基本信息缺失处理如性别的缺失处理等。
- 特征工程:特征设计主要从 (历史订单 + 浏览行为 + 时间特征 + 文本评论) 这几方面展开,并根据特征方差和特征与label的相关系数&绘图进行特征选择,具体特征在如下。
- 模型选择:由于其中包括浏览记录是属于类别特征,选用对类别特征直接支持且在泛化能力强不易过拟合的Catboost算法,和LightGBM算法。
- 模型融合:最后模型融合使用Stacking的方式,特征分三份:第一层使用(参数不一样)的10个Catboost、xgboost和lightGBM训练,第二层使用xgboost融合,最后三个stacking结果再次融合,融合方法采用概率大取更大、小取更小,通俗的理解是在表现效果 (AUC) 相差不大的多个模型中,去选取对该条样本预测更自信的模型作为最终结果。(全集特征+两份有重合不完全特征80%(根据特征相关性,强耦合的特征分开))单独Stacking:0.9746,三份stacking融合0.97640,单模型0.9735
- 由于部分用户浏览记录很少(只有几条),导致这些用户的很多特征维度为空,属于“冷启动”问题,单独建立在其历史特征和评论特征维度进行预测。
模型设计与模型融合
特征工程
特征按照比赛时间进展在文件夹feature中,分别为1 ~ 10_extract_feature.py,以下根据特征所属类别(历史订单 + 浏览行为 + 时间特征 + 文本评论 + 交互)进行分类,具体特征提取方法可以看其中注释,另外特征工程运行时间较长,完整的特征文件下载:
精品旅行服务预测Rank2特征文件
获取方式:
总结如下:
- 历史订单特征
- 历史订单数量
- 历史出现精品订单 1 的数量和占比
- 历史出现普通订单 0 的次数和占比
- 用户最近一次出行是否为精品旅行 1
- 历史纪录中城市的精品占比
- 历史订单是否出现过精品订单 1 (leak)
- 历史订单最近一次是什么类型 0 / 1
- 历史订单最近一次去的州、国家、城市
- 浏览行为特征(全部:指用户所有的浏览记录,对应:指该次购买对应的浏览记录)
- 全部浏览记录中0-9出现的次数
- 对应浏览记录中0-9出现的次数
- 全部浏览记录浏览时间
- 对应浏览记录浏览时间
- 对应浏览记录是否出现5 6
- 全部浏览记录是否出现56 67 78 89
- 对应浏览记录是否出现56 67 78 89
- 全部浏览记录是否出现567 678 789 566
- 对应浏览记录是否出现567 678 789 566
- 全部浏览记录是否出现5678 6789
- 全部浏览记录是否出现56789
- 对应浏览记录是否出现56789
- action中大于6出现的次数
- 对应点击2-4的和值 与 5-9 的比值
- 全部点击2-4的和值 与 5-9 的比值
- 对应浏览记录 1-9 操作所用平均时间
- 全部浏览记录 1-9 操作所用平均时间
- 全部action 最后一次 的类型
- 全部 action 倒数第2-6次操作的类型
- 最后1 2 3 4 次操作的时间间隔
- 时间间隔的均值 最小值 最大值 方差
- action 最后4 5 6 次操作时间的方差 和 均值
- 对应浏览记录浏览平均时间(可以改成最近几天的)
- 对应浏览记录 1-9 操作所用平均时间
- 全部浏览记录 1-9 操作所用平均时间
- 每日用户action的次数
- 每日用户action的时间
- 最近1周的使用次数 eval-auc:0.963724
- 离最近的1-9的距离(间隔操作次数) 只取 56789
- 总体操作 1 2 3 4 5 6 7 8 9 次数的排名 rank
- 对应操作 1 2 3 4 5 6 7 8 9 次数的排名 rank
- 用户使用APP的天数,分别是否老用户
- 用户当前时间距离最近历史订单时间间隔
- 文本评论特征
- 评论的长度
- 评论的标签个数(强特征 涨分1个万)
- 用户订单评分的统计特征(平均分、方差)
- 用户评论各类分数的比例,最近一次评论的分数
- 分用户普通订单评论的平均分和精品订单平均分
- 使用snownlp对用户评论进行情感分析,统计用户订单评论得分
- 用户特征
- 是否新用户
- 性别 是否男 是否女 是否缺失
- 所属省份/城市(one-hot encode)
- 所属年龄段(one-hot encode)
- 时间特征
- 以最近的浏览记录作为要预测的用户订单时间
- 当前时间点的月份、当月第几天、星期几、是否周末
- 用户历史订单最多的月份、当月第几天、星期几、是否周末
- 是否为该城市的旅游旺季
- 季节特征
运行环境和代码结构
代码运行环境,包含主要软件和库
代码结构
- 在boutique_travel是整个比赛的代码,数据存储路径在
- data文件夹用来存放数据,
- 其中包含提取的特诊集(train6/test6、train_feature1/test_feature1、data_train/data_test)
- submit文件夹是提交的结果文件,其下面子文件夹包含各个单模型的预测结果
- feature文件夹存放提取特征的代码
- 包含1 ~ 10_extract_feature.py 每部分代码对应提取的特征均有注释
- model文件夹存放模型训练、预测和融合的代码
- 1_submit.py是概率文件融合和修改预测结果为比赛要求的提交格式
- 2~6分别是catboost、xgboost、lightGBM等的单模型和5折CV训练预测
- 7是特征分三分,分别做两层的stacking learning,最后再对表现结果差不多的概率文件结果融合
- model文件夹存储训练好的模型
车辆检测及型号识别,准确率接近90%
全球AI挑战-场景分类的比赛源码(多模型融合)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

Stacking:Catboost、Xgboost、LightGBM、Adaboost、RF etc的更多相关文章
- LR、SVM、RF、GBDT、XGBoost和LightGbm比较
正则化 L1范数 蓝色的是范数的解空间,红色的是损失函数的解空间.L2范数和损失函数的交点处一般在坐标轴上,会使\(\beta=0\),当然并不一定保证交于坐标轴,但是通过实验发现大部分可以得到稀疏解 ...
