Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注。索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字“Python”,我们会得到下面的页面

我们可以看到这里罗列了"职位名"、"公司名"、"工作地点"、"薪资"、"发布时间",那么我们就把这些信息爬取下来吧!确定了需求,下一步我们就审查元素找到我们所需信息所在的标签,再写一个正则表达式把元素筛选出来就可以了!

顺理成章得到这样一个正则表达式:
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)
完成这关键的一步,下面写入本地就灰常简单了!还是来段代码吧!
# -*- coding:utf-8 -*-
import urllib.request
import re #获取原码
def get_content(page):
url ='http://search.51job.com/list/000000,000000,0000,00,9,99,python,2,'+ str(page)+'.html'
a = urllib.request.urlopen(url)#打开网址
html = a.read().decode('gbk')#读取源代码并转为unicode
return html def get(html):
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)#匹配换行符
items=re.findall(reg,html)
return items #多页处理,下载到文件
for j in range(1,10):
print("正在爬取第"+str(j)+"页数据...")
html=get_content(j)#调用获取网页原码
for i in get(html):
#print(i[0],i[1],i[2],i[3],i[4])
with open ('51job.txt','a',encoding='utf-8') as f:
f.write(i[0]+'\t'+i[1]+'\t'+i[2]+'\t'+i[3]+'\t'+i[4]+'\n')
f.close()
再来一张效果图
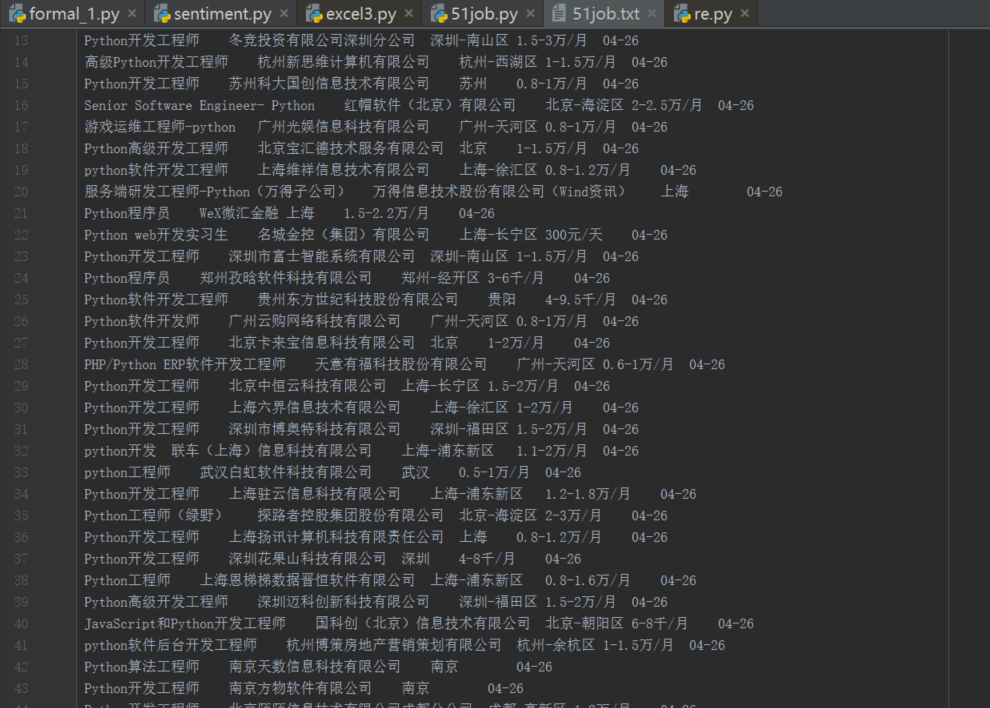
看起来效果还不错,要是能够以表格的形式展示出来就更好了,在网上看到有的大佬直接把招聘信息写入excel表格,今天我也来试一下吧!其实也并麻烦,只需要将上面的代码稍加修改就可以了。下面贴一下代码,重要的地方会有注释。
# -*- coding:utf-8 -*-
import urllib.request
import re
import xlwt#用来创建excel文档并写入数据 #获取原码
def get_content(page):
url ='http://search.51job.com/list/000000,000000,0000,00,9,99,python,2,'+ str(page)+'.html'
a = urllib.request.urlopen(url)#打开网址
html = a.read().decode('gbk')#读取源代码并转为unicode
return html def get(html):
reg = re.compile(r'class="t1 ">.*? <a target="_blank" title="(.*?)".*? <span class="t2"><a target="_blank" title="(.*?)".*?<span class="t3">(.*?)</span>.*?<span class="t4">(.*?)</span>.*? <span class="t5">(.*?)</span>',re.S)#匹配换行符
items = re.findall(reg,html)
return items
def excel_write(items,index): #爬取到的内容写入excel表格
for item in items:#职位信息
for i in range(0,5):
#print item[i]
ws.write(index,i,item[i])#行,列,数据
print(index)
index+=1 newTable="test.xls"#表格名称
wb = xlwt.Workbook(encoding='utf-8')#创建excel文件,声明编码
ws = wb.add_sheet('sheet1')#创建表格
headData = ['招聘职位','公司','地址','薪资','日期']#表头部信息
for colnum in range(0, 5):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font: bold on')) # 行,列 for each in range(1,10):
index=(each-1)*50+1
excel_write(get(get_content(each)),index)
wb.save(newTable)
最后实现的效果如下图:

