从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们介绍了Hive的数据多种方式导入,这样我们的Hive就有了数据来源了,但有时候我们可能需要纯粹的导出,或者集群Hive数据的迁移(不同集群,不同版本),我们就可以通过这两章的知识来实现。
下面我们开始介绍hive的数据导出,以及集群Hive数据的迁移进行描述。
将查询的结果写入文件系统
一:说明
将上篇中从其他表导入语法进行简单的修改,就可以将查询的结果写入到文件系统。
二:语法:
Standard syntax:
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ... Hive extension (multiple inserts):
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ... row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] (Note: Only available starting with Hive 0.13)三:写入到本地
如果使用LOCAL,则数据会写入到本地
四:写入到集群
如果不使用LOCAL,则数据会写到指定的HDFS中,如果没写全路径,则使用Hadoop的配置项
fs.default.name(NameNode的URI)。五:实战
修改tmp文件夹权限(这里只是测试,所以使用最大权限)
chmod 777 tmp
进入Hive
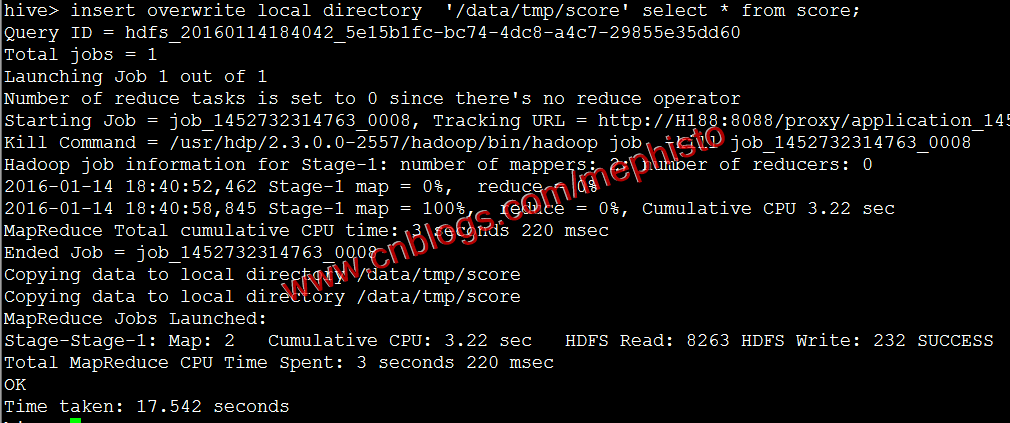
sudo -u hdfs hive将上一篇中的score表数据导出到本地
insert overwrite local directory '/data/tmp/score' select * from score;
我们可以看到/data/tmp/score/目录下有文件。
cd /data/tmp/score
ll
这样我们就把hive的数据导出到本地了。
下面我们使用不带local参数的命令,将hive表数据导到hdfs中
insert overwrite directory '/data/tmp/score' select * from score;我们使用hdfs的ls命令查看
hadoop fs -ls /data/tmp/score
这里文件只有一个,和上面的不一样,但总的内容是一样的,上面同样的数据导出,有时候也只有一个文件。这里就不做考究了。



集群数据迁移一
一:介绍
在官网里,我们可以看到EXPORT和IMPORT,该功能从Hive0.8开始加入进来。
二:Export/Import
导出命令根据元数据导出表或者分区,输出位置可以是另一个Hadoop集群或者HIVE实例。支持带有分区的表。导出的元数据存储在目标目录,数据文件存储在子目录。
导入导出的源和目标的元数据存储DBMS可以是不同的关系型数据库。
三:Export语法
EXPORT TABLE tablename [PARTITION (part_column="value"[, ...])]
TO 'export_target_path'四:Import语法
IMPORT [[EXTERNAL] TABLE new_or_original_tablename [PARTITION (part_column="value"[, ...])]]
