【NQG】Paragraph-level Neural Question Generation with Maxout Pointer and Gated Self-attention Networks论文笔记
这篇文章主要处理了在问题生成(Question Generation,QG)中,长文本(多为段落)在seq2seq模型中表现不佳的问题。长文本在生成高质量问题方面不可或缺。
1. Introduction
QG可以让对话系统更积极主动,也可以生成更多的问题来丰富QA(Question Answering)系统,同时在教育领域的阅读理解方面也有应用。
QG主要分为rule-based和neural approach:
rule-based:可以看作是一个fill-and-rank模型,提取目的句子的相关实体,填入人工编写的模板中,再根据rank方法选择一个或几个最合适的。优点是很流畅,缺点是很依赖人工模板,很难做到open-domain。
neural approach:一般是改良的seq2seq模型。传统的encoder-decoder框架。
这篇文章针对的是answer-aware问题,即生成问题的答案显式得出现在给定文本的一部分或者几部分中。
针对段落生成的主要难点在于如何处理段落中的信息,即如何挑选出适合于生成问题的信息。
本文主要提出了一个改进的seq2seq模型,加入了maxout pointer机制和gated self-attention encoder。在之后的研究中可以通过加入更多feature或者policy gradient等强化学习的方式提升模型性能。
2. Model
2.1 question definition
\[\overline Q = \mathop {\arg \max }\limits_Q (\Pr ob\{ Q|P,A\} )\]
其中\(\overline Q\)代表生成的问题,\(P\)代表整个段落,\(A\)代表已知的答案。\(P\),\(A\)以及\(\overline Q\)中的单词均来自于词典。
2.2 Passage and Answer Encoding
本文中使用了双向RNN来进行encode。
\[{u_t} = RN{N^E}({u_{t - 1}},[{e_t},{m_t}])\]
- Answer Tagging:
在上式中,\({u_t}\)表示RNN的hidden state,\({e_t}\)表示word embedding,\({m_t}\)表示这个词是否在answer中。\([{e_t},{m_t}]\)表示把这两个向量拼接起来。因为我们要生成跟答案相关的问题,所以这种思路也是比较自然的。
Gated Self-Attention:
这里的大部分思想与Gated Self-Matching Networks for Reading Comprehension and Question Answering这篇文章中关于gated attention-based以及self matching的论述类似。
门控自注意力机制主要解决以下问题:
聚合段落信息
嵌入(embed)段落内部的依赖关系,在每一时间步中优化P和A的嵌入表示。
主要步骤如下:
- 计算self matching
\[{a^s}_t = soft\max ({U^T}{W^s}{u_t})\]
\[{s_t} = U{\rm{\cdot}}{{a}^s}_t\]
其中,\({a^s}_t\)是段落中所有encode的单词对当前\(t\)时刻所对应单词的之间的依赖关系的系数,注意,\(U\)表示从1到最后时刻所有的hidden state组成的矩阵,即表示passage-answer;\({s_t}\)表示段落中所有encode的单词对当前\(t\)时刻所对应单词的之间的依赖关系,也是self matching的表示。
【个人理解】:这里类似于self-attention,主要目的是刻画段落中不同单词对于生成问题的重要性(相关性),越相关的值越大,否则越小。
- 计算gated attention
\[{f_t} = \tanh ({W^f}[{u_t},{s_t}])\]
\[{g_t} = sigmoid({W^g}[{u_t},{s_t}])\]
\[{\hat u_t} = {g_t} \odot {f_t} + (1 - {g_t}) \odot {u_t}\]
其中,\({f_t}\)表示新的包含self matching信息的passage-answer表示,\({g_t}\)表示一个可学习的门控单元,最后,\({\hat u_t}\)表示新的passage-answer表示,用来喂给decoder。
【个人理解】:gated attention可以专注于answer与当前段落之间的关系。
2.3 Decoding with Attention and Maxout Pointer
使用RNN
\[{d_t} = RN{N^D}({d_{t - 1}},{y_{t - 1}})\]
\[p({y_t}|\{ {y_{ < t}}\} ) = soft\max ({W^V}{d_t})\]
注意此处的\(y_t\)不作为最后的输出,还要经过一系列操作。
Attention:
用Attention得到一个新的decoder state
\[{a^d}_t = soft\max ({{\hat U}^T}{W^a}{d_t})\]
\[{c_t} = \hat U \cdot {a^d}_t\]
\[{{\hat d}_t} = \tanh ({W^b}[{d_t},{c_t}])\]Copy Mechanism:
\[{r_t} = {{\hat U}^T}{W^a}{d_t}\]
\[{r_t} = \{ {r_{t,k}}\} _{k = 1}^M\]
\[s{{c_t}^{copy}}({y_t}) = \sum\limits_{k,{x_k} = {y_t}} {{r_{t,k}}} ,{y_t} \in \chi \]
\[s{{c_t}^{copy}}({y_t}) = - \inf ,otherwise\]
\[s{{c_t}^{gen}}({y_t}) = {W^V}{d_t}\]
\[[F{D_t}^{gen},F{D_t}^{copy}] = soft\max ([s{c_t}^{gen},s{c_t}^{copy}])\]
\(F{D_t}^{gen}\)表示在t时刻生成新单词的final distrubution,\(F{D_t}^{copy}\)表示在t时刻copy单词的final distrubution。
