斯坦福深度学习与nlp第四讲词窗口分类和神经网络
http://www.52nlp.cn/%E6%96%AF%E5%9D%A6%E7%A6%8F%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B8%8Enlp%E7%AC%AC%E5%9B%9B%E8%AE%B2%E8%AF%8D%E7%AA%97%E5%8F%A3%E5%88%86%E7%B1%BB%E5%92%8C%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
斯坦福大学深度学习与自然语言处理第四讲:词窗口分类和神经网络
斯坦福大学在三月份开设了一门“深度学习与自然语言处理”的课程:CS224d: Deep Learning for Natural Language Processing,授课老师是青年才俊 Richard Socher,以下为相关的课程笔记。
第四讲:词窗口分类和神经网络(Word Window Classification and Neural Networks)
推荐阅读材料:
- [UFLDL tutorial]
- [Learning Representations by Backpropogating Errors]
- 第四讲Slides [slides]
- 第四讲视频 [video]
以下是第四讲的相关笔记,主要参考自课程的slides,视频和其他相关资料。
本讲概览
- 分类问题背景
- 在分类任务中融入词向量
- 窗口分类和交叉熵误差推导技巧
- 一个单层的神经网络
- 最大间隔损失和反向传播
分类问题定义
- 一般情况下我们会有一个训练模型用的样本数据集
{xi,yi}Ni=1{xi,yi}i=1N
- 其中xixi是输入,例如单词(标识或者向量),窗口内容,句子,文档等
- yiyi是我们希望预测的分类标签,例如情绪指标,命名实体,买卖决定等
分类问题直窥
- 训练集:{xi,yi}Ni=1{xi,yi}i=1N
- 一个简单的例子
- 一个固定的2维词向量分类
- 使用逻辑回归
- ->线性决策边界->
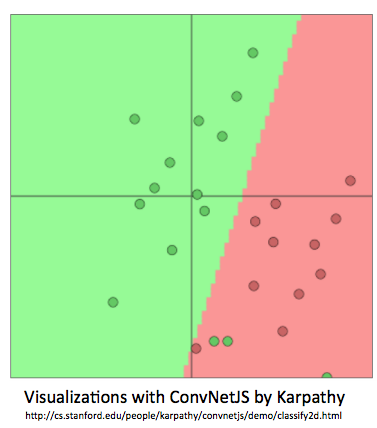
- 从机器学习的角度来看:假设x是固定的,仅仅更新的是逻辑回归的权重W意味着仅仅修改的是决策边界
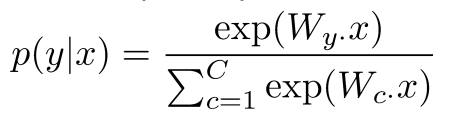
分类问题符号定义
- 一般的机器学习问题: 仅仅更新逻辑回归的权重意味着仅仅更新的是决策边界
- 数据集{xi,yi}Ni=1{xi,yi}i=1N的损失函数
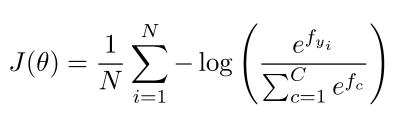
- 其中对于每一个数据对(xi,yi)(xi,yi):
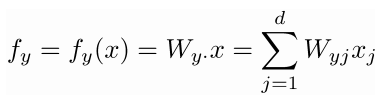
- 我们可以将f写成矩阵符号形式: f=Wxf=Wx
分类问题:正则化
- 通常情况下任何一个数据集上完整的损失函数都会包含一个针对所有参数的正则化因子
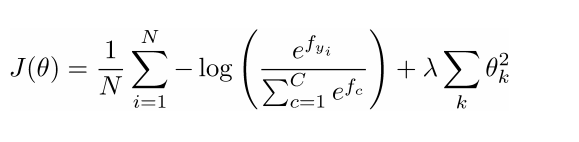
- 正则化可以防止过多的特征导致的过拟合问题(另一种解决方案是一个强有力/深度模型)

