Project2--Lucene的Ranking算法修改:BM25算法
原文出自:http://blog.csdn.net/wbia2010lkl/article/details/6046661
1. BM25算法
BM25是二元独立模型的扩展,其得分函数有很多形式,最普通的形式如下:
∑ 
其中,k1,k2,K均为经验设置的参数,fi是词项在文档中的频率,qfi是词项在查询中的频率。
K1通常为1.2,通常为0-1000
K的形式较为复杂
K=
上式中,dl表示文档的长度,avdl表示文档的平均长度,b通常取0.75
2. BM25具体实现
由于在典型的情况下,没有相关信息,即r和R都是0,而通常的查询中,不会有某个词项出现的次数大于1。因此打分的公式score变为
∑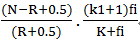
3. 使用Lucene实现BM25
Lucene本身的打分函数集中体现在tf·idf
为了简化实现过程,直接将代码中tf和idf函数的返回值修改为BM25打分公式的两部分。
文档的平均长度在索引建立的时候取得,同时在建立索引的过程中,将每个文档的docID与其长度,保存在一个hashMap中。
具体的函数实现如下(DefaulSimilarity类):
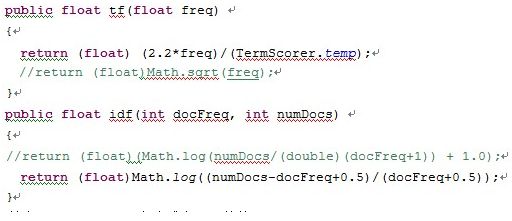
其中TermScore.temp为公式中K+fi的值
Temp的计算在TermScore类中进行计算:
public float score() {
assert doc != -1;
int f = freqs[pointer];
temp=(float)(1.2*(0.25+0.75*FileSearch.docToken.get(doc))+f);
System.out.println("weightValue: "+weightValue);
float raw = getSimilarity().tf(f)*weightValue; //
compute tf(f)*weight
//f < SCORE_CACHE_SIZE // check cache
//? scoreCache[f]*temp // cache hit
//: getSimilarity().tf(f)*weightValue*temp; // cache miss
System.out.println("score func doc id :"+doc+"
"+temp+" "+f+" "+
getSimilarity().tf(f));
System.out.println("raw value is"+raw);
return norms == null ?
raw : raw * SIM_NORM_DECODER[norms[doc]
& 0xFF];
}
值得注意的是:在lucene的得分计算中,使用explain函数可以看出,除了tf、idf的乘积之外,还有一个fieldNorm值,这个值的计算是基于索引的建立过程,与文档以及field的长度有关,综合考虑,这个值对于查询的过程还是比较有效的,因此在具体实现中,依然保存了fieldNorm的值。
Project2--Lucene的Ranking算法修改:BM25算法的更多相关文章
- 文本相似度 — TF-IDF和BM25算法
1,$TF-IDF$算法 $TF$是指归一化后的词频,$IDF$是指逆文档频率.给定一个文档集合$D$,有$d_1, d_2, d_3, ......, d_n \in D$.文档集合总共包含$m$个 ...
- 文本相似度-BM25算法
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms app ...
- Okapi BM25算法
引言 Okapi BM25,一般简称 BM25 算法,在 20 世纪 70 年代到 80 年代,由英国一批信息检索领域的计算机科学家发明.这里的 BM 是"最佳匹配"(Best M ...
- 分布式一致性算法:Raft 算法(论文翻译)
Raft 算法是可以用来替代 Paxos 算法的分布式一致性算法,而且 raft 算法比 Paxos 算法更易懂且更容易实现.本文对 raft 论文进行翻译,希望能有助于读者更方便地理解 raft 的 ...
- 【转】分布式一致性算法:Raft 算法(Raft 论文翻译)
编者按:这篇文章来自简书的一个位博主Jeffbond,读了好几遍,翻译的质量比较高,原文链接:分布式一致性算法:Raft 算法(Raft 论文翻译),版权一切归原译者. 同时,第6部分的集群成员变更读 ...
- Levenshtein Distance算法(编辑距离算法)
编辑距离 编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数.许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符, ...
- ISAP算法对 Dinic算法的改进
ISAP算法对 Dinic算法的改进: 在刘汝佳图论的开头引言里面,就指出了,算法的本身细节优化,是比较复杂的,这些高质量的图论算法是无数优秀算法设计师的智慧结晶. 如果一时半会理解不清楚,也是正常的 ...
- 算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification) 0.写在前面的话 我个人一直很喜欢算法一类的东西,在我看来算法是人类智慧的精华,其中蕴含着无与伦比 ...
- C++编程练习(11)----“图的最短路径问题“(Dijkstra算法、Floyd算法)
1.Dijkstra算法 求一个顶点到其它所有顶点的最短路径,是一种按路径长度递增的次序产生最短路径的算法. 算法思想: 按路径长度递增次序产生算法: 把顶点集合V分成两组: (1)S:已求出的顶点的 ...
随机推荐
- android安装apk
* 安装apk */ private void installApk() { // 获取当前sdcard存储路径 File apkfile = new File(Environment.getE ...
- EasyPlayer实现Android MediaMuxer录像MP4(支持G711/AAC/G726音频)
本文转自EasyDarwin开源团队John的博客:http://blog.csdn.net/jyt0551/article/details/72787095 Android平台的MediaMuxer ...
- iOS6和iOS7代码的适配(5)——popOver
popOver这个空间本身是iPad only的,所以iPhone上见不到,我记得微信上有个这样的弹出框,有扫一扫等几个菜单项,估计这是腾讯自己实现的,用于菜单的扩展. popOver从iOS6到iO ...
- 初识ADO.NET
摘要 作为.NET框架最重要的组件之一,ADO.NET扮演着应用程序与数据交互的重要的角色.本文将从宏观的角度来探讨ADO.NET,和大家一起了解ADO.NET来龙去脉以及ADO.NET的主要组成部分 ...
- INSTALL_FAILED_SHARED_USER_INCOMPATIBLE的问题
eclipse编译出来的apk,安装时报出INSTALL_FAILED_SHARED_USER_INCOMPATIBLE的错误. 原因:apk的AndroidManifest.xml中声明了andro ...
- sqlserver sql语句附加 分离数据库
当使用 sp_attach_db 系统存储过程附加数据库时- - Tag: 当使用 sp_attach_db 系统存储过程附加数据库时 //附加数据库 sp_attach_db 当使用 sp_atta ...
- Avro之一:Avro简介
一.引言 1. 简介 Avro是Hadoop中的一个子项目,也是Apache中一个独立的项目,Avro是一个基于二进制数据传输高性能的中间件.在Hadoop的其他项目中例如HBase(Ref)和Hiv ...
- crush class实验
标签(空格分隔): ceph,ceph实验,crushmap luminous版本的ceph新增了一个功能crush class,这个功能又可以称为磁盘智能分组.因为这个功能就是根据磁盘类型自动的进行 ...
- python开发初识函数:函数定义,返回值,参数
一,函数的定义 1,函数mylen叫做函数名 #函数名 #必须由字母下划线数字组成,不能是关键字,不能是数字开头 #函数名还是要有一定的意义能够简单说明函数的功能 2,def是关键字 (define) ...
- 五 搭建kafka集群
1 下载 wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.0.0/kafka_2.12-2.0.0.tgz 2 tar -zxv ...