###《Video Event Detection by Inferring Temporal Instance Lables》
论文作者:Kuan-Ting Lai, Felix X. Yu, Ming-Syan Chen and Shih-Fu Chang.
#@author: gr
#@date: 2014-01-25
#@email: forgerui@gmail.com
一、 论文主要工作
1.1 传统方法
传统方法将整个视频表示为一个向量。这种方法简单高效。
一般可以分为如下三个步骤:
- 特征提取(extract features)
- 量化(quantized)
- 池化(pooling),生成一个全局向量
存在的问题:在最后池化的时候,丢失了时空局部信息。
1.2 主要工作
把一个视频表示为多个实例,这些实例是视频的不同时间间隔。
我们的目标就是学习一个基于实例的事件检测模型。
论文的主要工作:
- 提出一个基于实例的视频检测方法。
- 提出的方法可以同时推理实例标签,训练分类模型。
- 做了许多实验,证明了算法的性能。
二、提出的方法
2.1 例子
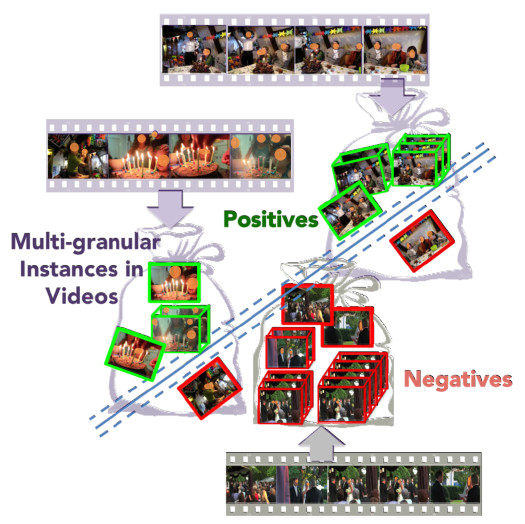
例子: 上面检测视频中是否包含生日聚会,首先将视频划分为许多小的实例。如果较多的实例是与生日聚会相关的,就认为是生日聚会;如果包含没有或较少的实例与生日聚会相关,则说明不包含生日聚会。
2.2 基本表示
\(\{V_m\}_{m=1}^M\) 表示数据集中的1到M个视频。
视频 \(V_m\) 中含有 \(N_m\) 个实例表示为 ({x_i^m, y_i^m }_{i=1}^{N_m}) 。
其中,\(x_i^m\) 表示视频m的第i个实例的特征向量。
2.3 实例比例事件识别
\]
可以得到目标函数:
$$\min_{\{y^m\}_{m=1}^{M}, w, b} ~~ \frac{1}{2}\parallel w \parallel^2 + C \sum_{m=1}^M \sum_{i=1}^{N_m} L(y_i^m, (w^T x_i^m + b)) \\
s.t. ~~~~ p_m(y^m) = P_m, m = 1,...,M.$$
其中,\(L(\cdot)\)是经验损失函数。这篇文章中选择 hinge loss function 作为损失函数。
2.4 未知比例
上面讨论的是在 ({P_m}{m=1}^{M}) 已知的情况,但实际上,我们只知道视频的标签({Y_m}{m=1}^{M}),它只能取({-1, 1})。
要解决这个问题,我们就设想正例视频中包含更多正实例,负例视频包含较少或没有正实例。
修改后的目标函数:
$$
\begin{aligned}
\min_{\{y^m\}_{m=1}^M, w, b} ~~~ \frac{1}{2}\parallel w \parallel^2 & + ~~ C \sum_{m=1}^M \sum_{i=1}^{N_m} L(y_i^m, (w^T x_i^m + b)) \\
& + ~~ C_p\sum_{m=1}^M\mid p_m(y^m) - P_m \mid
\end{aligned}
$$
$$s.t. ~~~~ P_m =
\left\{
\begin{aligned}
& 1 ~~~~ if ~~ Y_m = 1 \\
& 0 ~~~~ if ~~ Y_m = -1
\end{aligned}
\right. , m = 1, ..., M.
