从零自学Hadoop(18):Hive的CLI和JDBC
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们对hive的数据导出,以及集群Hive数据的迁移进行描述。了解到了基本的hive导出操作。这里,我们将对hive的CLI及JDBC这些实用性很强的两个方便进行简要的介绍。
下面我们开始介绍hive的CLI和JDBC。
Hive CLI(old CLI)
一:说明
在0.11之前只有Hive CLI,他需要安装Hive Client才能使用。是一个重量级的命令行工具。连接的服务器是HiveServer1。
二:语法:
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
-h <hostname> Connecting to Hive Server on remote host
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-p <port> Connecting to Hive Server on port number
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)三:官网例子1
$HIVE_HOME/bin/hive -e 'select a.col from tab1 a'四:官网例子2
运行脚本文件
$HIVE_HOME/bin/hive -f /home/my/hive-script.sql
Beeline CLI(new CLI)
一:介绍
为了使得CLI轻量化,后来Hive做出了Beeline和HiveServer2。Beeline是一个基于JDBC的SQLLine CLI。
二:官网例子
bin/beeline
!connect jdbc:hive2://localhost:10000 scott tiger org.apache.hive.jdbc.HiveDriver三:实战
hiveserver2的默认端口是10000。
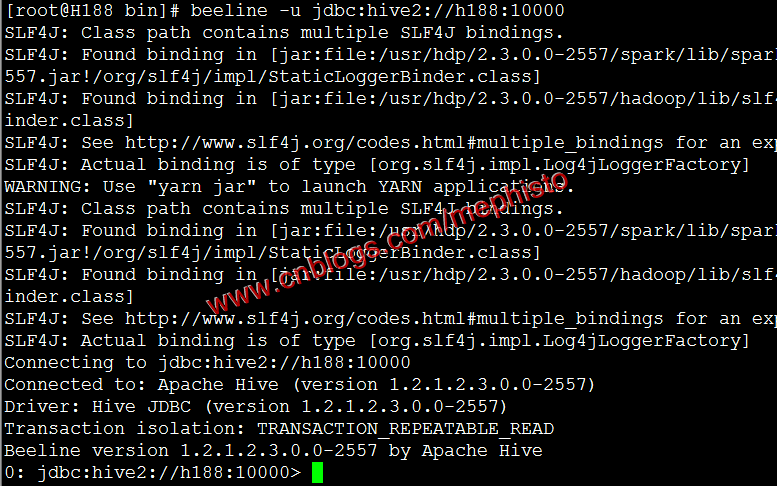
beeline -u jdbc:hive2://h188:10000
查看有哪些表。
show tables;
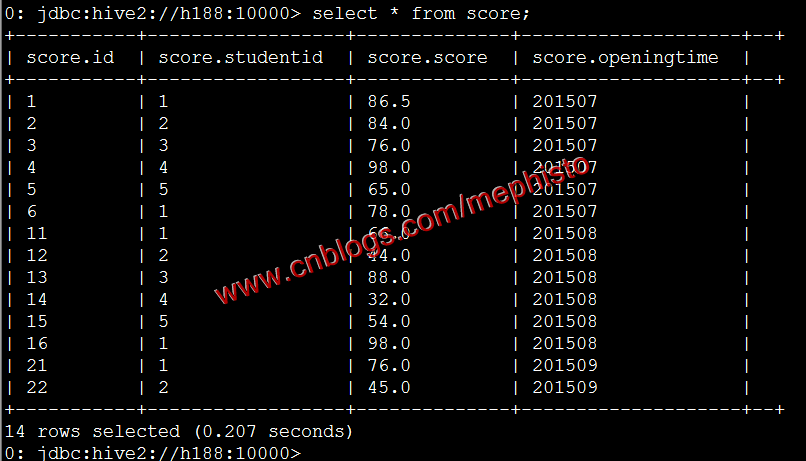
这里可以看到我们在上面几篇测试的时候的表score,score1,score2,我们查下score的数据。
select * from score;

JDBC
一:介绍
我们可以在代码中通过jdbc连接hive。这样在实际运用场景中就很方便,很原有的非分布式计算的开发方式基本类似,具有很强的适用性。
二:新建工程
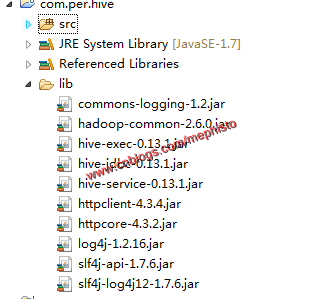
新建工程com.per.hive
三:引入包
版本根据自己使用hadoop集群而定
commons-logging-1.2.jar
