【一】,python简单爬虫实现
一:
1.获取当前页的课程名称,地址:https://www.ichunqiu.com/courses/webaq
2.选取其中一门课程名称查看源代码:
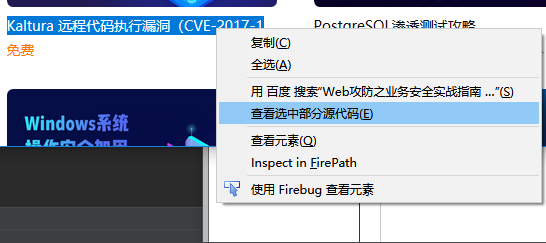
代码如下:
<p class="coursename" title="Kaltura 远程代码执行漏洞(CVE-2017-14143)" onclick="javascript:window.open
3.正则表达式获取课程名称:
#coding=utf-8 import re html = ''' <!DOCTYPE html> <html> #此处为需要爬去页面的源代码 </html> ''' title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html) print (title)
执行结果如下:页面所以课程名称获取到
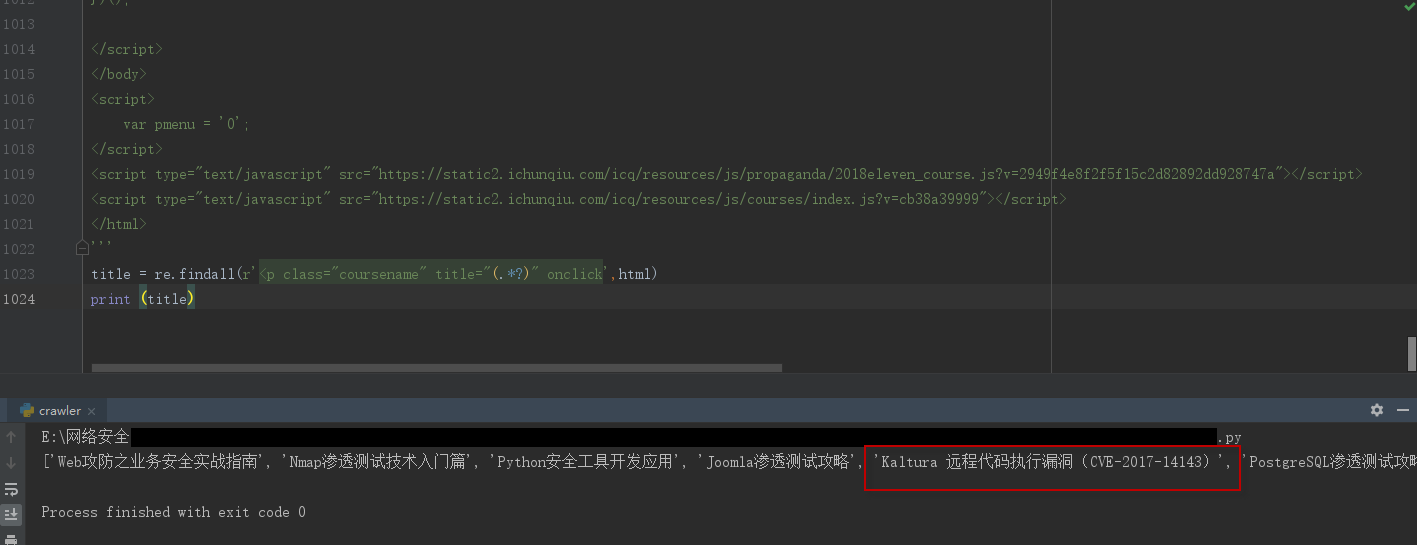
遍历:
#coding=utf-8
import re
html = '''
<!DOCTYPE html>
<html>
#此处为需要爬去页面的源代码
</html>
'''
title = re.findall(r'<p class="coursename" title="(.*?)" onclick',html)
# print (title)
for i in title:
print(i)