FROM 'source_path'
[LOCATION 'import_target_path']五:官方例子
简单导入导出
export table department to 'hdfs_exports_location/department';
import from 'hdfs_exports_location/department';改名导入导出
export table department to 'hdfs_exports_location/department';
import table imported_dept from 'hdfs_exports_location/department';分区导出
export table employee partition (emp_country="in", emp_state="ka") to 'hdfs_exports_location/employee';
import from 'hdfs_exports_location/employee';分区导入
export table employee to 'hdfs_exports_location/employee';
import table employee partition (emp_country="us", emp_state="tn") from 'hdfs_exports_location/employee';指定导入位置
export table department to 'hdfs_exports_location/department';
import table department from 'hdfs_exports_location/department'
location 'import_target_location/department';作为外部表导入
export table department to 'hdfs_exports_location/department';
import external table department from 'hdfs_exports_location/department';
集群数据迁移二
一:介绍
虽然官方的Export/Import命令很强大,但在实际使用中,可能是版本的不同,会出现无法导入的情况,自己在这块也琢磨了下,总结出自己的一套带有分区的Hive表数据迁移方案,该方案在Cloudera和Hontorworks的集群中成功迁移过,Hive版本也不一致。
二:导出数据
由于Cloudera的发行版本CDH-5.3.3的Hive版本低于0.8所以用这个作为数据源。
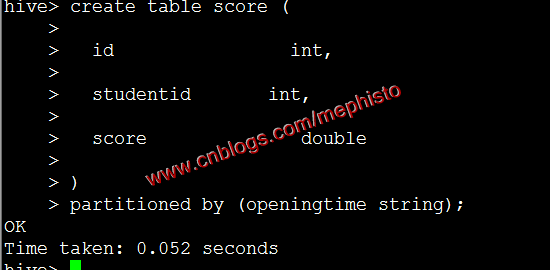
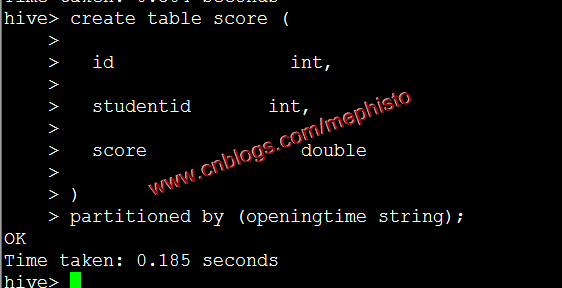
创建带分区表score
create table score (
id int,
studentid int,
score double
)
partitioned by (openingtime string);
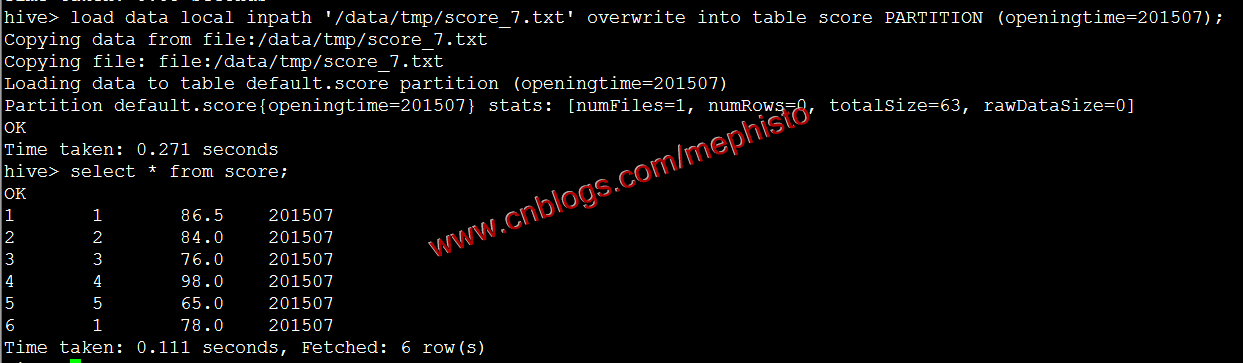
根据上一篇中导入数据的方式导入7,8月数据
load data local inpath '/data/tmp/score_7.txt' overwrite into table score PARTITION (openingtime=201507);
