Solr6.6.0 用 SimplePostTool索引文件的启示
本文主要是介绍通过SimplePostTool工具索引文件的结果进行确认,针对不同的文件,索引的结果不同。
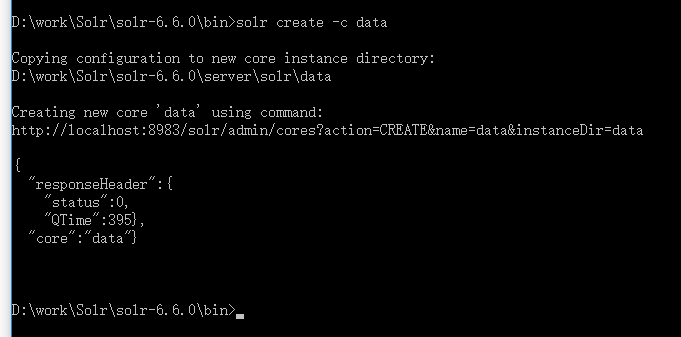
1、创建core
首先启动solr,建立名称为data的core,SimplePostTool工具使用参照:http://www.cnblogs.com/shaosks/p/7390523.html
由于导入文件的过程需要用到post.jar这个包,所以先把solr-6.6.0\example\exampledocs文件夹下的post.jar拷贝到solr-6.6.0\bin文件夹下。
solr start; solr create -c data
2、导入文件
和solr-6.6.0\bin文件夹同级目录下Import文件夹,下面有以下有8个文件:

其中前三个文件都是结构化的,有对应的字段。后面的文件就是非结构化的文件。现在导入
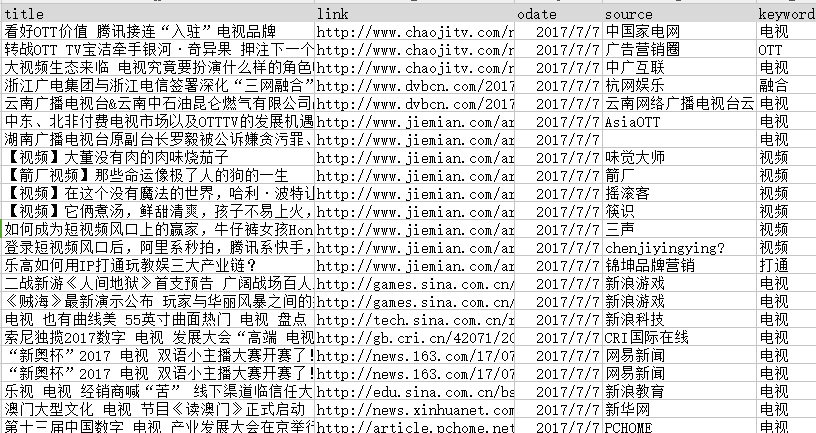
2.1、2017-07-07_info.csv文件
内容如下,需要注意的是csv文件由于包含中文,所以必须以utf-8格式保存,否则导入后,中文是乱码
2.2、books.json文件
内容如下,需要注意的是books.json格式不能保存为utf-8的格式,否则导入时报错。

2.3、xml文件
内容如下,需要注意的是xml文件由于包含中文,所以必须以utf-8格式保存,否则导入后,中文是乱码


导入命令: java -Dauto=yes -Dc=mycore -jar post.jar ..\Import\*.*

3、配置文件
注意data\conf下的配置文件managed-schema,注意里面的内容在导入前和导入后的变化,在导入后,对于上面的csv,json和json这三个结构化文档中涉及的字段,都会自动增加到managed-schema文档中
下面这些字段都是导入过程自动增加的

4、导入结果查询
1、2017-07-07_info.csv索引结果
奇怪的是原来csv文件中title字段,变为了_title,前面增加了一个下划线,经过多次测试,都第一个字段,增加一个下划线。