$$
其中,第三项是损失函数,惩罚目标正实例比例\(P_m\)与估计比例\(p_m(y^m)\)的差别。\(C_p\)通过交叉验证得出。
2.5 多粒度的实例方法
不同实例的时间不一样。比如,生日聚会可能包含蛋糕和蜡烛,这只需要一帧就能表示;而跑酷就需要视频块才能很好地描述。
假设有K个粒度。第m个视频第k个粒度的实例总数记为\(N_k^m\)。
定义一个标签向量 (y_k^m = [(y_1)k^m, \cdots , (y{N_km})_km])。其中,((y_i)_k^m)是第m个视频中第k个粒度第i个实例的标签。第k个粒度的权重记为(t_k)。
$$
p_m(y_1^m \cdots y_K^m) = \dfrac{\sum_{K=1}^{K}t_k(1^T y_k^m)}{2\sum_{k=1}^K t_k N_k^m} + \dfrac{1}{2}
$$
目标函数最终形式:
$$
\left.
\begin{aligned}
\min_{\{y^m\}_{m=1}^M , w, b} \dfrac{1}{2}\parallel w \parallel ^2 + C_p\sum_{m=1}^M \mid p_m(y_1^m \cdots y_K^m) - P_m \mid \\
+ C\sum_{m=1}^M \sum_{k=1}^K \sum _{i=1}^{N_k^m} t_k L((y_i)_k^m, (w^T(x_i)_k^m + b)) \\
\end{aligned}
\right.
$$
$$
s.t. P_m =
\left\{
\begin{aligned}
& 1 ~~~~ if ~~ Y_m = 1 \\
& 0 ~~~~ if ~~ Y_m = -1
\end{aligned}
\right. , m = 1, ..., M.
$$
上面的这个问题是个NP难度问题,不能在多项式时间求解。
2.6 优化过程
可以分为下面两种情况分别求解:
- 固定\(\{y^m\}_{m=1}^M\),求解\(w, b\)。这就变成了一个带权重的SVM。
$$ \min_{w, b} \dfrac{1}{2} \parallel w \parallel ^2 + C \sum_{m=1}^M \sum_{k=1}^K \sum_{i=1}^{N_k^m} t_k L((y_i)_k^m, (w^T(x_i)_k^m + b))$$
