linux(CentOS7) 之 zookeeper 下载及安装
下载
搜索apache ,进入apache官网(https://www.apache.org/)下载

选择downloads 下的distribution

点击archive site

找到zookeeper目录
找到3.5.6目录
选择二进制 包 下载 apache-zookeeper-3.5.6-bin.tar.gz
注:下面那个非二进制包,安装后无法启动会报错: 找不到或无法加载主类 org.apache.zookeeper.server.quorum.QuorumPeerMain

基础环境:
三台centos7机器 :BigData01、BigData02、BigData03
java :JDK 1.8
二进制(源码包编译之后的)安装包:apache-zookeeper-3.5.6-bin.tar.gz
安装包存放路径 : /opt/software
解压路径 : /opt/modules/
部署:在bigdata01、bigdata02、bigdata03三台机器上都安装zookeeper集群
安装
在bigdata01上解压
cd /opt/sofeware
tar -zxf apache-zookeeper-3.5.6-bin.tar.gz -C /opt/modules/
重命名
cd /opt/modules/mv apache-zookeeper-3.5.6-bin zookeeper-3.5.6
修改配置文件
复制/opt/modules/zookeeper-3.5.6/conf/zoo_sample.cfg为zoo.cfg
cd /opt/modules/zookeeper-3.5.6/conf
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg
设置zookeeper文件存放目录
dataDir=/opt/modules/ zookeeper-3.5.6/data/zData
指定zookeeper集群中各个机器的信息
server后面的数字范围是1到255,一个zookeeper集群最多有255个机器。
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# 设置zookeeper文件存放目录
dataDir=/opt/modules/zookeeper-3.5.6/data/zData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
# 指定zookeeper集群中各个机器的信息
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888
创建myid文件
在dataDir所指定的目录(/opt/modules/zookeeper-3.5.6/data/zData)下创一个名为myid的文件,文件内容为server点后面的数字。
cd /opt/modules/zookeeper-3.5.6/
mkdir -p data/zData
echo 1 > /opt/modules/zookeeper-3.5.6/data/zData/myid
cat /opt/modules/zookeeper-3.5.6/data/zData/myid

分发到bigdata02、bigdata03
scp -r /opt/modules/zookeeper-3.5.6 bigdata02:/opt/modules
scp -r /opt/modules/zookeeper-3.5.6 bigdata03:/opt/modules
修改bigdata02、bigdata03上的myid文件
bigdata02上操作:
echo 2 >/opt/modules/zookeeper-3.5.6/data/zData/myid
cat /opt/modules/zookeeper-3.5.6/data/zData/myid

bigdata03上操作:
echo 3 >/opt/modules/zookeeper-3.5.6/data/zData/myid
cat /opt/modules/zookeeper-3.5.6/data/zData/myid

启动zookeeper
在各个机器上分别启动zookeeper
bigdata01上操作:
cd /opt/modules/zookeeper-3.5.6
bin/zkServer.sh start

bigdata02上操作:
cd /opt/modules/zookeeper-3.5.6
bin/zkServer.sh start
bigdata03上操作:
cd /opt/modules/zookeeper-3.5.6
bin/zkServer.sh start
zookeeper命令
zookeeper类似一个小型的文件系统,/是根目录,下面的所有节点都叫zNode。
进入zk shell 后输入任意字符,可以列出所有的zookeeper命令。
进入zkshell 界面(在任意一台机器执行都可以。)
cd /opt/modules/zookeeper-3.5.6
bin/zkCli.sh
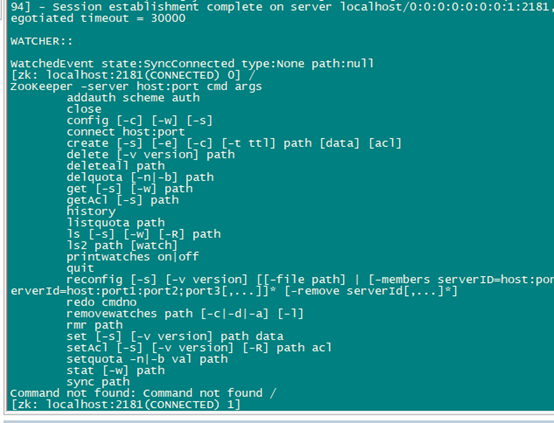
创建一个zNode
create /znode_test "demodata"

查询zNode上的数据
get /znode_test

列出所有zNode:
ls /

删除znode
rmr /znode_test

提示已被弃用(但是还是可以用),使用deleteall
再建一个,用deleteall删除
create /znode_test "demodata"
deleteall /znode_test