参考我们上面的导出到本地还是放在/data/tmp/score下
insert overwrite local directory '/data/tmp/score' select * from score;三:迁移数据
在另外一个集群新建/data/tmp目录
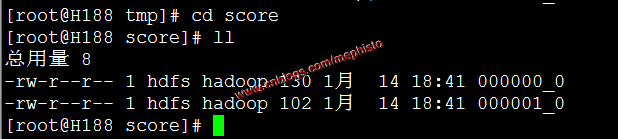
mkdir -p /data/tmp/score拷贝数据
scp /data/tmp/score/* root@h188:/data/tmp/score/查看
cd /data/tmp/score
ll
四:创建分区表和没有分区的临时表
被导入的集群是Hortonworks的HDP-2.7.1发行版本。
分区表就是我们最终的目标表,没有分区的临时表时过度用的。
进入Hive
sudo -u hdfs hive创建带分区的表
create table score (
id int,
studentid int,
score double
)
partitioned by (openingtime string);
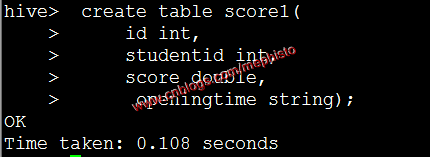
创建不带分区的临时表
create table score1(
id int,
studentid int,
score double,
openingtime string
);
五:将数据导入临时表
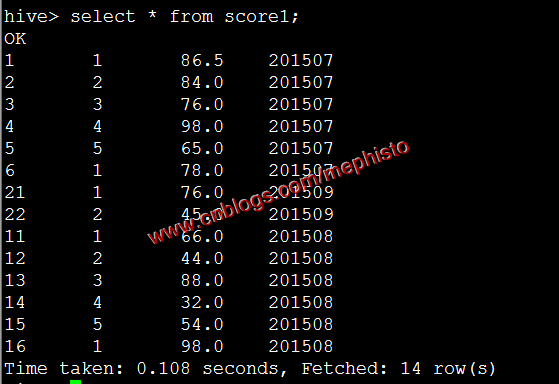
load data local inpath '/data/tmp/score' into table score1;
我们查下导进来的数据
select * from score1;
六:从临时表导入到分区表
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=10000;
#导入
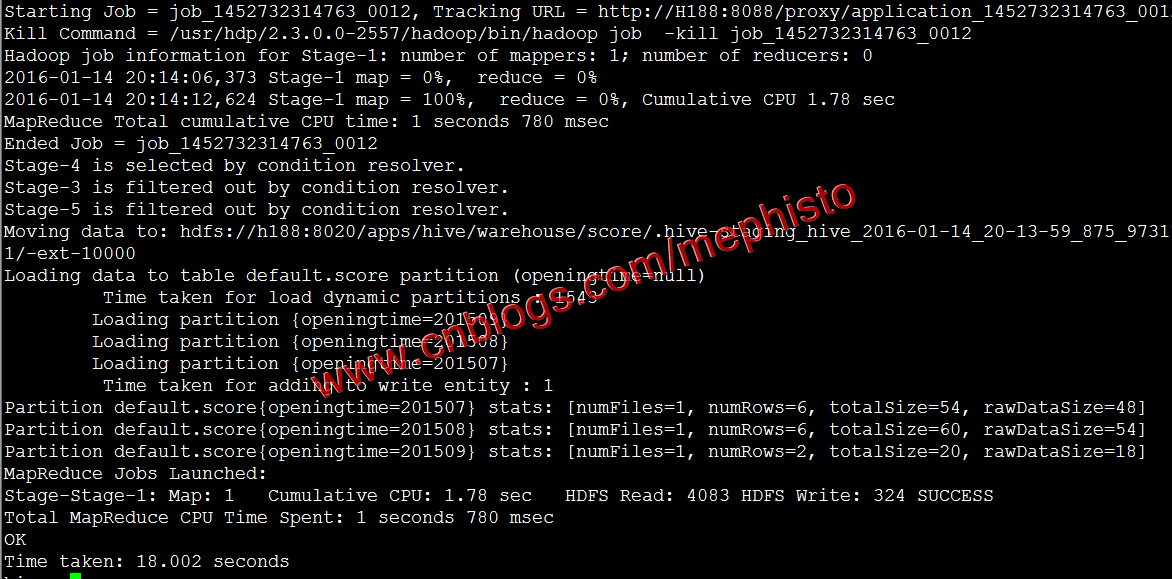
insert overwrite table score partition(openingtime) select * from score1;
查询
select * from score;
我们在hdfs中查看下hive的文件
hadoop fs -ls -R /apps/hive/warehouse/score
可以明显的看到根据openingtime分区了。
七:删除临时表
drop table score1八:删除临时数据
rm -rf /data/tmp/score这样我们的Hive集群数据迁移告一段落。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。


系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
从零自学Hadoop(17):Hive数据导入导出,集群数据迁移下的更多相关文章
- sqoop将oracle数据导入hdfs集群
使用sqoop将oracle数据导入hdfs集群 集群环境: hadoop1.0.0 hbase0.92.1 zookeeper3.4.3 hive0.8.1 sqoop-1.4.1-incubati ...