- 固定\(w, b\),更新实例标签\(\{y^m\}_{m=1}^M\),问题变成如下:
$$
\left.
\begin{aligned}
\min_{\{y_m\}_{m=1}^M} C \sum_{m=1}^M \sum_{k=1}^K \sum_{i=1}^{N_k^m} t_k L((y_i)_k^m, (w^T(x_i)_k^m + b)) \\
+ C_p\sum_{m=1}^M \mid p_m(y_1^m \cdots y_K^m) - P_m \mid
\end{aligned}
\right.
$$
三、实验结果
3.1 实验设置
在三个视频数据集上进行实验:
- TRECVID Multimedia Event Detection(MED)2011
- TRECVID Multimedia Event Detection(MED)2012
- Columbia Consumer Videos(CCV)
选取\textbf{SIFT}作为底层局部特征。
对于每个视频,每2s提取一帧,每帧缩放到 \(320 \times 240\) 大小。
代价参数 \(C\) 和 \(C_p\) 通过交叉验证从 \(\{0.01, 0.1, 1, 10, 100\}\) 中选取。
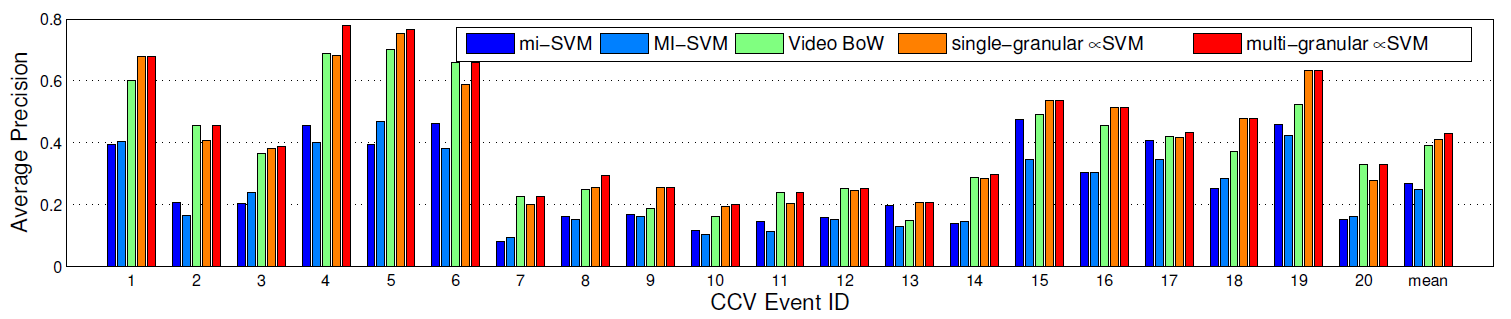
3.2 CCV 上的结果
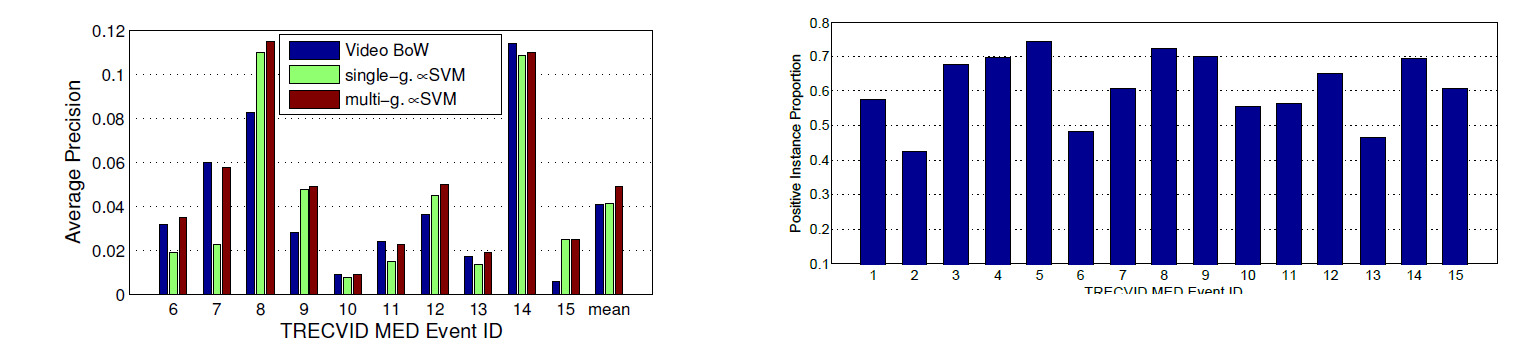
3.3 MED11 上的结果

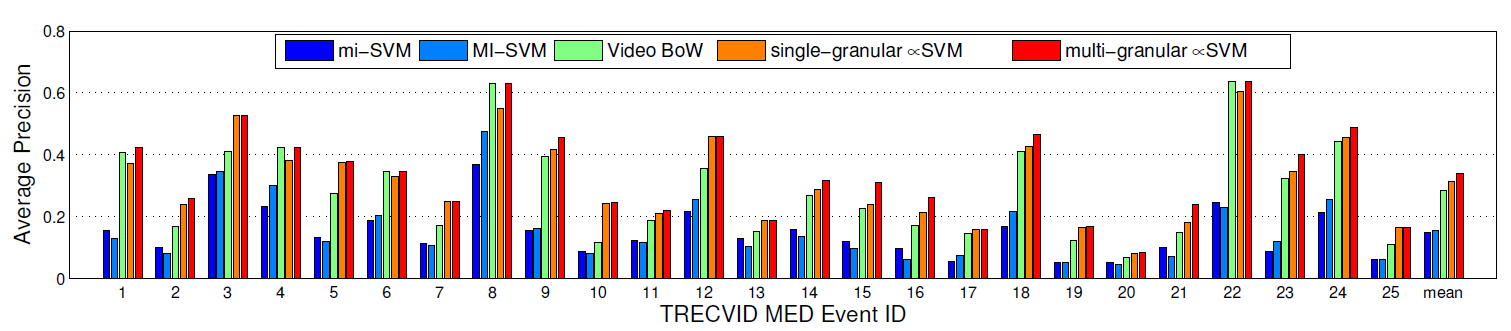
3.4 MED12 上的结果

四、Reference
###《Video Event Detection by Inferring Temporal Instance Lables》的更多相关文章
- ### Paper about Event Detection
Paper about Event Detection. #@author: gr #@date: 2014-03-15 #@email: forgerui@gmail.com 看一些相关的论文. 1 ...