hadoop-common-2.6..jar
hive-exec-0.13..jar
hive-jdbc-0.13..jar
hive-service-0.13..jar
httpclient-4.3..jar
httpcore-4.3..jar
log4j-1.2..jar
slf4j-api-1.7..jar
slf4j-log4j12-1.7..jar
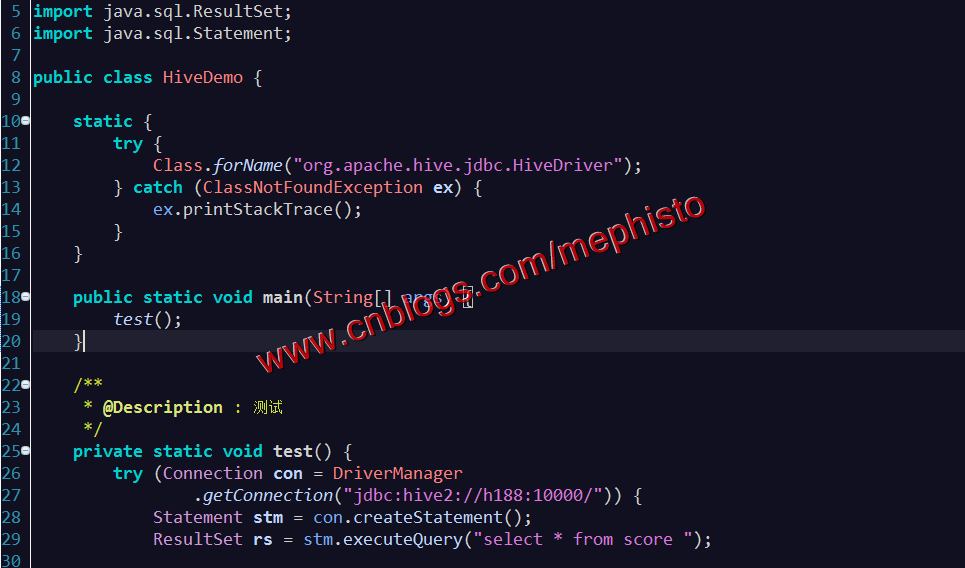
四:添加类HiveDemo
添加HiveDriver
static {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
} catch (ClassNotFoundException ex) {
ex.printStackTrace();
}
}添加test()方法
/**
* @Description : 测试
*/
private static void test() {
try (Connection con = DriverManager
.getConnection("jdbc:hive2://h188:10000/")) {
Statement stm = con.createStatement();
ResultSet rs = stm.executeQuery("select * from score "); while (rs.next()) {
String info = rs.getString(1);
info += " " + rs.getString(2);
info += " " + rs.getString(3);
info += " " + rs.getString(4); System.out.println(info);
} } catch (Exception ex) {
ex.printStackTrace();
}
}调用
public static void main(String[] args) {
test();
}
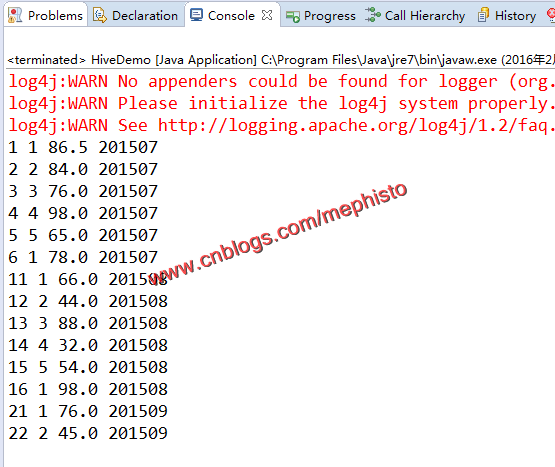
五:运行
运行,查看结果,可以看见,程序运行的结果与我们在Beeline命令行查看的结果一致。
这样我们的Hive的CLI和JDBC告一段落。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。
Demo下载
https://github.com/sinodzh/HadoopExample/tree/master/2016/com.per.hive
系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
从零自学Hadoop(18):Hive的CLI和JDBC的更多相关文章
- 从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 从零自学Hadoop(01):认识Hadoop ...