- 将数据导入MongoDB集群与MySQL
import sys import json import pymongo import datetime from pymongo import MongoClient client = Mongo ...
- 从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 从零自学Hadoop(01):认识Hadoop ...
- SQL SERVER 与ACCESS、EXCEL的数据导入导出转换
* 说明:复制表(只复制结构,源表名:a 新表名:b) select * into b from a where 1<>1 * 说明:拷贝表(拷贝数据,源表名:a 目标表名:b) ...
- SQL SERVER 和ACCESS、EXCEL的数据导入导出
SQL SERVER 与ACCESS.EXCEL之间的数据转换SQL SERVER 和ACCESS的数据导入导出[日期:2007-05-06] 来源:Linux公社 作者:Linux 熟 悉 ...
- Redis异构集群数据在线迁移工具Redis-Migrate-Tool【转】
摘要:Redis-Migrate-Tool(后面都简称RMT),是唯品会开源的redis数据迁移工具,主要用于异构redis集群间的数据在线迁移,即数据迁移过程中源集群仍可以正常接受业务读写请求,无业 ...
- 从零自学Hadoop(16):Hive数据导入导出,集群数据迁移上
阅读目录 序 导入文件到Hive 将其他表的查询结果导入表 动态分区插入 将SQL语句的值插入到表中 模拟数据文件下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并 ...
- 从零自学Hadoop(18):Hive的CLI和JDBC
阅读目录 序 Hive CLI(old CLI) Beeline CLI(new CLI) JDBC Demo下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出 ...
- 从零自学Hadoop(14):Hive介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 本系列已 ...
随机推荐
- ime-mode:disabled 关闭文本框输入法
在用户输入数字的表单中,需要禁止用户输入中文.符号等,减少用户输入出错误的可能性,CSS可以实现此功能. ime-mode的语法解释如下: ime-mode : auto | active | ina ...
- gradle中使用嵌入式(embedded) tomcat, debug 启动
在gradle项目中使用embedded tomcat. 最开始部署项目需要手动将web项目打成war包,然后手动上传到tomcat的webapp下,然后启动tomcat来部署项目.这种手动工作通常还 ...
- Struts2 源码分析——配置管理之ContainerProvider接口
本章简言 上一章笔者讲到关于Dispatcher类的执行action功能,知道了关于执行action需要用到的信息.而本章将会讲到的内容也跟Dispatcher类有关系.那就是配置管理中的Contai ...
- MySQL5.7不停业务将传统复制变更为GTID复制
由于GTID的优势,我们需要将传统基于file-pos的复制更改为基于GTID的复制,如何在线变更成为我们关心的一个点,如下为具体的方法: 目前我们有一个传统复制下的M-S结构: port 330 ...
- Win10 UWP 开发系列:支持异步的SQLite
上篇文章已经实现了在UWP中使用SQLite作为本地存储,作为移动端的程序,及时响应用户的操作是提高用户体验的重要途径,因此UWP的很多api都是异步的.那么如何使SQLite支持异步呢? 参考SQL ...
- jQuery AutoComplete在AJAX UpdatePanel环境中PostBack之后无法工作
前些日子,Insus.NET有实现<ASP.NET MVC使用jQuery实现Autocomplete>http://www.cnblogs.com/insus/p/5638895.htm ...
- iOS阶段学习第34天笔记(UI小组件 UISegment-UISlider-UIStepper-UIProgressView-UITextView介绍)
iOS学习(UI)知识点整理 一.UI小组件 1.UISegmentedControl 分段选择器 实例代码 - (void)viewDidLoad { [super viewDidLoad]; / ...
- sqlserver 通用分页存储过程(转)
USE [AAA_TYDC] GO /****** Object: StoredProcedure [dbo].[proc_DataPagination] Script Date: 11/20/201 ...
- luogg_java学习_05_面向对象(方法和类)
这篇总结断断续续写了2天,内容来自Oracle java8编程入门官方教程和课外搜索总结,希望自己以后返回来看的时候都懂,也希望可以起到帮助初学者的作用. 转载请注明 出自 luogg的博客园 , 因 ...
- java web学习总结(二十一) -------------------模拟Servlet3.0使用注解的方式配置Servlet
一.Servlet的传统配置方式 在JavaWeb开发中, 每次编写一个Servlet都需要在web.xml文件中进行配置,如下所示: 1 <servlet> 2 <servlet- ...