protobuf 原理
Protobuf 的优点
Protobuf 有如 XML,不过它更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。只需使用 Protobuf 对数据结构进行一次描述,即可利用各种不同语言或从各种不同数据流中对你的结构化数据轻松读写。
它有一个非常棒的特性,即“向后”兼容性好,人们不必破坏已部署的、依靠“老”数据格式的程序就可以对数据结构进行升级。这样您的程序就可以不必担心因为消息结构的改变而造成的大规模的代码重构或者迁移的问题。因为添加新的消息中的 field 并不会引起已经发布的程序的任何改变。
Protobuf 语义更清晰,无需类似 XML 解析器的东西(因为 Protobuf 编译器会将 .proto 文件编译生成对应的数据访问类以对 Protobuf 数据进行序列化、反序列化操作)。
使用 Protobuf 无需学习复杂的文档对象模型,Protobuf 的编程模式比较友好,简单易学,同时它拥有良好的文档和示例,对于喜欢简单事物的人们而言,Protobuf 比其他的技术更加有吸引力。
Protobuf 的不足
Protobuf 与 XML 相比也有不足之处。它功能简单,无法用来表示复杂的概念。
XML 已经成为多种行业标准的编写工具,Protobuf 只是 Google 公司内部使用的工具,在通用性上还差很多。
由于文本并不适合用来描述数据结构,所以 Protobuf 也不适合用来对基于文本的标记文档(如 HTML)建模。另外,由于 XML 具有某种程度上的自解释性,它可以被人直接读取编辑,在这一点上 Protobuf 不行,它以二进制的方式存储,除非你有 .proto 定义,否则你没法直接读出 Protobuf 的任何内容。
高级应用话题
更复杂的 Message
到这里为止,我们只给出了一个简单的没有任何用处的例子。在实际应用中,人们往往需要定义更加复杂的 Message。我们用“复杂”这个词,不仅仅是指从个数上说有更多的 fields 或者更多类型的 fields,而是指更加复杂的数据结构:
嵌套 Message
嵌套是一个神奇的概念,一旦拥有嵌套能力,消息的表达能力就会非常强大。
message Person {
required string name = 1;
required int32 id = 2; // Unique ID number for this person.
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
在 Message Person 中,定义了嵌套消息 PhoneNumber,并用来定义 Person 消息中的 phone 域。这使得人们可以定义更加复杂的数据结构。
Import Message
在一个 .proto 文件中,还可以用 Import 关键字引入在其他 .proto 文件中定义的消息,这可以称做 Import Message,或者 Dependency Message。比如下例:
import common.header;
message youMsg{
required common.info_header header = 1;
required string youPrivateData = 2;
}
其中,common.info_header定义在common.header包内。
Import Message 的用处主要在于提供了方便的代码管理机制。您可以将一些公用的 Message 定义在一个 package 中,然后在别的 .proto 文件中引入该 package,进而使用其中的消息定义。Google Protocol Buffer 可以很好地支持嵌套 Message 和引入 Message,从而让定义复杂的数据结构的工作变得非常轻松愉快。
Protobuf 的更多细节
人们一直在强调,同 XML 相比, Protobuf 的主要优点在于性能高。它以高效的二进制方式存储,比 XML 小 3 到 10 倍,快 20 到 100 倍。对于这些 “小 3 到 10 倍”,“快 20 到 100 倍”的说法,严肃的程序员需要一个解释。因此在本文的最后,让我们稍微深入 Protobuf 的内部实现吧。
有两项技术保证了采用 Protobuf 的程序能获得相对于 XML 极大的性能提高。
第一点,我们可以考察 Protobuf 序列化后的信息内容。您可以看到 Protocol Buffer 信息的表示非常紧凑,这意味着消息的体积减少,自然需要更少的资源。比如网络上传输的字节数更少,需要的 IO 更少等,从而提高性能。
第二点,我们需要理解 Protobuf 封解包的大致过程,从而理解为什么会比 XML 快很多。
Google Protocol Buffer 的 Encoding
Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf 采用的非常巧妙的 Encoding 方法。考察消息结构之前,让我首先要介绍一个叫做 Varint 的术语。Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。下面就详细介绍一下 Varint。
Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010
下图演示了 Google Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。

消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对。如下图所示:

采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field。Key 的定义如下:
(field_number << 3) | wire_type
可以看到 Key 由两部分组成。第一部分是 field_number,即为标识数字id。第二部分为 wire_type。表示 Value 的传输类型。Wire Type 可能的类型如下表所示:

细心的读者或许会看到在 Type 0 所能表示的数据类型中有 int32 和 sint32 这两个非常类似的数据类型。Google Protocol Buffer 区别它们的主要意图也是为了减少 encoding 后的字节数。在计算机内,一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 5 个 byte。为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。Zigzag 编码用无符号数来表示有符号数字,正数和负数交错,这就是 zigzag 这个词的含义了。如图所示:
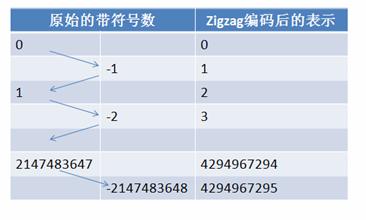
使用 zigzag 编码,绝对值小的数字,无论正负都可以采用较少的 byte 来表示,充分利用了 Varint 这种技术。其他的数据类型,比如字符串等则采用类似数据库中的 varchar 的表示方法,即用一个 varint 表示长度,然后将其余部分紧跟在这个长度部分之后即可。
protobuf 原理的更多相关文章
- 深入理解 ProtoBuf 原理与工程实践(概述)
ProtoBuf 作为一种跨平台.语言无关.可扩展的序列化结构数据的方法,已广泛应用于网络数据交换及存储.随着互联网的发展,系统的异构性会愈发突出,跨语言的需求会愈加明显,同时 gRPC 也大有取代R ...
- 大数据 --> ProtoBuf的使用和原理
ProtoBuf的使用和原理 一.简介 Protobuf是一个灵活的.高效的用于序列化数据的协议.相比较XML和JSON格式,protobuf更小.更快.更便捷.Protobuf是跨语言的,并且自带了 ...
- protobuf可变长编码的实现原理
protobuf中的整数,如int32.int64.uint32.uint64.sint32.sint64.bool和enum,采用可变长编码,即varints. 这样做的好处是,可以节省空间.根据整 ...
- Android Protobuf应用及原理
前言 之前一直忙于移动端日志SDK Trojan的开源工作,已十分稳定地运行在饿了么团队App中,集成了日志加密和解密功能.哎呀,允许我卖个狗皮膏药,不用不知道,用了就知道,从此爱不释手,Trojan ...
- Protobuf底层存储原理
参考官网, 序列化原理 底层二进制存储 message Test1 { optional int32 a = 1; } 并设置为a=150,序列化到一个文件中,查看文件,得到下面的二进制: 08 96 ...
- 常见的序列化框架及Protobuf序列化原理
原文链接:https://www.jianshu.com/p/657fbf347934 https://www.cnblogs.com/javazhiyin/p/11375553.html https ...
- google protocol buffer——protobuf的使用特性及编码原理
这一系列文章主要是对protocol buffer这种编码格式的使用方式.特点.使用技巧进行说明,并在原生protobuf的基础上进行扩展和优化,使得它能更好地为我们服务. 在上一篇文章中,我们展示了 ...
- google protocol buffer——protobuf的编码原理二
这一系列文章主要是对protocol buffer这种编码格式的使用方式.特点.使用技巧进行说明,并在原生protobuf的基础上进行扩展和优化,使得它能更好地为我们服务. 在上一篇文章中,我们主要通 ...
- google protobuf的原理和思路提炼
之前其实已经用了5篇文章完整地分析了protobuf的原理.回过头去看,感觉一方面篇幅过大,另一方面过于追求细节和源码,对protobuf的初学者并不十分友好,因此这篇文章将会站在"了解.使 ...
随机推荐
- 在开发中使用Mockito进行测试
关于单元测试的一些问题 当我们Javaweb项目中编写单元测试的时候,通常会面临一个普遍的问题:需要测试的类会有很多依赖,而这些依赖的类或者对象又会有很多别的依赖,导致我们在写单元测试的时候几乎需要把 ...
- JavaScript Html页面加载完成三种写法
//一.Html页面加载完成的JS写法 //1. $(function () { alert("窗体Html页面加载完成方法一"); }); //2. $(document ...
- python 学习源码练习(2)——简单文件读取
#文件创建 #!/usr/bin/python3 'makeTextFile.py--create text file' import os ls = os.linesep #get filename ...
- Vue + iView + vuex + vee-validate 完整项目总结
build/*.js config/*.js src/旧代码文件夹 部门最近的一个新项目启动,很幸运由我来主导整个前端部分的技术选型和整体架构,项目工作量很大,但是却没有足够的人手,只有三个连CSS都 ...
- XCode v9.6.2017.0830
新生命团队基础框架X组件,包括网络.数据库.安全.多线程.反射.序列化.模版引擎.服务代理.远程过程调用等模块,包括Mvc后台魔方.超级码神工具.消息队列等子系统,支持Mono/Android/iOS ...
- 迁移数据库数据到SQL Server 2017
概述 本篇我们将利用DMA一步一步实现SQL Server 的迁移.帮助大家理解现在的SQL Server与新版本的融合问题,同时需要我们做哪些操作来实现新版本的升级或者迁移. SQL Serve ...
- Keepalived实战(3)
一.环境 如上图所示: keepalived的mater为proxy-master,keepalived的slave为proxy-slave. 要求:当mater出现问题时,主动切换到slave上.这 ...
- windbg指定SOS版本,执行扩展命令报错
调试dump文件,加载相匹配版本的sos/clr时,绝大多数都是可以正常使用的. 然而凡事都有例外,今天在做类似工作时,遇到了错误: CLRDLL: Consider using ".cor ...
- Android基础_多媒体
一.MediaPlayer Android的MediaPlayer包含了Audio和video的播放功能,在Android的界面上,Music和Video两个应用程序都是调用MediaPlayer实现 ...
- python科学计算之numpy
1.np.logspace(start,stop,num): 函数表示的意思是;在(start,stop)间生成等比数列num个 eg: import numpy as np print np.log ...