Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup
BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题)
此工具在搜索你想爬的数据匹配的方式就是html标签嵌套的顺序(html介绍在其它随笔内)
首先来聊聊BeautifulSoup的安装pip install python-bs4 包含BeautifulSoup方法
再来安装依赖工具requests和解析格式lxml下载安装包 解压进入目录 python setup.py install此方法是请求服务
先来写一个简单的网页解析代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*- from bs4 import BeautifulSoup
import requests headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
}
url = "http://www.jd.com/" wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
print(soup)
来简单说明下每行代码得作用:
from从bs4库里import导入BeautifulSoup方法
import导入requests方法
headers表示头文件,伪装成浏览器浏览网页,当然我这里写得简单还没写全
url网页地址
wb_data网页数据requests.get请求访问(url网页京东,headers伪装的头文件)
soup解析后的数据BeautifulSoup解析数据(wb_data网页数据,lxml解析的格式按这个要求解析)
print答应soup解析后的网页数据 也就是网页源代码如下 由于网页源代码很长所以这里截图只能显示一部分
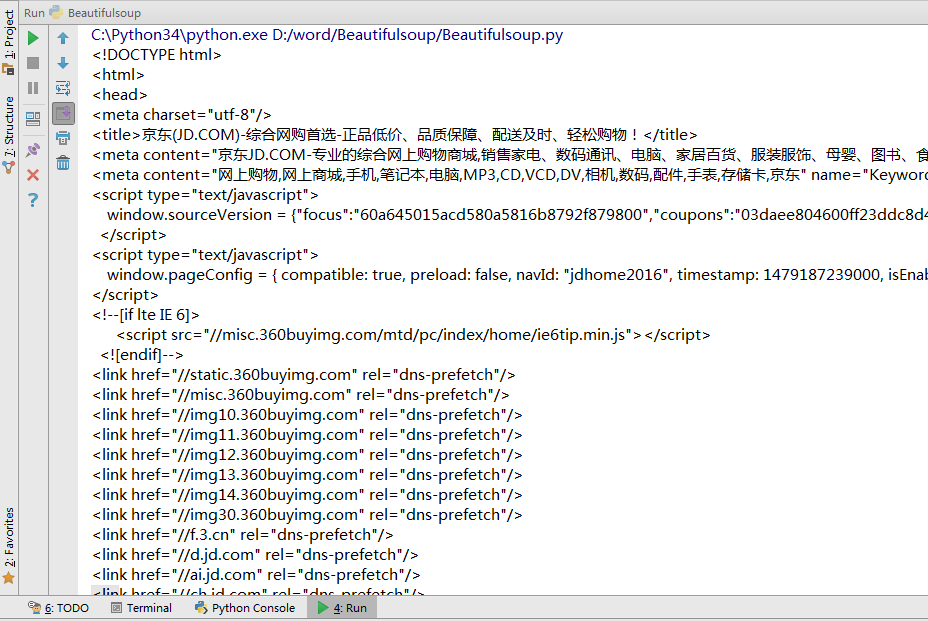
学好基础包括html的结构标签的嵌套还有CSS的名字在网页位置等后教你们怎么去抓电影等网站并且把内容归类好方便查阅
下面是我抓去某电影网站的数据及归类效果掩饰:

Python简单爬虫入门一的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- GJM : Python简单爬虫入门 (一) [转载]
版权声明:本文原创发表于 [请点击连接前往] ,未经作者同意必须保留此段声明!如有侵权请联系我删帖处理! 为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解 ...
- python网络爬虫入门范例
python网络爬虫入门范例 Windows用户建议安装anaconda,因为有些套件难以安装. 安装使用pip install * 找出所有含有特定标签的HTML元素 找出含有特定CSS属性的元素 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- python网络爬虫入门(二)
刚去看了一下,18年2月份写了第一篇关于爬虫的文章(仅仅介绍了使用requests库去获取HTML代码),一年多之后看来很稚嫩也没有多少参考的意义,但没想着要去修改它,留着也是一个回忆吧.至少证明着我 ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
随机推荐
- Azure Application Gateway (2) 面向公网的Application Gateway
<Windows Azure Platform 系列文章目录> 本章将介绍如何创建面向公网的Application Gateway,我们需要准备以下工作: 1.创建新的Azure Reso ...
- tomcat源码剖析系列
一个简单的web服务器 一个简单的servlet容器 连接器 创建httpRequest 创建HttpResponse 容器 生命周期 日志记录器 载入器 Session管理 关闭钩子 启动tomca ...
- Struts2 源码分析——Result类实例
本章简言 上一章笔者讲到关于DefaultActionInvocation类执行action的相关知识.我们清楚的知道在执行action类实例之后会相关处理返回的结果.而这章笔者将对处理结果相关的内容 ...
- 使用fiddler的autoResponder及设置手机端代理实现远程调试,出现的问题及解决办法
这是开通博客的第一篇随笔,好鸡冻哈哈o_O 首先是下载安装,我安装的是最新的v4.6.2.0版本,大家在百度上搜fidddler4在百度软件中心普通下载就可以了.或者直接用这个连接:http://dl ...
- Javascript 如何生成Less和Js的Source map
为什么有Source map CSS和JS脚本正变得越来越复杂,为了解决网络瓶颈,大部分源代码都需要经过编译.合并.压缩才能运用到实际环境中.为了减少网络资源占用,源码一般都会经过以下方式处理: 使用 ...
- Premiere Pro & After Effects插件开发调试方法
在给Adobe Premiere Pro(PR)和Adobe After Effects(AE)插件开发时,对于实时调试插件有着很强的需求.除了业务需求外,单步调试插件还能够摸清楚Plugin和Hos ...
- 用浏览器(支持WebSocket)和node-inspector 调试后端(CoffeeScript,Typescript)代码
调试效果 配置 npm安装node-inspector: $ npm install -g node-inspector 配置gulp,gulp可以用 gulp-node-inspector 或 用g ...
- Python解析非标准JSON(Key值非字符串)
采集数据的时候经常碰到一些JSON数据的Key值不是字符串,这些数据在JavaScript的上下文中是可以解析的,但在Python中,没有该部分数据的上下文,无法采用json.loads(JSON)的 ...
- 体验VS2015 Update 2 的 Android 和 Python
趁着假期不用加班,又遇到build 2016的劲爆消息--Xamarin免费集成到VS中 所以立马把vs升级到update 2体验一下下(之前也体验过). 在安装的时候也是只勾选了部分,不需要太多(全 ...
- 背水一战 Windows 10 (18) - 绑定: 与 Element 绑定, 与 Indexer 绑定, TargetNullValue, FallbackValue
[源码下载] 背水一战 Windows 10 (18) - 绑定: 与 Element 绑定, 与 Indexer 绑定, TargetNullValue, FallbackValue 作者:weba ...