- 随机森林RF、XGBoost、GBDT和LightGBM的原理和区别
目录 1.基本知识点介绍 2.各个算法原理 2.1 随机森林 -- RandomForest 2.2 XGBoost算法 2.3 GBDT算法(Gradient Boosting Decision T ...
- 从信用卡欺诈模型看不平衡数据分类(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制。过采样后模型选择RF、xgboost、神经网络能够取得非常不错的效果。(2)模型层面:使用模型集成,样本不做处理,将各个模型进行特征选择、参数调优后进行集成,通常也能够取得不错的结果。(3)其他方法:偶尔可以使用异常检测技术,IF为主
总结:不平衡数据的分类,(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制.过采样后模型选择RF.xgboost.神经网络能够取得非常不错的效果.(2)模型层面:使用模型 ...
- 一步一步理解GB、GBDT、xgboost
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- RF、GBDT、XGBOOST常见面试算法整理
1. RF(随机森林)与GBDT之间的区别 相同点: 1)都是由多棵树组成的 2)最终的结果都是由多棵树一起决定 不同点: 1) 组成随机森林的树可以是分类树也可以是回归树,而GBDT只由回归树组 ...
- GB、GBDT、XGboost理解
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- Boosting算法总结(ada boosting、GBDT、XGBoost)
把之前学习xgb过程中查找的资料整理分享出来,方便有需要的朋友查看,求大家点赞支持,哈哈哈 作者:tangg, qq:577305810 一.Boosting算法 boosting算法有许多种具体算法 ...
- C#、JAVA操作Hadoop(HDFS、Map/Reduce)真实过程概述。组件、源码下载。无法解决:Response status code does not indicate success: 500。
一.Hadoop环境配置概述 三台虚拟机,操作系统为:Ubuntu 16.04. Hadoop版本:2.7.2 NameNode:192.168.72.132 DataNode:192.168.72. ...
- 教你一招:解决win10/win8.1系统在安装、卸载软件时出现2502、2503错误代码的问题
经常遇到win10/win8.1系统在安装.卸载软件时出现2502.2503错误代码的问题. 解决办法: 1.打开任务管理器后,切换到“详细信息”选项卡,找到explore.exe这个进程,然后结束进 ...
随机推荐
- python 迭代器协议和生成器
一.什么是迭代器协议 1.迭代器协议是指:对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么就引起一个stoplteration异常,以终止迭代(只能往后走,不能往前退) 2.可迭代 ...
- c/c++ 多线程 层级锁
多线程 层级锁 当要同时操作2个对象时,就需要同时锁定这2个对象,而不是先锁定一个,然后再锁定另一个.同时锁定多个对象的方法:std::lock(对象1.锁,对象2.锁...) 但是,有的时候,并不能 ...
- 为什么不使用github的wiki而是使用mkdocs做文档管理?
为什么不使用github的wiki而是使用mkdocs做文档管理? 目前 KSFramework 是使用mkdocs来做在线文档 而非使用github的wiki,这是为什么呢? 在windows下搭建 ...
- Docker之进入容器(三)
1.简介 经过前面两篇博客的扫盲,大家多多少少对docker有了一个基本的了解,也接触了docker的常用命令.在这篇博客中,我将介绍进入docker容器的几种方式. 2.进入docker中的几种方式 ...
- Jetson TX2(2)ubutu1604--安装opencv3.4.0
1安装OpenCV3.4.0+contrib 1 在终端中敲入以下两句sudo rm /var/cache/apt/archives/locksudo rm /var/lib/dpkg/lock su ...
- WiFi广告强推的基本技术原理和一些相关问题
WiFi推原理(转) 本文地址:http://jb.tongxinmao.com/Article/Detail/id/412 WiFi广告强推的基本技术原理和一些相关问题 WiFi广告推送原理就是利用 ...
- 3-STM32带你入坑系列(自己封装点亮一个灯的库--Keil)
2-STM32带你入坑系列(点亮一个灯--Keil) 首先建一个stm32f103x.h的文件,然后 #include "stm32f103x.h" 还记得上一节 现在呢就是做一个 ...
- ARC089E GraphXY 构造
传送门 在Luogu上评了"NOI"之后评级变成了"普及+/提高"--我觉得我可能要退群了 考虑构造一个这样的图: 其中上半部分是从\(S\)开始的一条长\(1 ...
- 爬虫之selenium模块
Selenium 简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟 ...
- ADO.NET之使用DataSet类更新数据库
1.首先从数据库获得数据填充到DataSet类,该类中的表和数据库中的表相互映射. 2.对DataSet类中的表进行修改(插入,更新,删除等) 3.同步到数据库中:使用SqlDataAdapter实例 ...