Solr6.6.0 用 SimplePostTool索引文件的启示
本文主要是介绍通过SimplePostTool工具索引文件的结果进行确认,针对不同的文件,索引的结果不同。
1、创建core
首先启动solr,建立名称为data的core,SimplePostTool工具使用参照:http://www.cnblogs.com/shaosks/p/7390523.html
由于导入文件的过程需要用到post.jar这个包,所以先把solr-6.6.0\example\exampledocs文件夹下的post.jar拷贝到solr-6.6.0\bin文件夹下。
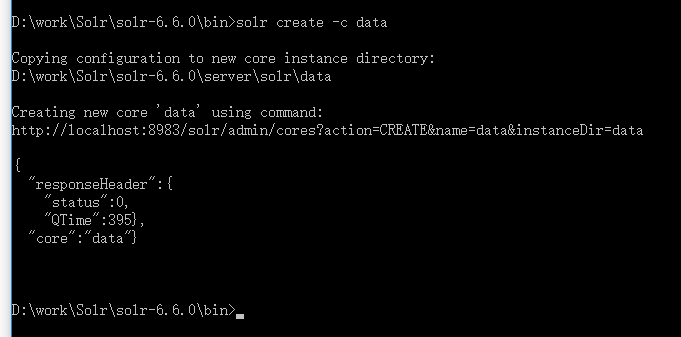
solr start; solr create -c data
2、导入文件
和solr-6.6.0\bin文件夹同级目录下Import文件夹,下面有以下有8个文件:

其中前三个文件都是结构化的,有对应的字段。后面的文件就是非结构化的文件。现在导入
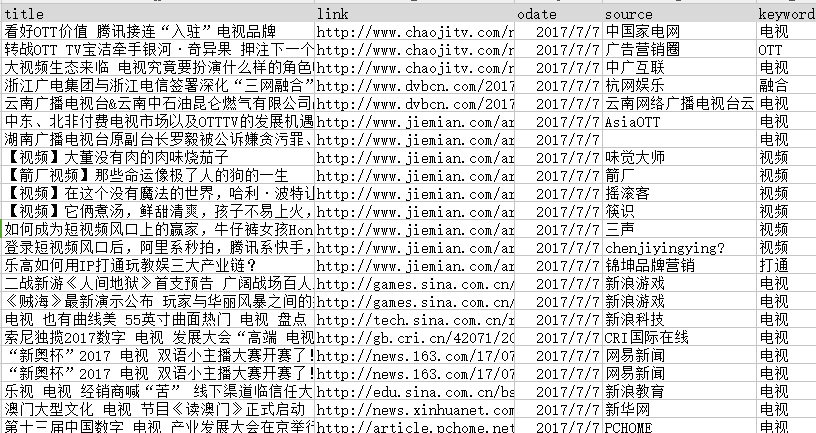
2.1、2017-07-07_info.csv文件
内容如下,需要注意的是csv文件由于包含中文,所以必须以utf-8格式保存,否则导入后,中文是乱码
2.2、books.json文件
内容如下,需要注意的是books.json格式不能保存为utf-8的格式,否则导入时报错。

2.3、xml文件
内容如下,需要注意的是xml文件由于包含中文,所以必须以utf-8格式保存,否则导入后,中文是乱码


导入命令: java -Dauto=yes -Dc=mycore -jar post.jar ..\Import\*.*

3、配置文件
注意data\conf下的配置文件managed-schema,注意里面的内容在导入前和导入后的变化,在导入后,对于上面的csv,json和json这三个结构化文档中涉及的字段,都会自动增加到managed-schema文档中
下面这些字段都是导入过程自动增加的

4、导入结果查询
1、2017-07-07_info.csv索引结果
奇怪的是原来csv文件中title字段,变为了_title,前面增加了一个下划线,经过多次测试,都第一个字段,增加一个下划线。