至此,我们的工作就已经完成了!有的朋友可能想要爬取其他工作的招聘信息,观察了一下URl可以知道修改一下关键字名称就可以了!可以定义成一个函数只需输入关键字,然后就可以自动爬取该工作的招聘信息!条条大路通罗马,想要实现上面的效果肯定不止这一种方法,以上内容仅供参考,希望可以给有需要的朋友提供一点思路!至于代码就比较粗糙了,而本人也希望有一天能够写得一手风骚代码!还是要重申一遍,本人能力有限,文章中可能会有纰漏或者错误,也欢迎表哥表姐们前来指正!谢谢大家!
Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel的更多相关文章
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习之爬取全国各省市县级城市邮政编码
实例需求:运用python语言在http://www.ip138.com/post/网站爬取全国各个省市县级城市的邮政编码,并且保存在excel文件中 实例环境:python3.7 requests库 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- Python爬虫一:爬取上交所上市公司信息
前几天领导让写一个从新闻语料中识别上市公司的方案.上市公司属于组织机构的范畴,组织机构识别属于命名实体识别的范畴.命名实体识别包括人名.地名.组织机构等信息的识别. 要想从新闻语料中识别上市公司就需要 ...
- python scrapy爬取前程无忧招聘信息
使用scrapy框架之前,使用以下命令下载库: pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple 1.创建项目文件夹 scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
随机推荐
- PAT 1057
Stack is one of the most fundamental data structures, which is based on the principle of Last In Fir ...
- 【iOS系列】-多图片多线程异步下载
多图片多线程异步下载 开发中非常常用的就是就是图片下载,我们常用的就是SDWebImage,但是作为开发人员,不仅要能会用,还要知道其原理.本文就会介绍多图下载的实现. 本文中的示例Demno地址,下 ...
- UEFI+GPT下安装Win10+Ubuntu16.04双系统
安装环境 SSD+HDD双盘,Win10安装在SSD里,HDD分出来60G安装Ubuntu. 自行百度你的主板是否支持UEFI启动方式. Win10 下载Win10安装镜像.烧盘等步骤就不说了,重启后 ...
- 分布式文件系统 FastDFS 5.0.5 & Linux CentOS 7 安装配置(单点安装)——第一篇
分布式文件系统 FastDFS 5.0.5 & Linux CentOS 7 安装配置(单点安装)--第一篇 简介 首先简单了解一下基础概念,FastDFS是一个开源的轻量级分布式文件系统,由 ...
- 记录一个NPE问题
昨天在做公司项目时,我在一处地方加了一个逻辑校验,之后测了下发现在方法调用深处有一处NPE,来源于另一个同事的代码. 其实NPE本应该是个Java编程中老掉牙的问题,但我觉得这一处错误还是比较典型的, ...
- 使用vue-cli构建多页面应用+vux(二)
当我们安装好vue-cli完整的项目以后,我们开始对它进行改造,此处参考了简书某个作者的,附上原文链接 http://www.jianshu.com/p/43697bdee974以及此文例子地址htt ...
- collection and map and Collections
两者的区别: 两者都是接口: Collectoin是java集合框架的一个顶级接口,存储的元素可以是任意类型的对象: Map是java集合框架的映射接口,以键值对的形式存储对象: 也就是说,colle ...
- java 操作FTP
package comm.ftp; import java.io.ByteArrayInputStream; import java.io.File; import java.io.FileInput ...
- OpenMP 入门教程
前两天(其实是几个月以前了)看到了代码中有 #pragma omp parallel for 一段,感觉好像是 OpenMP,以前看到并行化的东西都是直接躲开,既然躲不开了,不妨研究一下: OpenM ...
- ubuntu实用命令--软件管理
近期重新拿起linux的书看了下,整理了一下linux的命令. ubuntu预装了APT和dpkg ,“APT”是 “Advanced Package Tool”的简写,“dpkg ”是“Debian ...