- 上图中x轴代表了更强有力的模型后者更多的模型迭代次数
- 蓝色代表训练集误差,红色代表测试集误差
机器学习优化问题
- 对于一般的机器学习问题θθ常常只包含了W的列数:
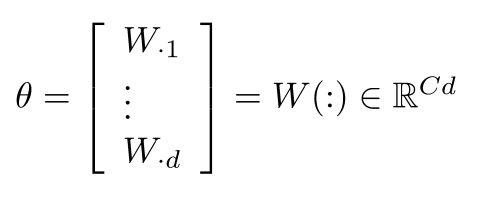
- 所以我们仅仅更新决策边界
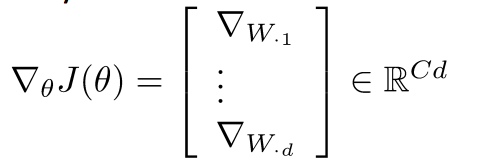
引入词向量
- 在深度学习中既要学习W也要学习词向量x:
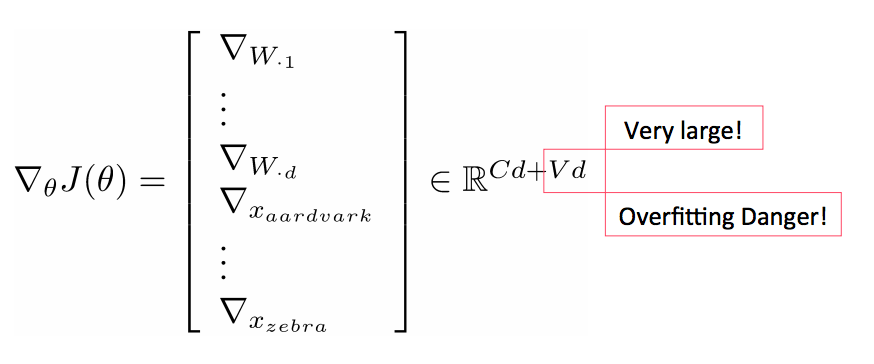
重新训练词向量会丧失泛化能力
- 例子:针对电影评价情感数据(movie review sentiment)训练逻辑回归模型,在训练集里我们有单词"TV"和"telly"
- 在测试集里我们有单词“television”
- 原本它们是相似的单词(来自于已经训练的词向量模型)
- 当我们重新训练的时候会发生什么?
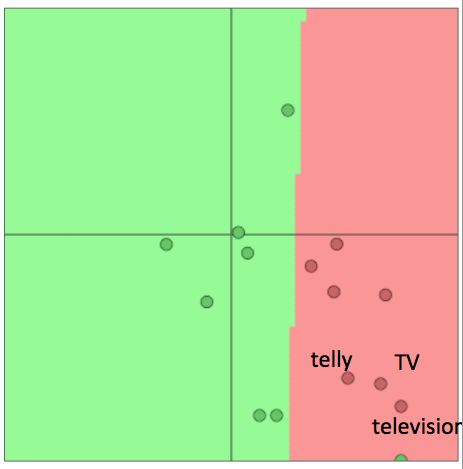
重新训练词向量会丧失泛化能力续
- 当我们重新训练词向量模型的时候会发生什么?
- 在训练集中的单词会被重新安排到合适的位置
- 在已经训练的词向量模型中但是不在训练集中的单词将保留在原来的位置
- 对于上例, "TV"和"telly"会被重新安排,而"television"则保留在原位,尴尬的事情就发生了:
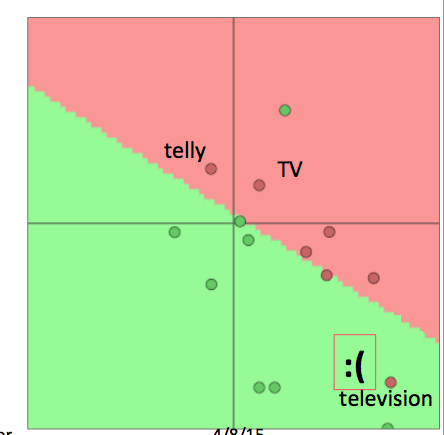
- 总之:
- 如果你只有一个很小的训练集,不要训练词向量模型
- 如果你有一个足够大的训练集,那么对于相应的任务来说训练词向量模型是有益的
词向量概念回顾
- 词向量矩阵L也被称为查询表
- Word vectors(词向量)= word embeddings(词嵌入) = word representations(mostly)
- 类似于word2vec或者GloVe的方法得到:
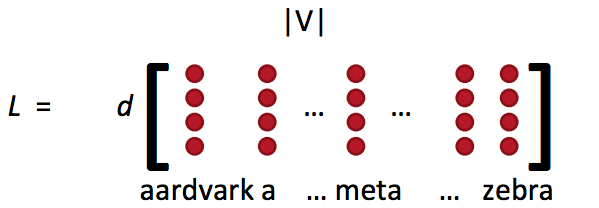
- 这就是词特征xwordxword
- 通常通过词向量矩阵L和one-hot向量e相乘得到单个的词向量:
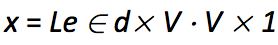
窗口分类
- 单个单词的分类任务很少
- 在上下文中解决歧义问题
- 例子1:

- 例子2:

- 思路:将对一个单词进行分类的问题扩展到对其临近词和上下文窗口进行分类
- 例如命名实体问题有4个类别:人名,地名,机构名和其他
- 已经有很多方法在尝试对一个上下文中的单词进行分类,例如将窗口内的单词(向量)进行平均化处理,但是这样会失去位置信息
- 以下介绍一种常用的对窗口(上下文)中单词进行分类的方法
- 对于窗口中的单词打上标签同时把它前后的单词向量进行拼接然后训练一个分类器
- 例子:对于一个句子上下文中的"Paris"进行分类,窗口长度为2

- 结果得到的窗口向量 xwindow=x∈R5dxwindow=x∈R5d , 是一个列向量
简单的窗口分类器: Softmax
- 在得到窗口向量x=xwindowx=xwindow的情况下,我们可以和之前一样使用softmax分类器

- 但是如何更新词向量?
- 简单的回答:和之前一样进行求导
- 更长的回答:让我们一起来一步一步进行推导
- 定义:
- yˆy^: softmax 概率输出向量
- t: 目标概率分布
- f=Wx∈Rcf=Wx∈Rc, 其中fcfc是f向量的第c个因子
- 第一次看到是不是觉得很难,下面给出一下提示(tips)
更新拼接的词向量:Tips
- 提示1:仔细定义变量和跟踪它们的维度

- 提示2:懂得链式法则(chain rule)并且记住在哪些变量中含有其他变量

- 提示3:对于softmax中求导的部分:首先对fcfc当c=y(正确的类别)求导,然后对fcfc当c≠yc≠y(其他所有非正确类别)求导
- 提示4:当你尝试对f中的一个元素求导时,试试能不能在最后获得一个梯度包含的所有的偏导数

- 提示5:为了你之后的处理不会发疯,想象你所有的结果处理都是向量之间的操作,所以你应该定义一些新的,单索引结构的向量

- 提示6:当你开始使用链式法则时,首先进行显示的求和(符号),然后再考虑偏导数,例如xixi or WijWij的偏导数
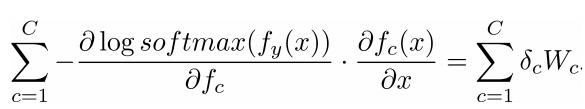
- 提示7:为了避免之后更复杂的函数(形式),确保知道变量的维度,同时将其简化为矩阵符号运算形式
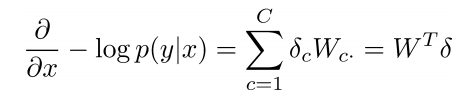
- 提示8:如果你觉得公式不清晰的话,把它写成完整的加和形式
更新拼接的词向量
- 窗口向量梯度的维度是多少?

- X是整个拼接的词向量窗口,5倍的d维度向量,所以对于x的求导后依然有相同的向量维度(5d)