效果如下:
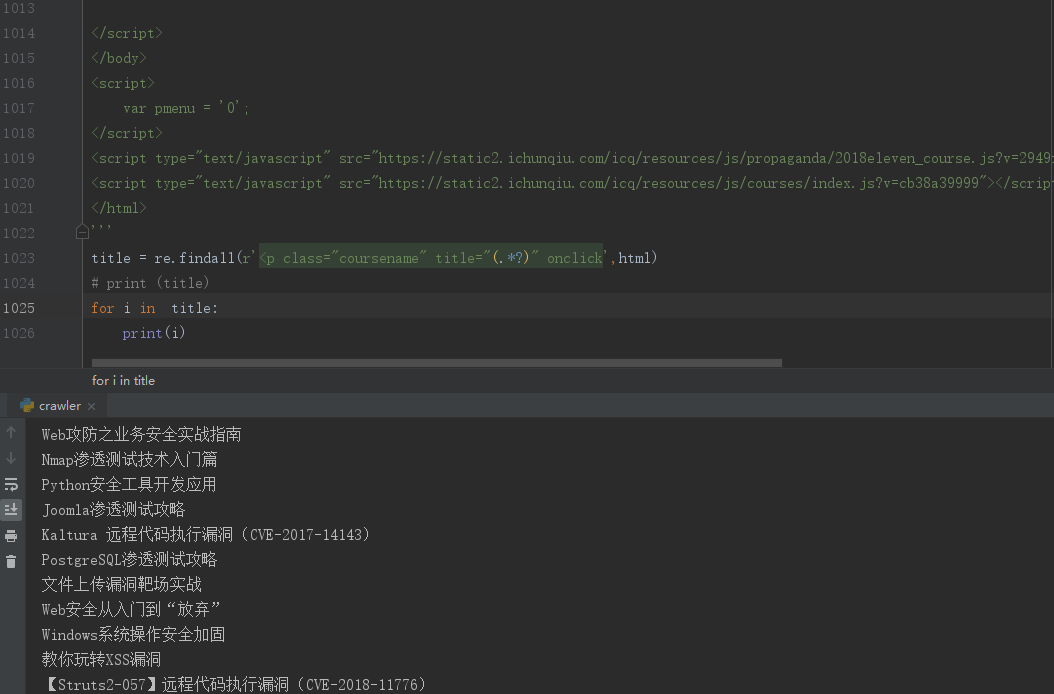
二:urllib使用
(注:此处python为3.7,与2.x有点区别)
定制请求头:urllib.urlopen() 下载文件:urllib.urlretrieve()
1.向www.baidu.com发起请求:
import urllib.request #导入urllib和urllib2库
url = urllib.request.urlopen('http://www.baidu.com') #定义一个地址
r = url.read() #用urlib向百度发起请求
print (r)#查看发起请求的内容
结果如下:

2.下载百度图片:
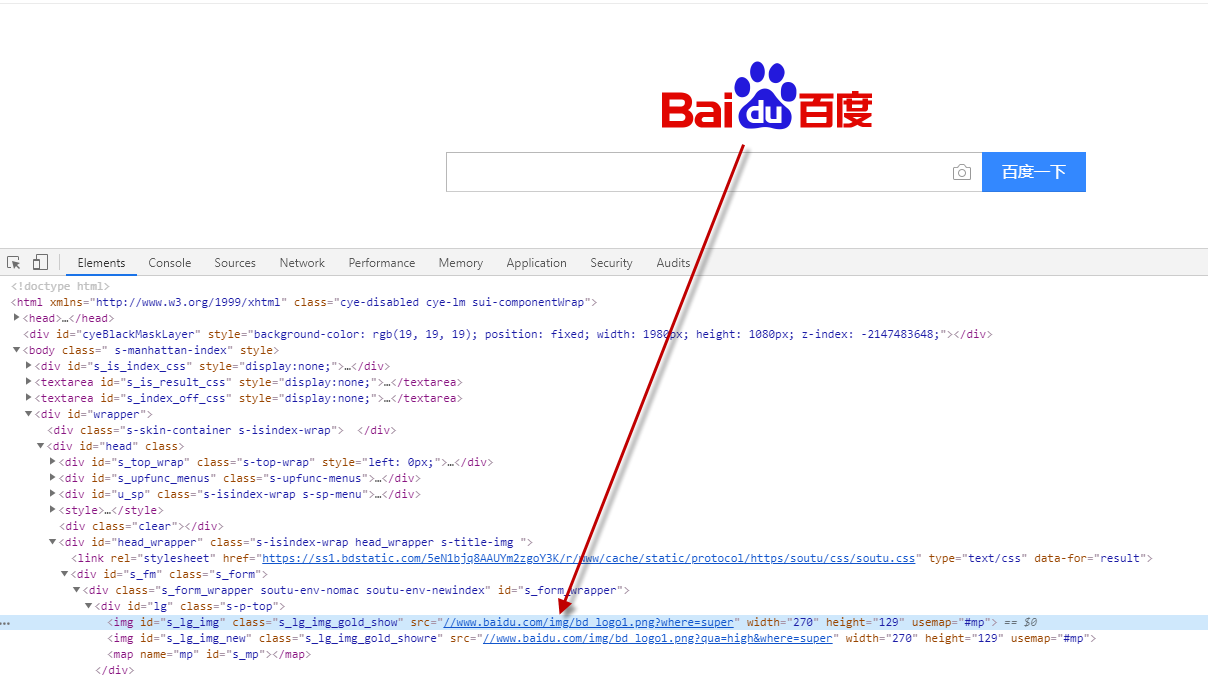
图片地址如下:
https://www.baidu.com/img/bd_logo1.png?where=super
代码:
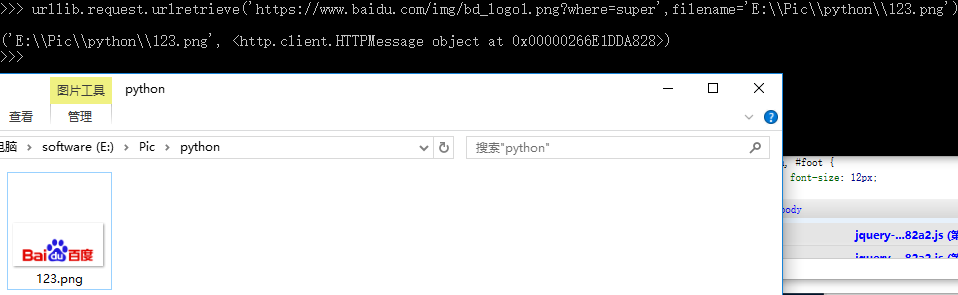
urllib.request.urlretrieve('https://www.baidu.com/img/bd_logo1.png?where=super',filename='E:\\Pic\\python\\123.png')
效果如下,图片下载成功:
三:requests
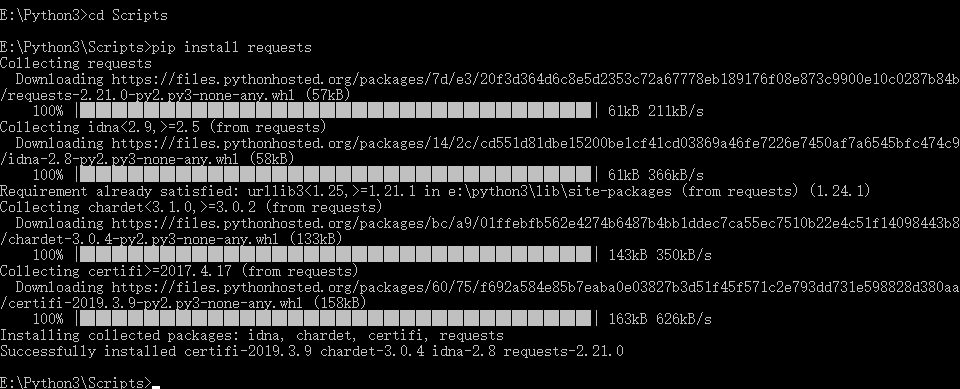
1.window 下requests安装:
查看python路径:

下载requests:
pip install requests
示例:向url发起get请求
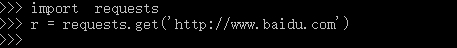
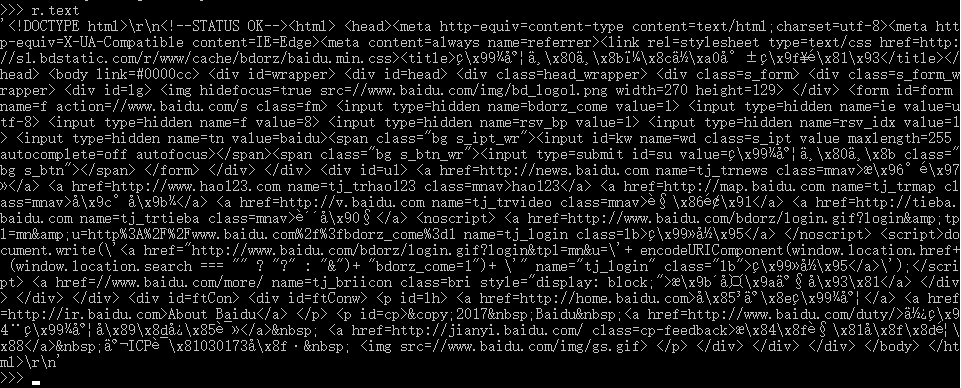
查看响应内容:
方法1:
响应内容 r.test
方法2:
二进制响应内容>>> print (r.content) 或 r.content
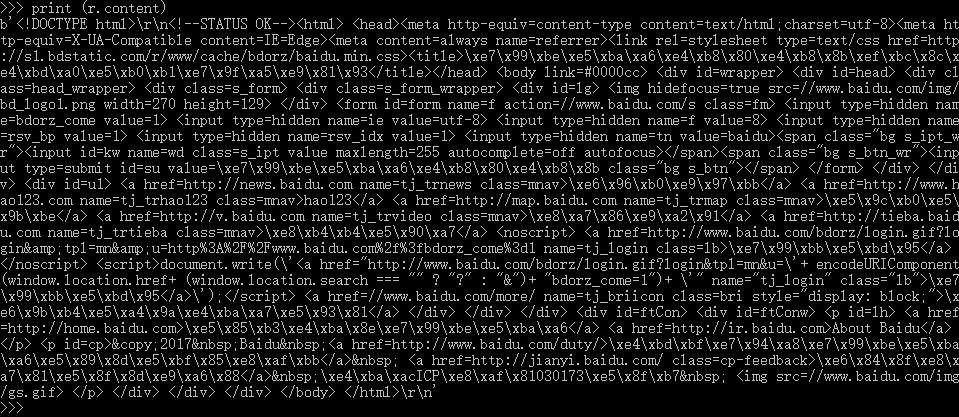
定制请求头:
url = 'http://www.baidu.con'
headers = {'content-type':'application/json'}
r = requests.get(url,headers=headers)
查看状态码:
r.status_code

查看响应头:
r.headers

查看Cookies:
r.cookies

timeout设置超时:
>>> requests.get('http://www.baidu.com',timeout=0.001)


【一】,python简单爬虫实现的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- Python 简单爬虫案例
Python 简单爬虫案例 import requests url = "https://www.sogou.com/web" # 封装参数 wd = input('enter a ...