把文件中的title字段改为scheme,

重新导入,查询结果:scheme字段前面又增加了一个下划线

在CSV文件增加一列blank_title,该列都是空值

重新导入,结果正常,而且blank_title也不会索引

2、books.json索引结果

3、mem.xml索引结果

4、十九大报告全文.docx索引结果
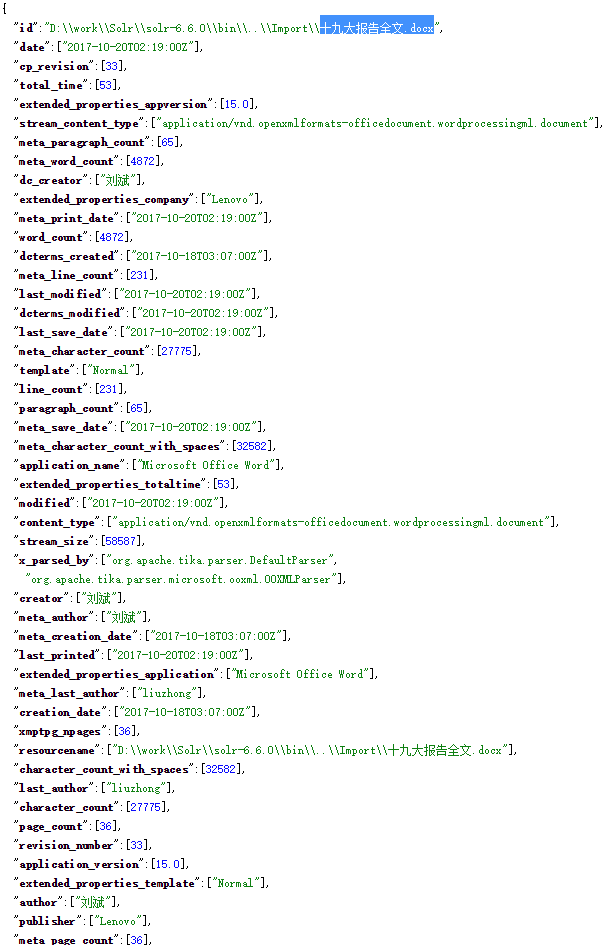
同样doc, pdf和txt格式的文件索引结果都是类似的,因此对这样的文件索引要用其它方式。
总结:SimplePostTool工具适合索引csv/json/xml这种结构化文档,像doc, pdf和txt这种非结构化,索引数据后无法搜索相关的信息
Solr6.6.0 用 SimplePostTool索引文件的启示的更多相关文章
- Solr6.6.0 用 SimplePostTool索引文件
一.背景介绍 Solr启动并运行之后,并不包含任何数据,在solr的安装目录下的bin目录中,有一个post工具,我们可以使用这个工具往solr上传数据,这个工具必须在命令行中执行,post工具是一个 ...
- Solr6.6.0 用 SimplePostTool索引文件 中文乱码
在用SimplePostTool工具导入CSV文件,文件内容如下: 启动solr ,利用命令导入:java -Dtype=text/csv -Dc=solr_test -jar post.jar .. ...
- Solr6.6.0 用 SimplePostTool与界面dataimport索引方式区别
通过测试发现用SimplePostTool与solr界面dataimport索引数据的结果有如下区别: 1.SimplePostTool索引数据对结构化数据文件索引比较合适,比如csv/json/xm ...
- Solr4.8.0源码分析(12)之Lucene的索引文件(5)
Solr4.8.0源码分析(12)之Lucene的索引文件(5) 1. 存储域数据文件(.fdt和.fdx) Solr4.8.0里面使用的fdt和fdx的格式是lucene4.1的.为了提升压缩比,S ...
- Solr4.8.0源码分析(11)之Lucene的索引文件(4)
Solr4.8.0源码分析(11)之Lucene的索引文件(4) 1. .dvd和.dvm文件 .dvm是存放了DocValue域的元数据,比如DocValue偏移量. .dvd则存放了DocValu ...
- Solr4.8.0源码分析(10)之Lucene的索引文件(3)
Solr4.8.0源码分析(10)之Lucene的索引文件(3) 1. .si文件 .si文件存储了段的元数据,主要涉及SegmentInfoFormat.java和Segmentinfo.java这 ...
- Solr4.8.0源码分析(9)之Lucene的索引文件(2)
Solr4.8.0源码分析(9)之Lucene的索引文件(2) 一. Segments_N文件 一个索引对应一个目录,索引文件都存放在目录里面.Solr的索引文件存放在Solr/Home下的core/ ...
- Solr4.8.0源码分析(8)之Lucene的索引文件(1)
Solr4.8.0源码分析(8)之Lucene的索引文件(1) 题记:最近有幸看到觉先大神的Lucene的博客,感觉自己之前学习的以及工作的太为肤浅,所以决定先跟随觉先大神的博客学习下Lucene的原 ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
随机推荐
- 网络基础(osi、协议)
*互联网协议 人和人沟通需要一套共同的标准,英语就是普遍的一种,计算机如果需要进行联网互通,也需要一种统一的标准,如果所有的计算机都遵守这种标准,就会实现网络的互联. 1.一系列统一的标准,这些标准称 ...
- Map占用内存大小评估
public class test { private static java.util.HashMap<String, String> needQueryResProductList = ...
- Git-回滚操作
git revert是用一次新的commit来回滚之前的commit,git reset是直接删除指定的commit git log 查询回滚版本唯一commit标识代码 git reset --ha ...
- Asp.Net Core 项目实战参考
Asp.Net Core 项目实战链接 http://www.cnblogs.com/fonour/p/5904530.html
- js 集合
[深入理解javascript原型和闭包系列 ] 历时半月完稿,求推荐 jQuery 学习笔记(未完待续) JavaScript作用域原理(三)——作用域根据函数划分
- tomcat并发优化
配置参考 <Connector port="9027" protocol="HTTP/1.1" maxHttpHeaderSize="8192& ...
- <div>之定位
在使用盒子模型的过程中,如何放置各种类型的“盒子”,就存在定位.浮动等问题.下面就日常运用过程中出现过的情况总结如下(陆续加入中....) 一.图片直接做<div>的背景 在<div ...
- (4)java基础知识
一.注释 java的注释方法主要有三种 1.单行注释 // 2.多行注释 /* 内容 */ 3.文档注释 /** * * */ 这种方法注释用于生成一份API文档,主要说明 方法的功能.参数.返回值 ...
- Difference between [0-9], [[:digit:]] and \d
Yes, it is [[:digit:]] ~ [0-9] ~ \d (where ~ means aproximate).In most programming languages (where ...
- centos 7 下发送邮件设置
使用sendmail发邮件的配置 yum -y install sendmailservice sendmail start vim body.txttest mail from linux. mai ...