- 对整个窗口向量的更新和梯度推导可以简单的分解到对每一个词向量的推导:
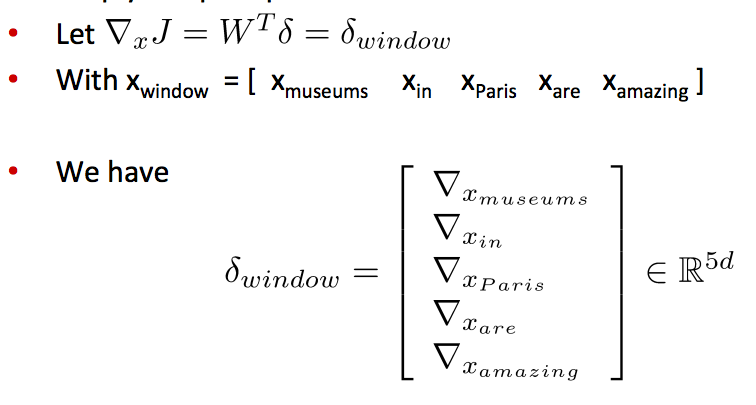
- 这将保留词向量的原始位置信息有助于一些NLP任务,例如命名实体识别
- 例如,模型将会学习到出现在中心词前面的xinxin常常表示中心词是一个地名(location)
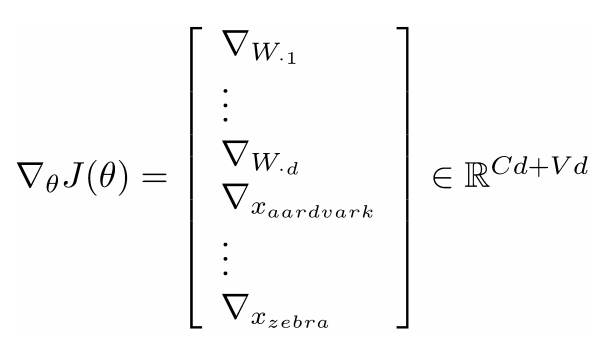
在训练窗口向量时丢失了什么信息?
- 梯度J相对于softmax权重W
- 步骤相似,但是先写出偏导数WijWij
- 然后我们就有了完整的:
矩阵实现的一些注解
- 在softmax中有两个代价昂贵的运算: 矩阵运算 f = Wx 和 exp指数运算
- 在做同样的数学运算时for循环永远没有矩阵运算有效
- 样例代码 -->
- 遍历词向量 VS 将它们拼接为一个大的矩阵 然后分别和softmax的权重矩阵相乘

- 运行结果:
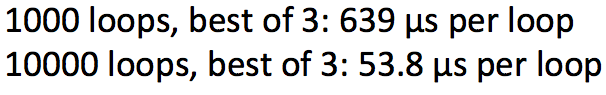
- 结果证明矩阵相乘C×XC×X更有效
- 矩阵运算更优雅更棒
- 应该更多的去测试你的代码速度
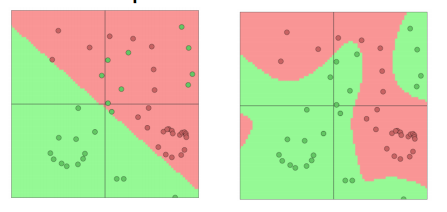
softmax(=逻辑回归)并不是强有力的
- softmax仅仅在原有的空间上给出线性决策边界
- 在少量的数据上(正则化)效果会不错
- 在大量的数据上效果会有限
- softmax仅仅给出线性决策边界举例:

神经网络更胜一筹
- 神经网络可以学习更复杂的函数和非线性决策边界
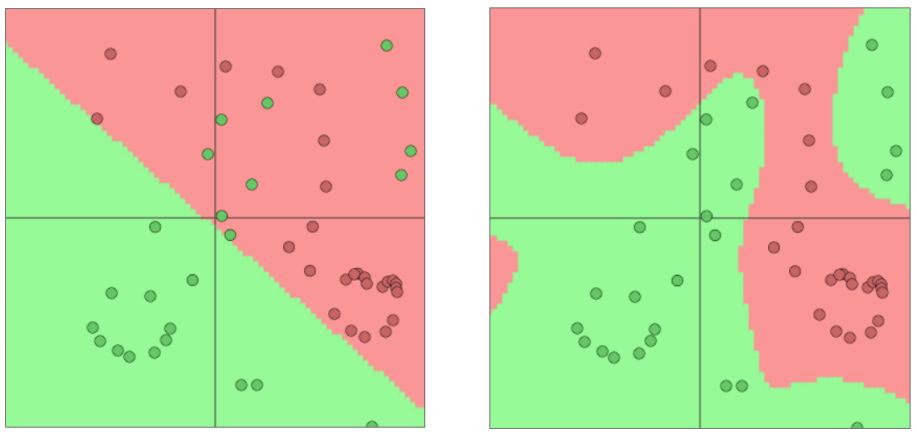
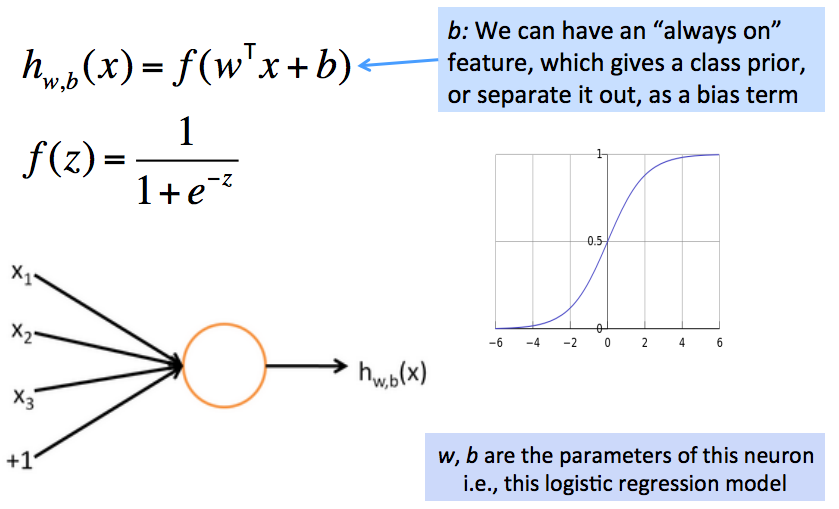
从逻辑回归到神经网络--神经网络解密
- 神经网络有自己的术语定义集,就像SVM一样
- 但是如果你了解softmax的运行机制,那你就已经了解了一个基本的神经元的运行机制
- 例子:一个神经元就是一个基础的运算单位,拥有n(3)个输入和一个输出,参数是W, b

一个神经元本质上是一个二元逻辑回归单元
一个神经网络等价于同时运行了很多逻辑回归单元
- 如果我们给一批逻辑回归函数一堆输入向量,我们就得到了一批输出向量...
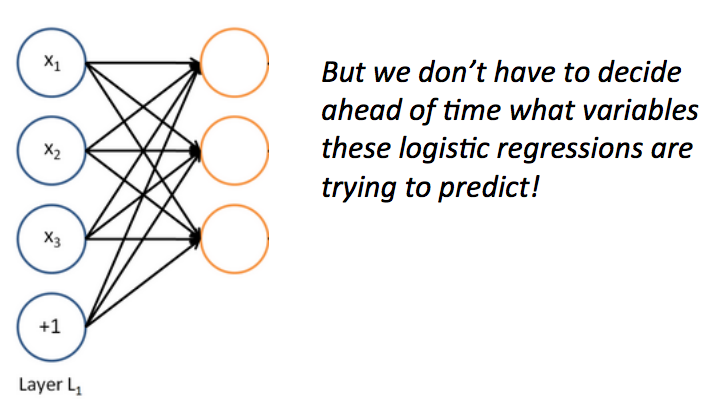
- 这些输出又可以作为其他逻辑回归函数的输入
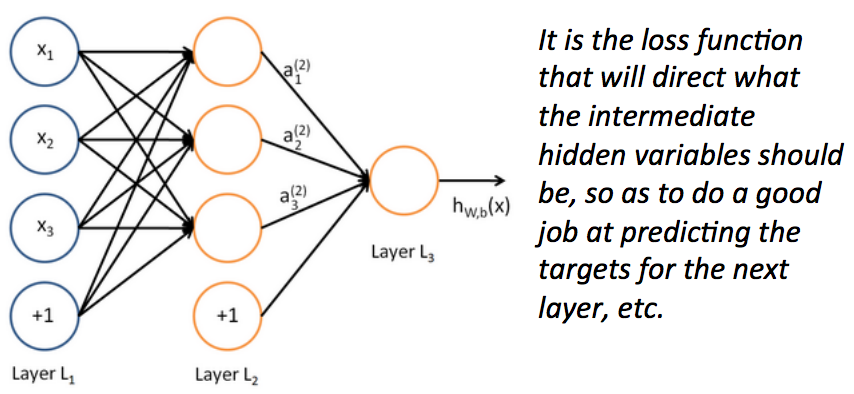
- 然后我们就有了多层神经网络
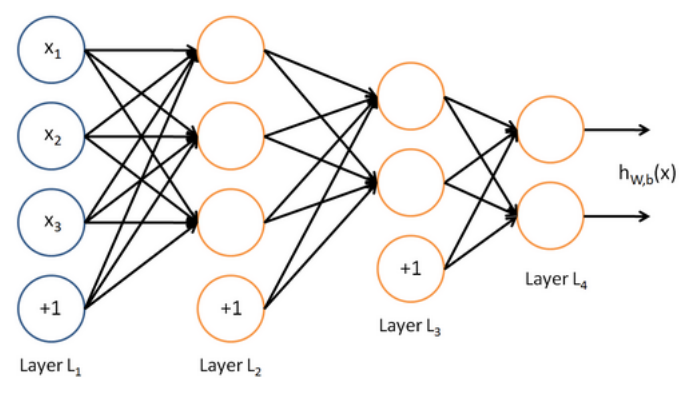
神经网络中单层的矩阵符号表示
- 我们有:
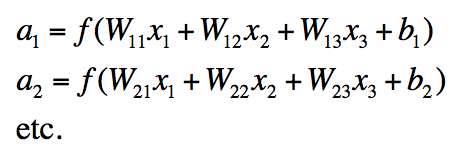
- 表示成矩阵符号形式:
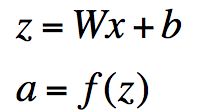
- 其中f应用的是element-wise规则:
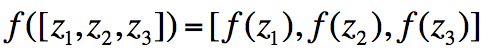