把文件中的title字段改为scheme,

重新导入,查询结果:scheme字段前面又增加了一个下划线

在CSV文件增加一列blank_title,该列都是空值

重新导入,结果正常,而且blank_title也不会索引

2、books.json索引结果

3、mem.xml索引结果

4、十九大报告全文.docx索引结果
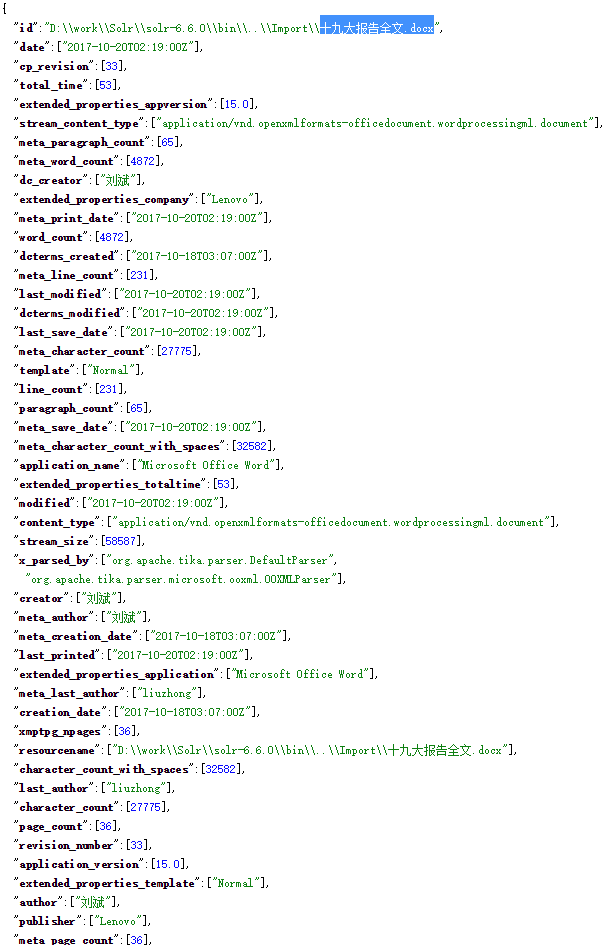
同样doc, pdf和txt格式的文件索引结果都是类似的,因此对这样的文件索引要用其它方式。
总结:SimplePostTool工具适合索引csv/json/xml这种结构化文档,像doc, pdf和txt这种非结构化,索引数据后无法搜索相关的信息
Solr6.6.0 用 SimplePostTool索引文件的启示的更多相关文章
- Solr6.6.0 用 SimplePostTool索引文件
一.背景介绍 Solr启动并运行之后,并不包含任何数据,在solr的安装目录下的bin目录中,有一个post工具,我们可以使用这个工具往solr上传数据,这个工具必须在命令行中执行,post工具是一个 ...
- Solr6.6.0 用 SimplePostTool索引文件 中文乱码
在用SimplePostTool工具导入CSV文件,文件内容如下: 启动solr ,利用命令导入:java -Dtype=text/csv -Dc=solr_test -jar post.jar .. ...
- Solr6.6.0 用 SimplePostTool与界面dataimport索引方式区别
通过测试发现用SimplePostTool与solr界面dataimport索引数据的结果有如下区别: 1.SimplePostTool索引数据对结构化数据文件索引比较合适,比如csv/json/xm ...
- Solr4.8.0源码分析(12)之Lucene的索引文件(5)
Solr4.8.0源码分析(12)之Lucene的索引文件(5) 1. 存储域数据文件(.fdt和.fdx) Solr4.8.0里面使用的fdt和fdx的格式是lucene4.1的.为了提升压缩比,S ...
- Solr4.8.0源码分析(11)之Lucene的索引文件(4)
Solr4.8.0源码分析(11)之Lucene的索引文件(4) 1. .dvd和.dvm文件 .dvm是存放了DocValue域的元数据,比如DocValue偏移量. .dvd则存放了DocValu ...
- Solr4.8.0源码分析(10)之Lucene的索引文件(3)
Solr4.8.0源码分析(10)之Lucene的索引文件(3) 1. .si文件 .si文件存储了段的元数据,主要涉及SegmentInfoFormat.java和Segmentinfo.java这 ...
- Solr4.8.0源码分析(9)之Lucene的索引文件(2)
Solr4.8.0源码分析(9)之Lucene的索引文件(2) 一. Segments_N文件 一个索引对应一个目录,索引文件都存放在目录里面.Solr的索引文件存放在Solr/Home下的core/ ...
- Solr4.8.0源码分析(8)之Lucene的索引文件(1)
Solr4.8.0源码分析(8)之Lucene的索引文件(1) 题记:最近有幸看到觉先大神的Lucene的博客,感觉自己之前学习的以及工作的太为肤浅,所以决定先跟随觉先大神的博客学习下Lucene的原 ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
随机推荐
- how to remove an element in lxml
import lxml.etree as et xml=""" <groceries> <fruit state="rotten"& ...
- RtlInitUnicodeString
代码1: WCHAR enumeratorName[] = {}; UNICODE_STRING unicodeEnumName; RtlInitUnicodeString(&unicodeE ...
- Download PuTTY: latest development snapshot
Download PuTTY: latest development snapshot https://www.chiark.greenend.org.uk/~sgtatham/putty/lates ...
- 【反演复习计划】【bzoj2154】Crash的数字表格
膜拜cdc……他的推导详细到我这种蒟蒻都能看得懂! 膜拜的传送门 所以我附一下代码就好了. #include<bits/stdc++.h> #define N 10000005 #defi ...
- 【SQL】事务
1.事务的开始结束: START TRANSACTION :标记事务开始 COMMIT :标记事务成功结束 ROLLBACK :标记事务夭折 2.设定事务只读.读写性质: SET TRANSACTIO ...
- 《Java编程思想》笔记 第六章 访问权限控制
1.编译单元 一个 编译单元即 .java 文件 内只能有一个 public 类 且该文件名必须与public 类名 完全一致. 编译单元内也可以没有public类 文件名可随意. 2. 包:库单元 ...
- ros 如何使用 openni2_launch
There is very little actual code/etc in openni2_launch, it is mostly a thin wrapper around openni2_c ...
- 构建maven动态web 工程
项目构建 总体参考: http://www.java2blog.com/2015/09/how-to-create-dynamic-web-project-using.html https://sta ...
- 自动清空Tomcat日志的办法
cd /usr/local/tomcat7/logs #清空日志 echo > catalina.out vi r.sh #!/bin/sh ########################## ...
- 洛谷 P1068 分数线划定【结构体排序】
题目描述 世博会志愿者的选拔工作正在 A 市如火如荼的进行.为了选拔最合适的人才,A 市对 所有报名的选手进行了笔试,笔试分数达到面试分数线的选手方可进入面试.面试分数线根 据计划录取人数的150%划 ...