模型融合策略voting、averaging、stacking
原文:https://zhuanlan.zhihu.com/p/25836678
1.voting
对于分类问题,采用多个基础模型,采用投票策略选择投票最多的为最终的分类。
2.averaging
对于回归问题,一方面采用简单平均法,另一方面采用加权平均法,加权平均法的思路:权值可以用排序的方法确定或者根据均方误差确定。
3.stacking
Stacking模型本质上是一种分层的结构,这里简单起见,只分析二级Stacking。假设我们有3个基模型M1、M2、M3。下面先看一种错误的训练方式:
【1】基模型M1,对训练集train训练,然后用于预测train和test的标签列,分别是P1,T1(对于M2和M3,重复相同的工作,这样也得到P2,T2,P3,T3):
【2】 分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2:
【3】 再用第二层的模型M4训练train2,预测test2,得到最终的标签列:
Stacking本质上就是这么直接的思路,但是这样肯定是不行的,问题在于P1的得到是有问题的,用整个训练集训练的模型反过来去预测训练集的标签,过拟合是非常非常严重的,因此现在的问题变成了如何在解决过拟合的前提下得到P1、P2、P3,这就变成了熟悉的节奏——K折交叉验证。我们以2折交叉验证得到P1为例,假设训练集为4行3列:
将其划分为两部分:
,
用traina训练模型M1,然后在trainb上进行预测得到preb3和pred4:
在trainb上训练模型M1,然后在traina上进行预测得到pred1和pred2:
然后把两个预测集进行拼接:
对于测试集T1的得到,有两种方法。注意到刚刚是2折交叉验证,M1相当于训练了2次,所以一种方法是每一次训练M1,可以直接对整个test进行预测,这样2折交叉验证后测试集相当于预测了2次,然后对这两列求平均得到T1。或者直接对测试集只用M1预测一次直接得到T1。P1、T1得到之后,P2、T2、P3、T3也就是同样的方法。理解了2折交叉验证,对于K折的情况也就理解也就非常顺利了。所以最终的代码是两层循环,第一层循环控制基模型的数目,每一个基模型要这样去得到P1,T1,第二层循环控制的是交叉验证的次数K,对每一个基模型,会训练K次最后拼接得到P1,取平均得到T1。
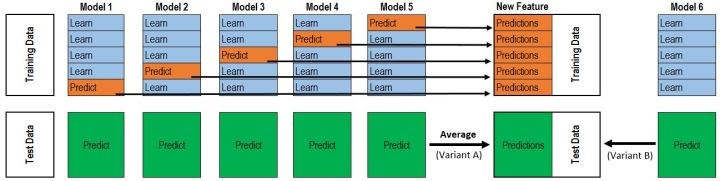
该图是一个基模型得到P1和T1的过程,采用的是5折交叉验证,所以循环了5次,拼接得到P1,测试集预测了5次,取平均得到T1。而这仅仅只是第二层输入的一列/一个特征,并不是整个训练集。再分析作者的代码也就很清楚了。也就是刚刚提到的两层循环。
模型融合策略voting、averaging、stacking的更多相关文章
- 模型融合之blending和stacking
1. blending 需要得到各个模型结果集的权重,然后再线性组合. """Kaggle competition: Predicting a Biological Re ...
- 深度学习模型融合stacking
当你的深度学习模型变得很多时,选一个确定的模型也是一个头痛的问题.或者你可以把他们都用起来,就进行模型融合.我主要使用stacking和blend方法.先把代码贴出来,大家可以看一下. import ...
- 模型融合——stacking原理与实现
一般提升模型效果从两个大的方面入手 数据层面:数据增强.特征工程等 模型层面:调参,模型融合 模型融合:通过融合多个不同的模型,可能提升机器学习的性能.这一方法在各种机器学习比赛中广泛应用, 也是在比 ...
- 深度学习模型stacking模型融合python代码,看了你就会使
话不多说,直接上代码 def stacking_first(train, train_y, test): savepath = './stack_op{}_dt{}_tfidf{}/'.format( ...
