Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记
一、高效的训练
1、Large-batch training
使用大的batch size可能会减小训练过程(收敛的慢?我之前训练的时候挺喜欢用较大的batch size),即在相同的迭代次数下,
相较于使用小的batch size,使用较大的batch size会导致在验证集上精度下降。文中介绍了四种方法。
Linear scaling learning rate
梯度下降是一个随机过程,增大batch size不会改变随机梯度的期望,但是减小了方差(variance)。换句话说,增大batch size
可以减小梯度中的噪声,所以,此时应该增大学习率来进行调整:随着batch size的增加,线性增加学习率。比如,初始学习率0.1,
batch size=256,当batch size增加为b时,学习率为0.1×b/256
Learning rate warmup
开始使用一个较小的学习率,当训练稳定后,再切换回初始学习率。例如使用5个epochs来warm up,初始学习率为n,在第i个batch,
1<=i<=m,学习率lr=i*n/m
Zero γ
在残差模块中,最后一层为BN层,先对x标准化输出为x̂, 再做一个尺度变换γ x̂ + β。γ和β都为可学习参数,被初始化为1和0。Zero γ
策略是,对于残差模块最后的BN层,γ设为0,相当于网络有更少的层数,在初始阶段更容易训练。
No bias decay
weight decay一般应用在所有可学习参数上,包括weight和bias。为了防止过拟合,只在weights上做正则化,其他参数,包括bias,BN中的
γ和β都不做正则化。
2、Low-precision training
用FP16对所有的parameters和activations进行存储和梯度的计算,与此同时使用FP32对参数进行拷贝用于参数的更新。另外,在损失函数上
乘以一个标量来将梯度的范围更好的对齐到FP16也是一个实用的做法
3、实验
很奇怪的对比实验,应该再加上相同的batch size才更有说服力啊。

二、Model Tweaks
Model Tweaks是指修改模型的结构,比如某个卷基层的stride。本文以resnet为例,探讨这些tweak对精度的影响。
1、ResNet Architecture
一个典型的resnet50结构如下,其中input stem首先使用7*7卷积,stride=2,接着一个3*3的maxpool,stride=2。
input stem将特征减小至1/4,维度增加至64。从state2开始,每个stage包括down sampling和2个residual模块,如图。
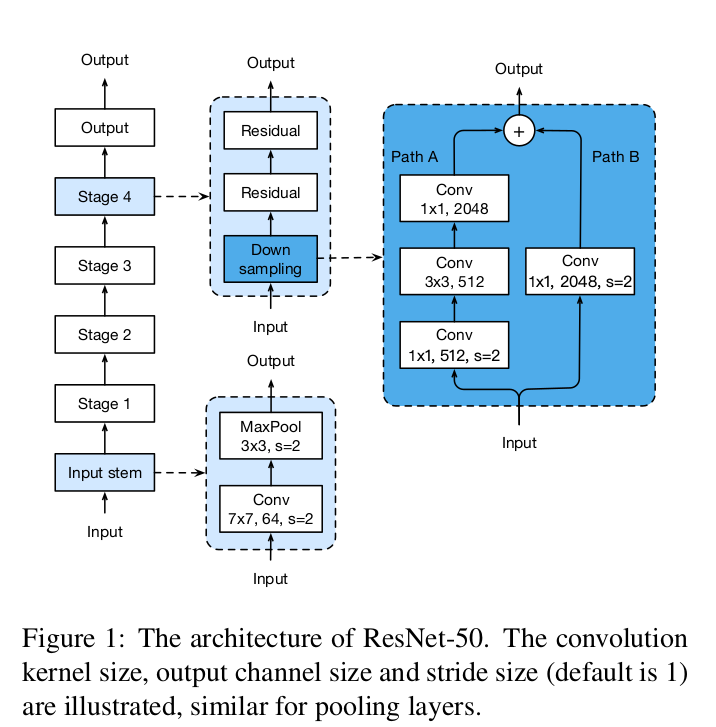
2、ResNet Tweaks
resnet-B更改了down sampling中 stride=2的位置,不让1*1的stride=2,
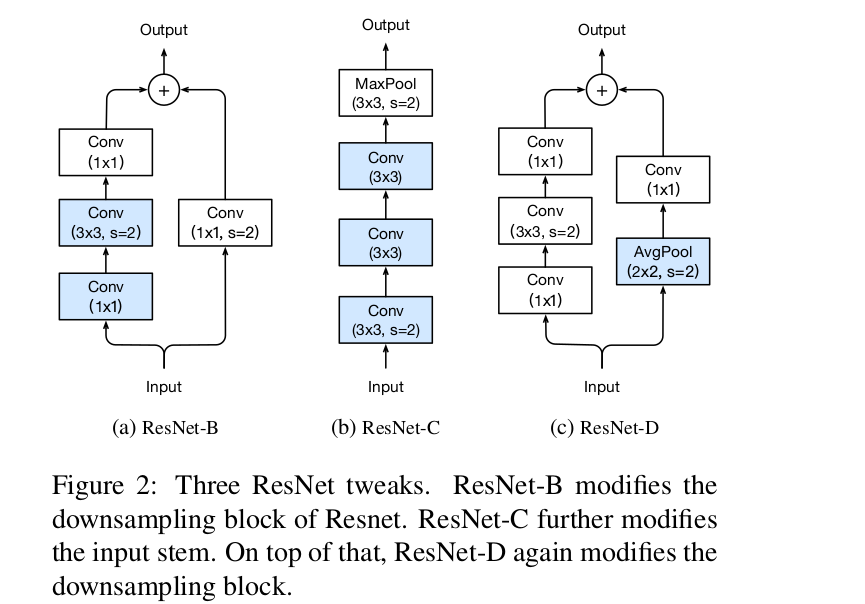
