【一】,python简单爬虫实现
一:
1.获取当前页的课程名称,地址:https://www.ichunqiu.com/courses/webaq
2.选取其中一门课程名称查看源代码:
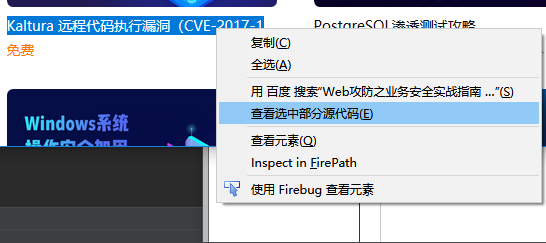
代码如下:
<p class="coursename" title="Kaltura 远程代码执行漏洞(CVE-2017-14143)" onclick="javascript:window.open
3.正则表达式获取课程名称:
#coding=utf-8 import re html = ''' <!DOCTYPE html> <html> #此处为需要爬去页面的源代码 </html> ''' title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html) print (title)
执行结果如下:页面所以课程名称获取到
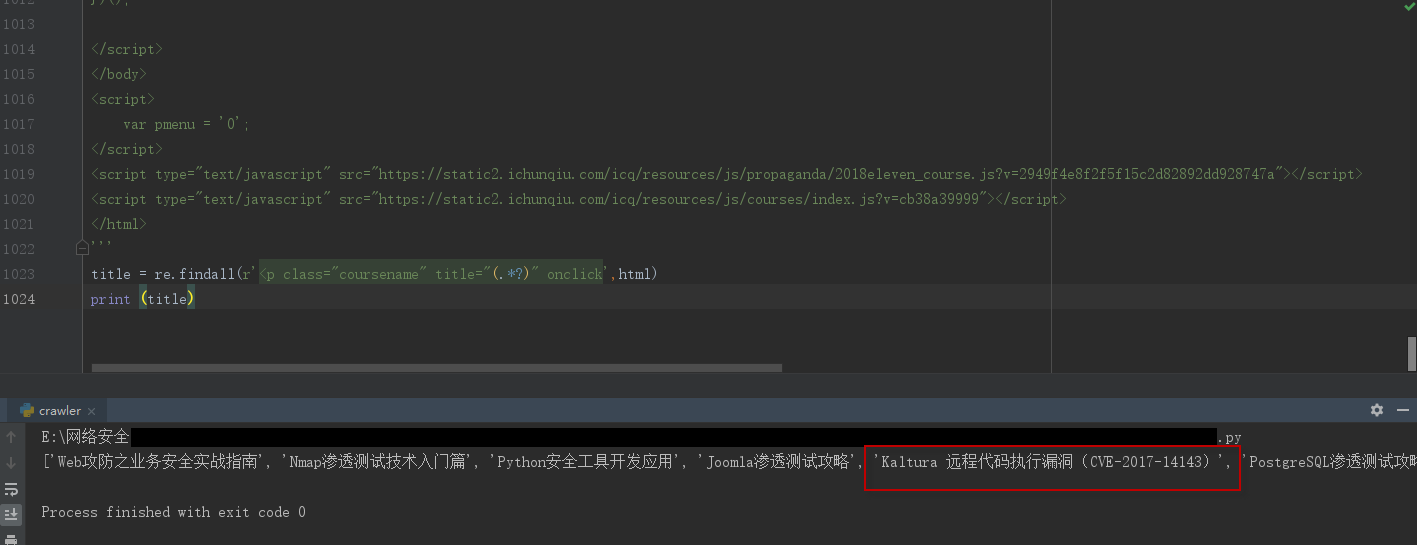
遍历:
#coding=utf-8
import re
html = '''
<!DOCTYPE html>
<html>
#此处为需要爬去页面的源代码
</html>
'''
title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html)
# print (title)
for i in title:
print(i)
效果如下:
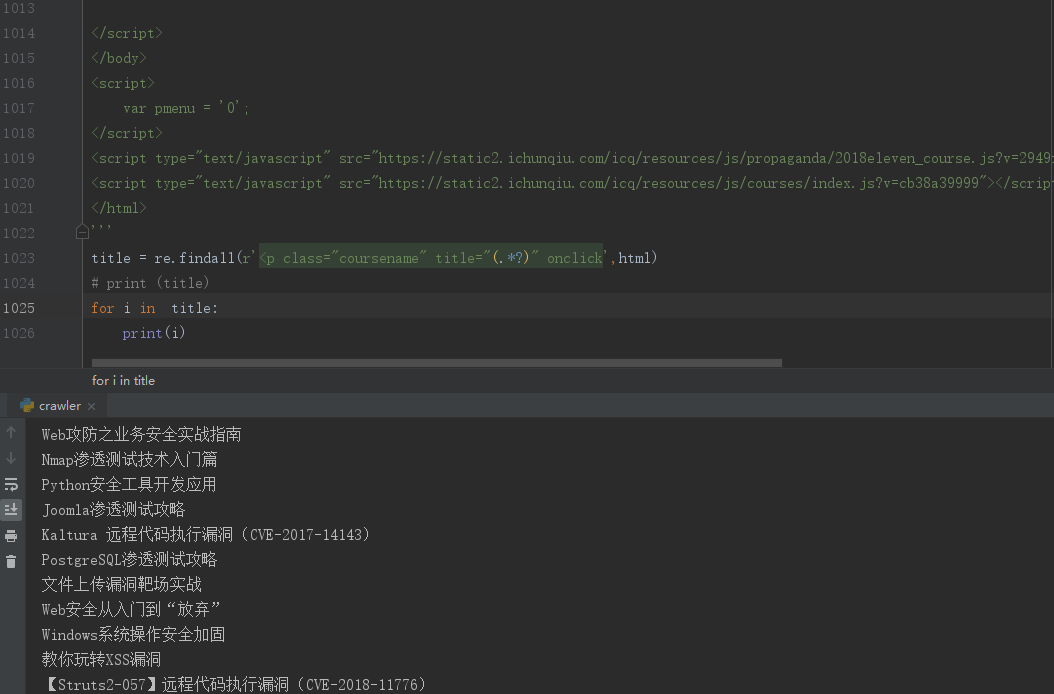
二:urllib使用
(注:此处python为3.7,与2.x有点区别)
定制请求头:urllib.urlopen() 下载文件:urllib.urlretrieve()