- Python简单爬虫记录
为了避免自己忘了Python的爬虫相关知识和流程,下面简单的记录一下爬虫的基本要求和编程问题!! 简单了解了一下,爬虫的方法很多,我简单的使用了已经做好的库requests来获取网页信息和Beauti ...
- Python简单爬虫
爬虫简介 自动抓取互联网信息的程序 从一个词条的URL访问到所有相关词条的URL,并提取出有价值的数据 价值:互联网的数据为我所用 简单爬虫架构 实现爬虫,需要从以下几个方面考虑 爬虫调度端:启动爬虫 ...
- python简单爬虫一
简单的说,爬虫的意思就是根据url访问请求,然后对返回的数据进行提取,获取对自己有用的信息.然后我们可以将这些有用的信息保存到数据库或者保存到文件中.如果我们手工一个一个访问提取非常慢,所以我们需要编 ...
- python 简单爬虫(beatifulsoup)
---恢复内容开始--- python爬虫学习从0开始 第一次学习了python语法,迫不及待的来开始python的项目.首先接触了爬虫,是一个简单爬虫.个人感觉python非常简洁,相比起java或 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
- Python简单爬虫入门一
为大家介绍一个简单的爬虫工具BeautifulSoup BeautifulSoup拥有强大的解析网页及查找元素的功能本次测试环境为python3.4(由于python2.7编码格式问题) 此工具在搜索 ...
随机推荐
- spring-mybatis项目搭建(支持多数据源)
一.目录结构图 2.配置文件内容 db.properties: #oracle public oracle.driverClass=oracle.jdbc.driver.OracleDriver or ...
- 关于Python常用框架学习
我对Python不是特别熟悉,我仅仅只知道它在Web自动化领域挺牛逼的,还有爬虫.当然了,现在的人工智能和机器学习用到它也很多. 记得六月还是七月份的时候,那个时候,突然心血来潮就开始学起了Pytho ...
- 集合之ArrayList
一.ArrayList概述 ArrayList是实现List接口的动态数组,所谓动态就是它的大小是可变的.实现了所有可选列表操作,并允许包括 null 在内的所有元素.除了实现 List 接口外,此类 ...
- C#调试含有源代码的动态链接库遇见there is no source code available for the current location提示时的解决方案
C#调试含有源代码的动态链接库遇见there is no source code available for the current location提示时的解决方案: 1.首先试最常规的方法:Cle ...
- C#做一个简单的进行串口通信的上位机
C#做一个简单的进行串口通信的上位机 1.上位机与下位机 上位机相当于一个软件系统,可以用于接收数据.控制数据.即可以对接收到的数据直接发送操控命令来操作数据.上位机可以接收下位机的信号.下位机是 ...
- 文本处理三剑客之 grep/egrep
grep:文本过滤工具 支持BRE egrep: 支持ERE fgrep: 不支持正则 作用:根据用户指定的“模式”,对目标文本逐行进行匹配检查,打印匹配到的行 模式:由正则表达式字符及文本字符所编写 ...
- CentOS如何配置yum源
参考:http://blog.csdn.net/qingfenggege/article/details/80394564 1. yum 前端软件包管理器2. 基于RMP包管理,能够从指定的服务器自动 ...
- 一、用Delphi10.3 创建一条JSON数据
一.用Delphi10.3构造一个JSON数据,非常之容易,代码如下: uses System.JSON; procedure TForm1.Button1Click(Sender: TObject) ...
- Hbase的安装和基本使用
Hbase介绍 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行于H ...
- CTF-Bugku-分析-信息提取
CTF-Bugku-分析-信息提取 最近刷题的时候看到了这道比较有趣的题.而且网上也没找到wp,所以分享一下我的思路. 信息提取: 题目链接:http://ctf.bugku.com/challeng ...