退出shell模式
quit
linux(CentOS7) 之 zookeeper 下载及安装的更多相关文章
- Linux(CentOS7)下RabbitMQ下载安装教程
原文链接:http://www.studyshare.cn/software/details/1172/0 一.下载安装步骤 下载erlang 1.wget 下载地址 2.rpm -Uvh erlan ...
- 基于CentOS-7的redis下载和安装
1.下载和安装 在我安装的虚拟机中,我把所有自己安装的软件都放在了/ph/install 目录下,具体以自己实际情况为准. [root@localhost ~]$ cd /ph/install #进入 ...
- Linux下zookeeper下载与安装教程
原文连接:(http://www.studyshare.cn/blog-front//blog/details/1169/0)一.下载 官网下载:点这里 百度网盘下载:点这里 官网下载图示: jav ...
- linux环境下zookeeper下载安装
步骤一:安装配置jdk环境 1.下载解压jdk-8u221-linux-x64.tar.gz 2.打开 配置文件,vim /etc/profile,添加如下配置,添加完成记得source /etc/p ...
- Linux CentOS7 下无图形界面安装Oracle11G R2版本
01,系统 Centos7 数据库版本 Oracle_11gR2 ,以及硬件要求 内存不能小于 1G,可用硬盘不小于8G Swap分区空间不小于2G grep MemTotal /proc/memin ...
- 08 Linux下MySQL的下载、安装及启动
测试环境 主机系统:Win7 64位 虚拟机:VMware® Workstation 11.1.0 虚拟机系统:CentOS 6.5 64位 Kernel 2.6.32-431.e16.x86_6 ...
- linux平台下Hadoop下载、安装、配置
在这里我使用的linux版本是CentOS 6.4 CentOS-6.4-i386-bin-DVD1.iso 下载地址: http://mirrors.aliyun.com/cen ...
- 如何在SecureCRT中给linux上传和下载文件 安装redis
首先建立文件 /download sz和rz命令无法用.则用以下1.和2.3步骤 需要上传或者下载,需要使用rz和sz命令.如果linux上没有这两个命令工具,则需要先安装.可以使用yum安装.运 ...
- Linux Centos7.5从docker的安装到容器的部署运行
环境: Win10 内的 VMware workstation(Centos7 64位) 所有命令皆为 root 用户, 非 root 用户应在命令前加 sudo 查看系统版本命令: cat /etc ...
随机推荐
- 1.Thmeleaf模板引擎
1.Thmeleaf的基本语法 大部分的Thmeleaf表达式都直接被设置到HTML节点中,作为HTML节点的一个属性存在,这样同一个模板文件既可以使用浏览器直接打开,也可以放到服务器中用来显示数据, ...
- LVS配置记录
目录: 一.NAT模式配置 二.DR模式配置 三.TUN模式配置 LVS原理及架构不再赘述. 一.NAT模式 部署环境 注意: 1) DIP.RIP必须为同网段: 2) RS网关必须指向DS: 3) ...
- Jenkins优化
目录 一.修改 JVM 的内存配置 二.修改jenkins 主目录 一.修改 JVM 的内存配置 Jenkins 启动方式有两种方式,一种是以 Jdk Jar 方式运行,一种是将 War 包放在 To ...
- HTTP隧道解决的问题
转自别人的文章:https://blog.csdn.net/gogzf/article/details/78385506 客户端通常会用 Web 代理服务器代表它们来访问 Web 服务器.比如,很多公 ...
- 发布iOS应用(xcode5)到App Store(苹果商店) 详细解析
发布iOS应用(xcode5)到App Store(苹果商店) 详细解析 作者:Memory 发布于:2014-8-8 10:44 Friday IOS 此教程可能不太适合,请移步至最新最全的:201 ...
- [BUUCTF]PWN——ciscn_2019_s_4
ciscn_2019_s_4 附件 步骤: 例行检查,32位程序,开启了nx保护 本地试运行一下,看看大概的情况,两次输入,让人联想到栈迁移 32位ida载入,找到关键函数,只可以溢出8字节,没法构造 ...
- python简单爬虫的实现
python强大之处在于各种功能完善的模块.合理的运用可以省略很多细节的纠缠,提高开发效率. 用python实现一个功能较为完整的爬虫,不过区区几十行代码,但想想如果用底层C实现该是何等的复杂,光一个 ...
- Excel.CurrentWorkbook数据源(Power Query 之 M 语言)
数据源: 任意超级表 目标: 将超级表中的数据加载到Power Query编辑器中 操作过程: 选取超级表中任意单元格(选取普通表时会自动增加插入超级表的步骤)>数据>来自表格/区域 M公 ...
- CF1097B Petr and a Combination Lock 题解
Content 有一个锁,它只有指针再次指到 \(0\) 刻度处才可以开锁(起始状态如图所示,一圈 \(360\) 度). 以下给出 \(n\) 个操作及每次转动度数,如果可以通过逆时针或顺时针再次转 ...
- react中使用Input表单双向绑定方法
input react 表单 input 密码框在谷歌浏览器下 会有黄色填充 官网的不太用,这个比较好用 type="password" autoComplete="ne ...