1.向www.baidu.com发起请求:
import urllib.request #导入urllib和urllib2库
url = urllib.request.urlopen('http://www.baidu.com') #定义一个地址
r = url.read() #用urlib向百度发起请求
print (r)#查看发起请求的内容
结果如下:

2.下载百度图片:
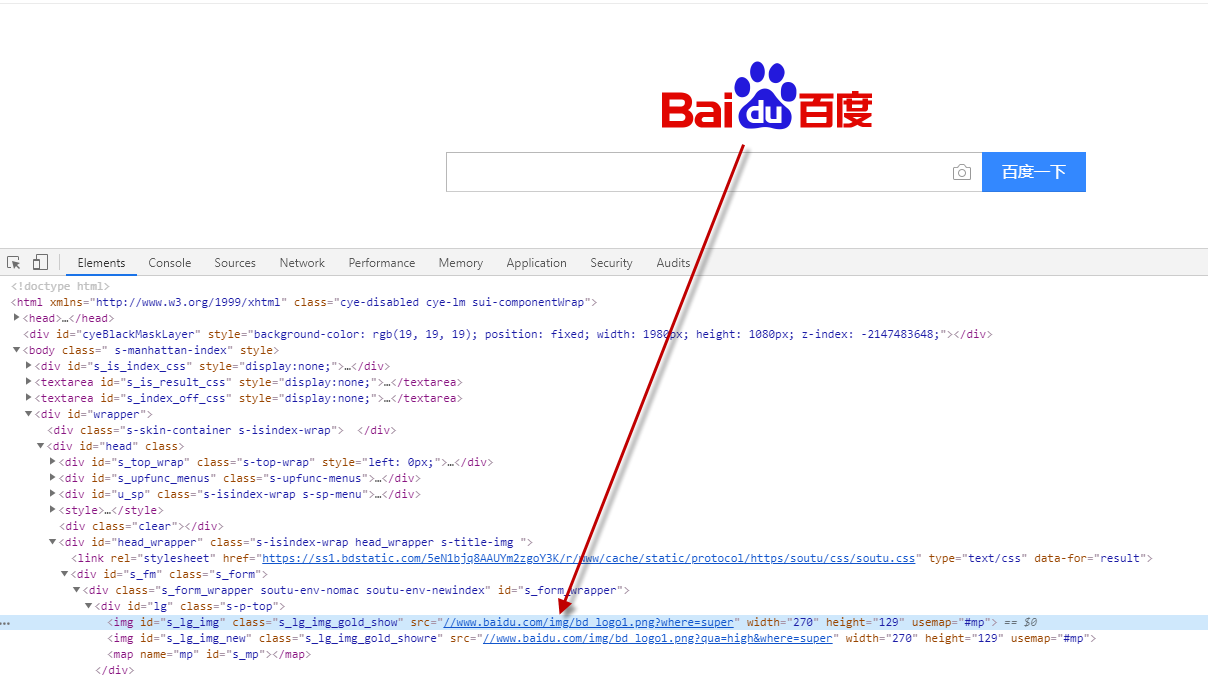
图片地址如下:
https://www.baidu.com/img/bd_logo1.png?where=super
代码:
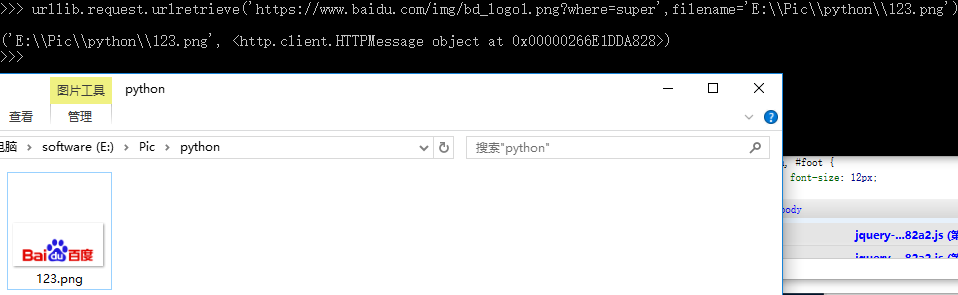
urllib.request.urlretrieve('https://www.baidu.com/img/bd_logo1.png?where=super',filename='E:\\Pic\\python\\123.png')
效果如下,图片下载成功:
三:requests
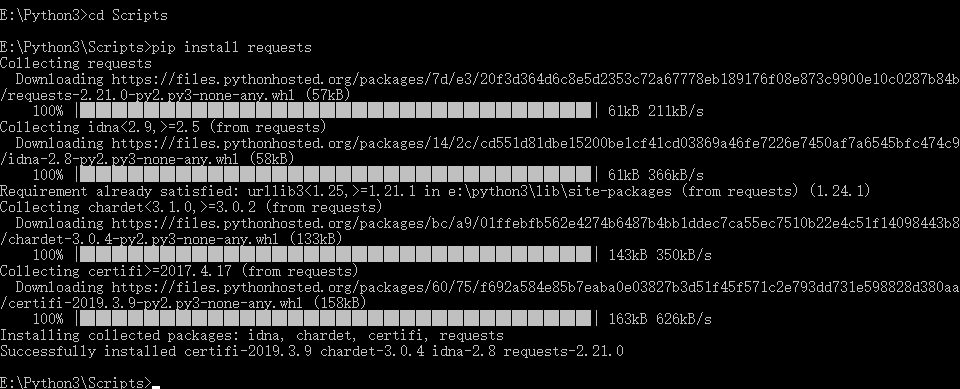
1.window 下requests安装:
查看python路径:

下载requests:
pip install requests
示例:向url发起get请求
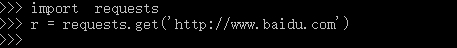
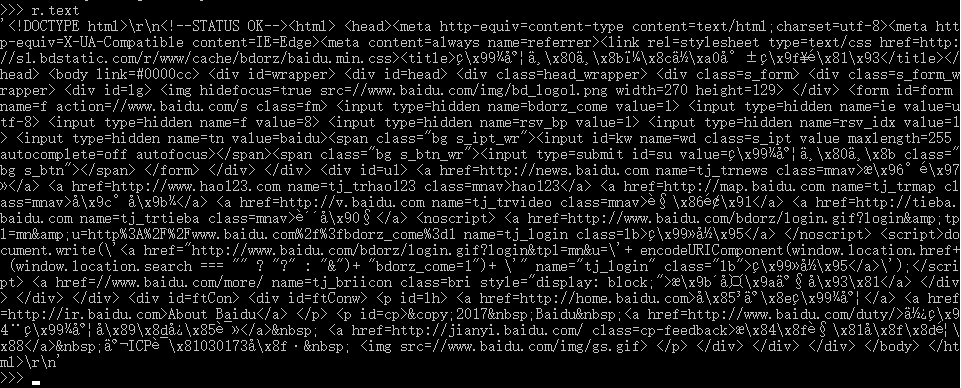
查看响应内容:
方法1:
响应内容 r.test
方法2:
二进制响应内容>>> print (r.content) 或 r.content
定制请求头:
url = 'http://www.baidu.con'
headers = {'content-type':'application/json'}
r = requests.get(url,headers=headers)
查看状态码:
r.status_code

查看响应头:
r.headers

查看Cookies:
r.cookies

timeout设置超时:
>>> requests.get('http://www.baidu.com',timeout=0.001)


【一】,python简单爬虫实现的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
随机推荐
- Odoo前端页面模版渲染引擎——Jinja2用法教程
转载请注明原文地址:https://www.cnblogs.com/cnodoo/p/9307200.html 一:渲染模版 要渲染一个qweb模板文件,通过render_template方法即可. ...
- 优化升级logging封装RotatingFileHandler
1.升级优化,提供用户自定义日志level文件夹生成控制,提供日志错误显示到日志打印异常补获到日志 # coding=utf-8 import logging import time import o ...
- java crm 进销存 springmvc SSM 项目 源码 系统
系统介绍: 1.系统采用主流的 SSM 框架 jsp JSTL bootstrap html5 (PC浏览器使用) 2.springmvc +spring4.3.7+ mybaits3.3 SSM ...
- 1025 反转链表(链表,reverse)
题目: 给定一个常数 K 以及一个单链表 L,请编写程序将 L 中每 K 个结点反转.例如:给定 L 为 1→2→3→4→5→6,K 为 3,则输出应该为 3→2→1→6→5→4:如果 K 为 4,则 ...
- 评价指标1--F1值和MSE
1,F1=2*(准确率*召回率)/(准确率+召回率) F1的值是精准率与召回率的调和平均数.F1的取值范围从0到1的数量越大,表明实现越理想. Precision(精准率)=TP/(TP+FP) Re ...
- 数据结构与算法之链表(LinkedList)——简单实现
这一定要mark一下.虽然链表的实现很简单,且本次只实现了一个方法.但关键的是例子:单向链表的反转.这是当年我去H公司面试时,面试官出的的题目,而当时竟然卡壳了.现在回想起来,还是自己的基本功不扎实, ...
- 使用uliweb创建一个简单的blog
1.创建数据库 uliweb的数据库都在models.py文件里面,因此先创建该文件 vim apps/blog/models.py 添加如下两行: #coding=utf-8 from uliweb ...
- 20155327 java第四周学习笔记
20155327 java第四周学习笔记 五六章知识整理 1子类与父类 父类是接口或者是抽象类,子类必须继承自父类. 2子类的继承性 在Java中,通过关键字extends继承一个已有的类,被继承的类 ...
- jQuery学习-属性选择器
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 如何实现PyQt5与QML响应彼此发送的信号?
对于PyQt5+QML+Python3混合编程,如何实现PyQt5与QML响应彼此发送的信号,这是一个棘手的问题. 大抵有如下五种方式: (要运行下面五个例子,千万不能在eric6中运行,会报错.错误 ...