为什么需要非线性的f
- 例子:函数逼近,例如回归或者分类问题

- 没有非线性函数,深度神经网络相对于线性变换价值不大
- 其他的层次会被编译压缩为单个的线性变换: W1W2X=WXW1W2X=WX
- 有了更多的层次,它们可以逼近更复杂的函数
一个更牛的窗口分类器
- 基于神经网络进行修正

- 单个(神经网络)层是一个线性层(函数)和非线性函数的组合
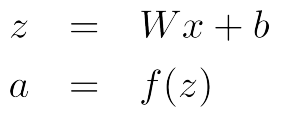
- 神经网络激活函数αα可以用来计算一些函数
- 例如,一个softmax概率分布或者一个没有归一化的打分函数可以是这样的:
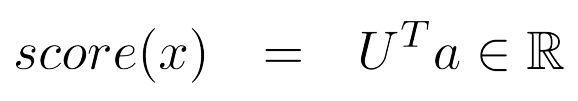
总结:前馈网络计算
- 通过一个三层神经网络计算这个窗口向量的得分:s = score(museums in Paris are amazing)
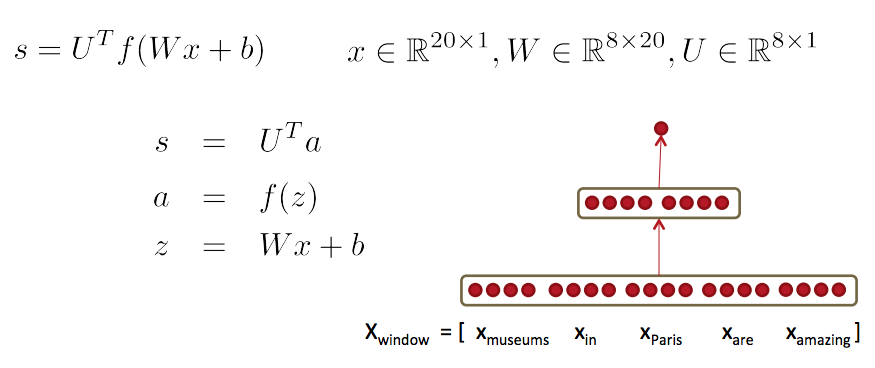
下一讲
- 训练一个基于窗口(向量)的神经网络模型
- 进行更复杂的深度推导-->反向传播算法
- 这样我们就有了所有的基础工具去学习一个更复杂的深度模型:)
注:原创文章,转载请注明出处及保留链接“我爱自然语言处理”:http://www.52nlp.cn
斯坦福深度学习与nlp第四讲词窗口分类和神经网络的更多相关文章
- 回望2017,基于深度学习的NLP研究大盘点
回望2017,基于深度学习的NLP研究大盘点 雷锋网 百家号01-0110:31 雷锋网 AI 科技评论按:本文是一篇发布于 tryolabs 的文章,作者 Javier Couto 针对 2017 ...
- 转载:深度学习在NLP中的应用
之前研究的CRF算法,在中文分词,词性标注,语义分析中应用非常广泛.但是分词技术只是NLP的一个基础部分,在人机对话,机器翻译中,深度学习将大显身手.这篇文章,将展示深度学习的强大之处,区别于之前用符 ...
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 深度学习与NLP简单应用
在深度学习中,文本分类的主要原型:Text label,坐边是输入端“X”,右边是输出端“Y”.行业baseline:用BoW(bag of words)表示sentences(如何将文本表达成一 ...
- AI - 深度学习之美十四章-概念摘要(8~14)
原文链接:https://yq.aliyun.com/topic/111 本文是对原文内容中部分概念的摘取记录,可能有轻微改动,但不影响原文表达. 08 - BP算法双向传,链式求导最缠绵 反向传播( ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
- 深度学习应用系列(四)| 使用 TFLite Android构建自己的图像识别App
深度学习要想落地实践,一个少不了的路径即是朝着智能终端.嵌入式设备等方向发展.但终端设备没有GPU服务器那样的强大性能,那如何使得终端设备应用上深度学习呢? 所幸谷歌已经推出了TFMobile,去年又 ...
- 深度学习解决NLP问题:语义相似度计算
在NLP领域,语义相似度的计算一直是个难题:搜索场景下query和Doc的语义相似度.feeds场景下Doc和Doc的语义相似度.机器翻译场景下A句子和B句子的语义相似度等等.本文通过介绍DSSM.C ...