- 【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection
A Discriminative CNN Video Representation for Event Detection Note here: it's a learning note on the ...
- 论文笔记:AdaScale: Towards real-time video object detection using adaptive scalingAdaScale
AdaScale: Towards real-time video object detection using adaptive scaling 2019-02-18 16:14:17 Paper: ...
- 《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》
<Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks> 论文主要的三个贡 ...
- video object detection
先说一下,我觉得近两年最好的工作吧.其他的,我就不介绍了,因为我懂得少. 微软的jifeng dai的工作. Deep Feature Flow github: https://github.co ...
- 《PDF.NE数据框架常见问题及解决方案-初》
<PDF.NE数据框架常见问题及解决方案-初> 1.新增数据库后,获取标识列的值: 解决方案: PDF.NET数据框架,已经为我们考略了很多,因为用PDF.NET进行数据的添加操作时 ...
- 《Single Image Haze Removal Using Dark Channel Prior》一文中图像去雾算法的原理、实现、效果(速度可实时)
最新的效果见 :http://video.sina.com.cn/v/b/124538950-1254492273.html 可处理视频的示例:视频去雾效果 在图像去雾这个领域,几乎没有人不知道< ...
- 《zw版·delphi与halcon系列原创教程》zw版_THOperatorSetX控件函数列表 v11中文增强版
<zw版·delphi与halcon系列原创教程>zw版_THOperatorSetX控件函数列表v11中文增强版 Halcon虽然庞大,光HALCONXLib_TLB.pas文件,源码就 ...
- 《精通Spring 4.X企业应用开发实战》读书笔记1-1(IoC容器和Bean)
很长一段时间关注在Java Web开发的方向上,提及到Jave Web开发就绕不开Spring全家桶系列,使用面向百度,谷歌的编程方法能够完成大部分的工作.但是这种不系统的了解总觉得自己的知识有所欠缺 ...
随机推荐
- hdu 1595 find the longest of the shortest【最短路枚举删边求删除每条边后的最短路,并从这些最短路中找出最长的那条】
find the longest of the shortest Time Limit: 1000/5000 MS (Java/Others) Memory Limit: 32768/32768 ...
- ALM11需求和测试覆盖率图解1
覆盖率分析视图 需求覆盖率选项卡
- 【Away3D代码解读】(四):主要模块简介
数据模块: Away3D中最核心的数据类是Mesh类,我们先看看Mesh类的继承关系: NamedAssetBase:为对象提供id和name属性,是Away3D大部分类的基类: Object3D:3 ...
- iOS 开发查看应用的沙盒文件
在iOS开发中,常常需要将一些信息保存到本地,比如说用户的一些搜索历史等.那么,如何查看所保存的文件呢? 这里介绍两种途径来查看应用的沙盒文件. 方法一:通过Xcode来查看,步骤如下: (1): X ...
- MySQL索引使用方法和性能优化
在自己的一个项目中,数据比较多,搜索也很频繁,这里找到一个建立索引很不错的文章,推荐下. 关于MySQL索引的好处,如果正确合理设计并且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的 ...
- 从零开始学android开发-查看sqlite数据库
C:\Users\Administrator>cd E:\ProSoft\adt-bundle-windows-x86-20140321\sdk\platform-tools
- Windows下配置PHP支持LDAP扩展方法(wampserver)
在网上搜了好多文章都不行呢,大都是没有开启扩展的问题,可是我的是开启的. 终于看到一篇文章,因为我用的是wampserver.下面是文章原话: 然后你发现上面的提示依旧,因为这是网上大多能查到的资料的 ...
- iOS利用视频做起始页
一个好的引导页会使得用户体验大大提升,利用视频来做,可以更简单的达到优雅的效果.使用MediaPlayer.framework框架下的AVPlayerLayer,它和Core Animation紧密地 ...
- 360开源的类Redis存储系统:Pika
Pika 是 360 DBA 和基础架构组联合开发的类 Redis 存储系统,完全支持 Redis 协议,用户不需要修改任何代码,就可以将服务迁移至 Pika.有维护 Redis 经验的 DBA 维护 ...
- Vmware中为Mac Os安装vmtools
成功方法: 1. 在VMWare中点击edit this virtual machine 2. 添加CD/DVD,使用iso,找到那个darwin.iso 3. 在setting里面,点击CD/DVD ...