resnet-C将input stem中的7×7卷积用3个3*3代替(节省参数),前两个c=32,最后一个为64.。
为了减小stride=2,1*1卷积的损失,增加avg pool,conv stride=1(这样就不损失吗。。。)对比发现,
resnet-D效果最好。

三、Training Refinements
通过介绍训练中的策略,进一步提高模型准确率
Cosine Learning Rate Decay
其中η是学习率(不包括warm up阶段),不过看validation accur,step decay并不差于cosine decay啊

Label Smoothing
正常的交叉熵损失在预测的时候,对于给定的数据集的label,将正例设为1,负例设为0,是一个one-hot向量。这样子会有一些问题,
模型对于标签过于依赖,当数据出现噪声的时候,会导致训练结果出现偏差。增加一个变量ϵ,对类别进行平滑,此时loss变为,其中p(y)为真是标签,
p(c)为输出类别概率。
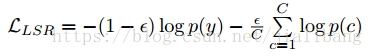
参考: https://zhuanlan.zhihu.com/p/53849733
https://www.cnblogs.com/zyrb/p/9699168.html
Knowledge Distillation
主要用于将大网络压缩为小网络,损失函数为,其中z和r分别是student model和teacher model的输出,p是真实标签的分布
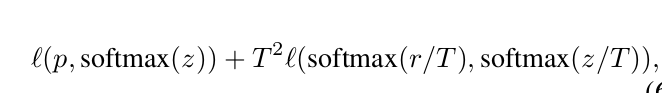
Mixup Training
使用线性插值混合两个样本,构成新的样本,并使用新样本进行训练(没用过知识蒸馏,这意思是teacher model和student model一起训练?)。
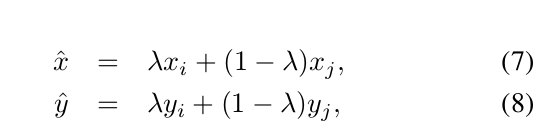
实验
知识蒸馏对mobilnet,inception-v3并没有提升,因为teacher model是resnet,与它们不同。

Bag of Tricks for Image Classification with Convolutional Neural Networks论文笔记的更多相关文章
- Bag of Tricks for Image Classification with Convolutional Neural Networks笔记
以下内容摘自<Bag of Tricks for Image Classification with Convolutional Neural Networks>. 1 高效训练 1.1 ...
- 训练技巧详解【含有部分代码】Bag of Tricks for Image Classification with Convolutional Neural Networks
训练技巧详解[含有部分代码]Bag of Tricks for Image Classification with Convolutional Neural Networks 置顶 2018-12-1 ...