- AI - 深度学习之美十四章-概念摘要(1~7)
原文链接:https://yq.aliyun.com/topic/111 本文是对原文内容中部分概念的摘取记录,可能有轻微改动,但不影响原文表达. 01 - 一入侯门"深"似海,深 ...
随机推荐
- 2013-2014 ACM-ICPC, NEERC, Southern Subregional Contest Problem I. Plugs and Sockets 费用流
Problem I. Plugs and Sockets 题目连接: http://www.codeforces.com/gym/100253 Description The Berland Regi ...
- hdu 5831 Rikka with Parenthesis II 线段树
Rikka with Parenthesis II 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5831 Description As we kno ...
- FCKeditor如何升级CKEditor及使用方法
之前编辑器用的是FCKeditor,因为项目原因需要升级为最新版本4.2.2,发现是已经更名为CKEditor. 百度了一下,据官方的解释,CK是对FCK的代码的完全重写. 项目环境是asp.net的 ...
- dubbox REST服务使用fastjson替换jackson
上一节讲解了resteasy如何使用fastjson来替换默认的jackson,虽然dubbox内部采用的就是resteasy,但是大多数情况下,dubbox服务是一个独立的app,并不需要以war包 ...
- 关于java中的锁(转)
对于锁一直处于比较模糊的状态,最近一天晚上偶然想看看,就翻了几本书,然后弄明白了一些概念,有一些仍然没明白,例如AQS,先把搞明白的记录一下吧. 什么是线程安全? 当多个线程访问一个对象时,如果不用考 ...
- SWD and JTAG selection mechanism
SWD and JTAG selection mechanism SWJ-DP enables either an SWD or JTAG protocol to be used on the deb ...
- MySQL编码latin1转utf8
mysql移植含有中文的数据时,很容易出现乱码问题.很多是在从mysql4.x向mysql5.x移植的时候出现.mysql的缺省字符集是 latin1,在使用mysql4.x的时候,很多人都是用的la ...
- Win10正式版开机慢怎么办 开机黑屏时间长怎么办
升级Win10正式版后开机速度慢.黑屏时间长怎么解决呢?其实我重要是由Win10正式版所提供的“快速启动”功能与电脑显卡驱动.电源管理驱动不兼容所造成的.下面就与大家分享一下针对Win10正式版开机速 ...
- Windows XP UDF 2.5 补丁,播放蓝光ISO光盘必备
蓝光光盘的文件系统是UDF2.5,Windows XP及以下的操作系统默认不能支持这个文件系统.当我们在XP系统中使用蓝光光盘或蓝光ISO文件时,就会提示“Windows不能从此盘读取,此盘可能已损坏 ...
- C#中的Hashtable
richTextBox1.Text = ""; Hashtable ht = new Hashtable(); ht.Add("); ht.Add("); ht ...