- 从零自学Hadoop(14):Hive介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 本系列已 ...
- 从零自学Hadoop(15):Hive表操作
阅读目录 序 创建表 查看表 修改表 删除表 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceL ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- 从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录 序 将查询的结果写入文件系统 集群数据迁移一 集群数据迁移二 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephis ...
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
- 从零自学Hadoop(21):HBase数据模型相关操作下
阅读目录 序 变量 数据模型操作 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 ...
- 从零自学Hadoop(01):认识Hadoop
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 阅读目录 序 Hadoop 项目起源 优点 核心 ...
- 从零自学Hadoop(03):Linux准备上
阅读目录 序 检查列表 常用Linux命令 搭建环境 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Sou ...
随机推荐
- js文章列表的树形结构输出
文章表设计成这样了 后端直接给了无任何处理的json数据,现在要前端实现树形结构的输出,其实后端处理更简单写,不过既然来了就码出来 var doclist = [{ "id": 1 ...
- 03.Web大前端时代之:HTML5+CSS3入门系列~H5功能元素
Web大前端时代之:HTML5+CSS3入门系列:http://www.cnblogs.com/dunitian/p/5121725.html 2.功能元素 1.hgroup 对网页或区段(secti ...
- 带搜索的ComboBox
带搜索的ComboBox就是给ComboBox一个依赖属性的ItemSource,然后通过数据源中是否包含要查询的值,重新给ComboBox绑定数据源. public class EditComboB ...
- TortoiseGit:记住用户名和密码
1.背景: 我们在使用 tortoisegit 工具时会无可避免的经常性 pull 和 push,这时通常要输入用户名和密码,由于麻烦,就有人提出了记住用户名和密码的需求... ... 2.设置: [ ...
- Linux驱动开发—— IS_ENABLED
在閱讀Linux內核代碼的時候,會經常遇到下面的幾個宏函數: IS_ENABLED 這個宏最爲常見 IS_BUILTIN IS_MODULE IS_REACHABLE 這幾個宏函數是在文件inclu ...
- 判断js引擎是javascriptCore或者v8
来由 纯粹的无聊,一直在搜索JavaScriptCore和SpiderMonkey的一些信息,却无意中学习了如何在ios的UIWebView中判断其js解析引擎的方法: if (window.de ...
- 举个栗子学习JavaScript设计模式
目录 前言 创建型模式 单例模式 构造器+原型 简单工厂模式 工厂模式 创建型模式比较 结构性模式 模块模式 外观模式 混入模式 装饰模式 适配模式 行为型模式 观察者模式 中介者模式 命令模式 责任 ...
- C#:解决WCF中服务引用 自动生成代码不全的问题。
问题描述: 如下图:打叉的部分是引用不成功的部分 ,在web.config文件中没有自动添加其引用代码. 英文解释 在服务引用选择自己的项目的程序集就行了,如下图: 特别注意:这些程序集一定要在自己的 ...
- 【分布式】Zookeeper的服务器角色
一.前言 前一篇已经详细的讲解了Zookeeper的Leader选举过程,下面接着学习Zookeeper中服务器的各个角色及其细节. 二.服务器角色 2.1 Leader Leader服务器是Zook ...
- python中的str,unicode和gb2312
实例1: v1=u '好神奇的问题!?' type(v1)->unicode v1.decode("utf-8")# not work,because v1 is unico ...