- Bag of Tricks for Image Classification with Convolutional Neural Networks
这篇文章来自李沐大神团队,使用各种CNN tricks,将原始的resnet在imagenet上提升了四个点.记录一下,可以用到自己的网络上.如果图片显示不了,点击链接观看 baseline mode ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Notes on Large-scale Video Classification with Convolutional Neural Networks
Use bigger datasets for CNN in hope of better performance. A new data set for sports video classific ...
- ImageNet Classification with Deep Convolutional Neural Networks 论文解读
这个论文应该算是把深度学习应用到图片识别(ILSVRC,ImageNet large-scale Visual Recognition Challenge)上的具有重大意义的一篇文章.因为在之前,人们 ...
- Learning local feature descriptors with triplets and shallow convolutional neural networks 论文阅读笔记
题目翻译:学习 local feature descriptors 使用 triplets 还有浅的卷积神经网络.读罢此文,只觉收获满满,同时另外印象最深的也是一个浅(文章中会提及)字. 1 Cont ...
- cs231n spring 2017 lecture5 Convolutional Neural Networks听课笔记
1. 之前课程里,一个32*32*3的图像被展成3072*1的向量,左乘大小为10*3072的权重矩阵W,可以得到一个10*1的得分,分别对应10类标签. 在Convolution Layer里,图像 ...
- Deep learning_CNN_Review:A Survey of the Recent Architectures of Deep Convolutional Neural Networks——2019
CNN综述文章 的翻译 [2019 CVPR] A Survey of the Recent Architectures of Deep Convolutional Neural Networks 翻 ...
随机推荐
- centos7 docker安装
Docker分为社区版CE和企业版EE. 社区版是免费提供给个人开发者和小型团体使用的,企业版会提供额外的收费服务,比如经过官方测试认证过的基础设施.容器.插件等 社区版按照stable和edge两种 ...
- Eclipse 查看 WebService 服务请求和响应消息
每个WebService 对入参和返参都是有自己的要求的:别人调用我的WebService,需要按照我的要求进行传参.当我返回数据时,我也得告诉别人,我的返回数据是怎样组织的,方便别人读取. 那怎样查 ...
- 转 - mybatis中${}、 #{}区别及应用场景
转与 https://www.jianshu.com/p/bbeff97d41eb 动态sql是mybatis的主要特性之一.在mapper中定义的参数传到xml中之后,在查询之前mybatis会对其 ...
- Python——爬虫——数据提取
一.XML数据提取 (1)定义:XML指可扩展标记语言.标记语言,标签需要我们自行定义 (2)设计宗旨:是传输数据,而非显示数据,具有自我描述性 (3)节点关系: 父:每个元素及属性都有一个父. ...
- LOJ #2719. 「NOI2018」冒泡排序(组合数 + 树状数组)
题意 给你一个长为 \(n\) 的排列 \(p\) ,问你有多少个等长的排列满足 字典序比 \(p\) 大 : 它进行冒泡排序所需要交换的次数可以取到下界,也就是令第 \(i\) 个数为 \(a_i\ ...
- [CTSC2018]暴力写挂
题目描述 www.lydsy.com/JudgeOnline/upload/201805/day1(1).pdf 题解 首先来看这个我们要最大化的东西. deep[u]+deep[v]-deep[lc ...
- python中xrange和range(转)
说到序列,我们第一想到的是一组有序元素组成的集合.同时,每个元素都有唯一的下标作为索引. 在Python中,有许多内界的序列.包括元组tuple,列表list,字符串str等.上面提到的序列类型(li ...
- Spring mvc 整合PageHelper
Integer page=queryBean.getPage(); Integer pageSize=queryBean.getPageSize(); response.setContentType( ...
- 第四章:条件语句(if)和循环结构(while)
1.流程控制 含义与作用 Python程序执行,一定按照某种规律在执行 a.宏观一定是自上而下(逻辑上方代码一定比逻辑下方代码先执行):顺序结构b.遇到需要条件判断选择不同执行路线的执行方式:分支结构 ...
- C# 数独算法——LINQ+委托
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace Sing ...