- 谈谈模型融合之一 —— 集成学习与 AdaBoost
前言 前面的文章中介绍了决策树以及其它一些算法,但是,会发现,有时候使用使用这些算法并不能达到特别好的效果.于是乎就有了集成学习(Ensemble Learning),通过构建多个学习器一起结合来完成 ...
- 在Caffe中实现模型融合
模型融合 有的时候我们手头可能有了若干个已经训练好的模型,这些模型可能是同样的结构,也可能是不同的结构,训练模型的数据可能是同一批,也可能不同.无论是出于要通过ensemble提升性能的目的,还是要设 ...
- Gluon炼丹(Kaggle 120种狗分类,迁移学习加双模型融合)
这是在kaggle上的一个练习比赛,使用的是ImageNet数据集的子集. 注意,mxnet版本要高于0.12.1b2017112. 下载数据集. train.zip test.zip labels ...
- 基于sklearn的 BaseEstimator开发接口:模型融合Stacking
转载:https://github.com/LearningFromBest/CMB-credit-card-department-prediction-of-purchasing-behavior- ...
- 成功的GIT开发分支模型和策略
详细图文并茂以及git flow工具解释参考: http://danielkummer.github.io/git-flow-cheatsheet/index.zh_CN.html 原文地址:http ...
随机推荐
- 2019.1.7 Russia temperature control demo
1layout 2导出Gerber 做钢网 3刷锡膏 4.1调SMT程序: a摆元件,写P/N位置 b定位检测点 4.2手贴元件 手别抖! 5过炉 温度270 6插件PCBA 做载板最方便,手插焊接也 ...
- Alpha阶段敏捷冲刺---Day4
一.Daily Scrum Meeting照片 二.今天冲刺情况反馈 今天我们上完课后在禹洲楼教室外进行我们的每日立会.开会的内容主要是对昨天遇到的困难做了一些交流,并且定下今天的任务是完成排行榜界面 ...
- SWIFT中获取当前经伟度
很多的APP中都会用到用户的当前位置信息,本文将实现这个小功能 import UIKit import CoreLocation //添加引用 class ViewController: UIView ...
- 应用“PUSH推送”的5个真相和5个误区
真相一:用户厌烦的并不是推送功能本身 针对如何看待推送功能这一问题,对1万名用户进行了问卷调查,结果表明80%的用户表示不会拒绝推送功能.各个年龄段方面没有太大的差别,但女性用户更容易受个人兴趣和 ...
- 了解dto概念,什么是DTO
了解dto概念 此博文收集整理了一些主流的文章对于DTO模式的解读,他们大体相似而又各有所不同.对于设计模式的解读也是一个仁者见仁智者见智的事情,不过设计模式往往都是前辈们在遇到一类特定的问题下而 ...
- STM32 用c语言控制4个LED灯从左向右无限流动
在用c语言写LED流水灯的前提条件是配置好其他环境,这里我就不说环境了, 想让LED灯无限循环时,首先要想到的是无限循环函数,我这里利用的是for函数 无限循环. #include "stm ...
- LOJ2538. 「PKUWC2018」Slay the Spire【组合数学】
LINK 思路 首先因为式子后面把方案数乘上了 所以其实只用输出所有方案的攻击力总和 然后很显然可以用强化牌就尽量用 因为每次强化至少把下面的牌翻一倍,肯定是更优的 然后就只有两种情况 强化牌数量少于 ...
- 了解 .NET 的默认 TaskScheduler 和线程池(ThreadPool)设置,避免让 Task.Run 的性能急剧降低
.NET Framework 4.5 开始引入 Task.Run,它可以很方便的帮助我们使用 async / await 语法,同时还使用线程池来帮助我们管理线程.以至于我们编写异步代码可以像编写同步 ...
- beautiful number 数位DP codeforces 55D
题目链接: http://codeforces.com/problemset/problem/55/D 数位DP 题目描述: 一个数能被它每位上的数字整除(0除外),那么它就是beautiful nu ...
- 2012年东京区域赛 UVAlive6182~6191
暑假训练场 A(UVAL6182). 凯神看了敲掉的题目,还没有看过 #include <iostream> #include <memory.h> using namespa ...