模型融合策略voting、averaging、stacking
原文:https://zhuanlan.zhihu.com/p/25836678
1.voting
对于分类问题,采用多个基础模型,采用投票策略选择投票最多的为最终的分类。
2.averaging
对于回归问题,一方面采用简单平均法,另一方面采用加权平均法,加权平均法的思路:权值可以用排序的方法确定或者根据均方误差确定。
3.stacking
Stacking模型本质上是一种分层的结构,这里简单起见,只分析二级Stacking。假设我们有3个基模型M1、M2、M3。下面先看一种错误的训练方式:
【1】基模型M1,对训练集train训练,然后用于预测train和test的标签列,分别是P1,T1(对于M2和M3,重复相同的工作,这样也得到P2,T2,P3,T3):
【2】 分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2:
【3】 再用第二层的模型M4训练train2,预测test2,得到最终的标签列:
Stacking本质上就是这么直接的思路,但是这样肯定是不行的,问题在于P1的得到是有问题的,用整个训练集训练的模型反过来去预测训练集的标签,过拟合是非常非常严重的,因此现在的问题变成了如何在解决过拟合的前提下得到P1、P2、P3,这就变成了熟悉的节奏——K折交叉验证。我们以2折交叉验证得到P1为例,假设训练集为4行3列:
将其划分为两部分:
,
用traina训练模型M1,然后在trainb上进行预测得到preb3和pred4:
在trainb上训练模型M1,然后在traina上进行预测得到pred1和pred2:
然后把两个预测集进行拼接:
对于测试集T1的得到,有两种方法。注意到刚刚是2折交叉验证,M1相当于训练了2次,所以一种方法是每一次训练M1,可以直接对整个test进行预测,这样2折交叉验证后测试集相当于预测了2次,然后对这两列求平均得到T1。或者直接对测试集只用M1预测一次直接得到T1。P1、T1得到之后,P2、T2、P3、T3也就是同样的方法。理解了2折交叉验证,对于K折的情况也就理解也就非常顺利了。所以最终的代码是两层循环,第一层循环控制基模型的数目,每一个基模型要这样去得到P1,T1,第二层循环控制的是交叉验证的次数K,对每一个基模型,会训练K次最后拼接得到P1,取平均得到T1。
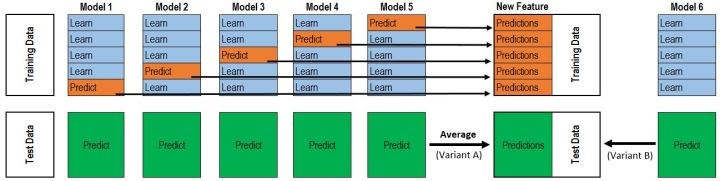
该图是一个基模型得到P1和T1的过程,采用的是5折交叉验证,所以循环了5次,拼接得到P1,测试集预测了5次,取平均得到T1。而这仅仅只是第二层输入的一列/一个特征,并不是整个训练集。再分析作者的代码也就很清楚了。也就是刚刚提到的两层循环。
模型融合策略voting、averaging、stacking的更多相关文章
- 模型融合之blending和stacking
1. blending 需要得到各个模型结果集的权重,然后再线性组合. """Kaggle competition: Predicting a Biological Re ...
- 深度学习模型融合stacking
当你的深度学习模型变得很多时,选一个确定的模型也是一个头痛的问题.或者你可以把他们都用起来,就进行模型融合.我主要使用stacking和blend方法.先把代码贴出来,大家可以看一下. import ...
- 模型融合——stacking原理与实现
一般提升模型效果从两个大的方面入手 数据层面:数据增强.特征工程等 模型层面:调参,模型融合 模型融合:通过融合多个不同的模型,可能提升机器学习的性能.这一方法在各种机器学习比赛中广泛应用, 也是在比 ...
- 深度学习模型stacking模型融合python代码,看了你就会使
话不多说,直接上代码 def stacking_first(train, train_y, test): savepath = './stack_op{}_dt{}_tfidf{}/'.format( ...
- 谈谈模型融合之一 —— 集成学习与 AdaBoost
前言 前面的文章中介绍了决策树以及其它一些算法,但是,会发现,有时候使用使用这些算法并不能达到特别好的效果.于是乎就有了集成学习(Ensemble Learning),通过构建多个学习器一起结合来完成 ...
- 在Caffe中实现模型融合
模型融合 有的时候我们手头可能有了若干个已经训练好的模型,这些模型可能是同样的结构,也可能是不同的结构,训练模型的数据可能是同一批,也可能不同.无论是出于要通过ensemble提升性能的目的,还是要设 ...
- Gluon炼丹(Kaggle 120种狗分类,迁移学习加双模型融合)
这是在kaggle上的一个练习比赛,使用的是ImageNet数据集的子集. 注意,mxnet版本要高于0.12.1b2017112. 下载数据集. train.zip test.zip labels ...
- 基于sklearn的 BaseEstimator开发接口:模型融合Stacking
转载:https://github.com/LearningFromBest/CMB-credit-card-department-prediction-of-purchasing-behavior- ...
- 成功的GIT开发分支模型和策略
详细图文并茂以及git flow工具解释参考: http://danielkummer.github.io/git-flow-cheatsheet/index.zh_CN.html 原文地址:http ...
随机推荐
- UIViewController简述
一.View Controller Classes 二.自定义UIVIewController 1.创建 a)nib文件 [cpp] view plaincopyprint? - (BOOL)ap ...
- E - An Awful Problem 求两段时间内满足条件的天数//lxm
In order to encourage Hiqivenfin to study math, his mother gave him a sweet candy when the day of th ...
- 新手小白Linux(Centos6.5)部署java web项目(总)
一.准备 1.linux centos版本的相关命令操作,千万别找ubuntu的,好多命令都不一样,新手小白我傻傻不知道硬是浪费了一天的时间……(百度百科linux版本了解一下) 2.远程登录: P ...
- 2.3 linux中的信号分析 阻塞、未达
信号的阻塞.未达: linux中进程1向进程2发送信号,要经过内核,内核会维护一个进程对某个信号的状态,如下图所示: 当进程1向进程2发送信号时,信号的传递过程在内核中是有状态的,内核首先要检查这个信 ...
- 清除的通用样式 css
/*公共样式--开始*/ html, body, div, ul, li, h1, h2, h3, h4, h5, h6, p, dl, dt, dd, ol, form, input, textar ...
- opencv-python教程学习系列12-图像阈值
前言 opencv-python教程学习系列记录学习python-opencv过程的点滴,本文主要介绍图像阈值/二值化,坚持学习,共同进步. 系列教程参照OpenCV-Python中文教程: 系统环境 ...
- 【图文教程】win7+VMware8.0+CentOS6.4 NAT上网
在win7下面安装VM8.0,里面又安装多个虚拟机,各个虚拟机之间可以互相访问,同时虚拟机可以直接访问外网上网,win7要ping通个虚拟机中的系统.这种方式就使用NAT模式,开启VMware Net ...
- CentOS安装crontab 定时备份文件夹
一. 编写脚本编写一个脚本文件,使脚本可以执行备份命令. 例如,将文件目录 /home/backups/balalala 备份到/home目录下,并压缩.1. 创建脚本命令格式: touch 路径/文 ...
- hdu1301 Jungle Roads 最小生成树
The Head Elder of the tropical island of Lagrishan has a problem. A burst of foreign aid money was s ...
- js操作链接url
使用js对当前的URL进行操作,可以使用内置对象window.location: window.location有以下属性: window.location.href:取得当前地址栏中的完整URL,可 ...