\[\begin{array}{l}
{{\hat y}_t} = \arg \max ([F{D_t}^{gen},F{D_t}^{copy}]),{{\hat y}_t} \in gen\\
{{\hat y}_t} = \arg \max ([F{D_t}^{gen},F{D_t}^{copy}]) - |V|,{{\hat y}_t} \in copy
\end{array}\]
这里的\({{\hat y}_t}\)表示在index,相应的代表gen词表中或者copy词表(所有input的单词)中的单词index。
- Maxout Pointer:
\[s{{c_t}^{copy}}({y_t}) = \max\limits_{k,{x_k} = {y_t}} {{r_{t,k}}} ,{y_t} \in \chi \]
\[s{{c_t}^{copy}}({y_t}) = - \inf ,otherwise\]
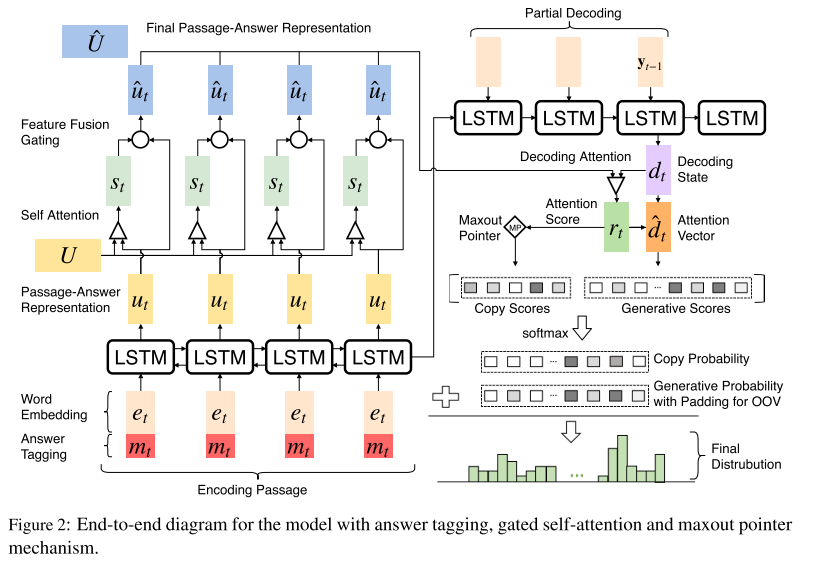
注意:encoder部分的下标有误,不应全为\(t\),应从\({u_1}\)递增至\({u_M}\)
PS:gated attention,self matching以及copy mechanism的解释还没有搞清楚,仅仅知道怎么处理。
【NQG】Paragraph-level Neural Question Generation with Maxout Pointer and Gated Self-attention Networks论文笔记的更多相关文章
- QG-2019-AAAI-Improving Neural Question Generation using Answer Separation
Improving Neural Question Generation using Answer Separation 本篇是2019年发表在AAAI上的一篇文章.该文章在基础的seq2seq模型的 ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记
一.高效的训练 1.Large-batch training 使用大的batch size可能会减小训练过程(收敛的慢?我之前训练的时候挺喜欢用较大的batch size),即在相同的迭代次数 ...
- 论文阅读笔记:《Interconnected Question Generation with Coreference Alignment and Conversion Flow Modeling》
论文阅读:<Interconnected Question Generation with Coreference Alignment and Conversion Flow Modeling& ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记:Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go with deep neural networks and tree search Nature 2015 这是本人论文笔记系列第二篇 Nature ...
- 论文笔记 《Maxout Networks》 && 《Network In Network》
论文笔记 <Maxout Networks> && <Network In Network> 发表于 2014-09-22 | 1条评论 出处 maxo ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
随机推荐
- 【Win10】系统修改
1.删除“快速访问”[操作说明] a.打开HKEY_CLASSES_ROOT\CLSID\{679f85cb-0220-4080-b29b-5540cc05aab6}\ShellFolder ...
- SpringBoot加载配置文件(@PropertySource@importSource@Value)
情景描述 最近新搭建了一个项目,从Spring迁到了Springboot,为了兼容Spring加载配置文件的风格,所以还想把PropertyPlaceholderConfigurer放在.xml文件里 ...
- php的微信公众平台开发接口类
<?php define("TOKEN", "weixin"); $wechatObj = new wechatCallbackapiTest(); if ...
- MySQL高可用架构应该考虑什么? 你认为应该如何设计?
一.MySQL高可用架构应该考虑什么? 对业务的了解,需要考虑业务对数据库一致性要求的敏感程度,切换过程中是否有事务会丢失 对于基础设施的了解,需要了解基础设施的高可用的架构.例如 单网线,单电源等情 ...
- PHP、JS 中 encode/decode
PHP : urlencode() urldecode() JS : encodeURIComponent() decodeURIComponent() 同一字符串,编码后的结果一样 1
- 华为云主机配置yum源
问题: 拥有华为主机,配置华为云mirrors,不走公网流量加速体验 系统: centos7.6 解决: 01.华为云mirrors https://mirrors.huaweicloud.com/ ...
- 数据库开发-pymysql详解
数据库开发-pymysql详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Python支持的MySQL驱动 1>.什么是驱动 与MySQL通信就是典型的CS模式.Se ...
- 【pathon基础】初识python
一.python的起源 作者:Guido van Rossum(龟叔) 设计原则:优雅,简单,明确 二.解释型语言VS编译型语言 1.解释型语言:C#.python step1:程序员写代码: ste ...
- Jenkins拉取github库代码执行构建
前言 上篇文章写了关于定时构建,以及构建后发送邮件的内容,但是构建时运行的代码是我们手动添加到Jenkins工作空间的.这篇文章我们说一说自动从GitHub远程库拉取代码,执行构建,废话不多说,开始! ...
- msdtc不可用
在使用“经销商园地 网上订单处理程序”等程序时,如果程序报:服务器×××上的MSDTC不可用”,可以按照以下方法进行解决: 在windows控制面版-->管理工具-->服务-->Di ...