java源码之LinkedHashMap
先盗两张图感受一下(来自:https://blog.csdn.net/justloveyou_/article/details/71713781)
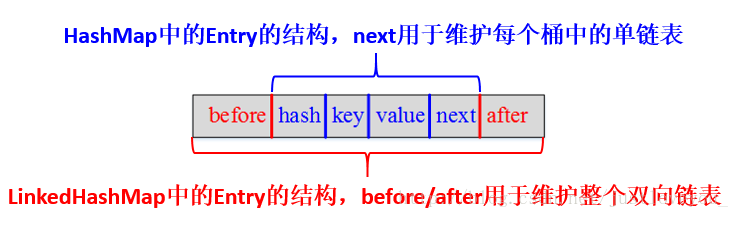
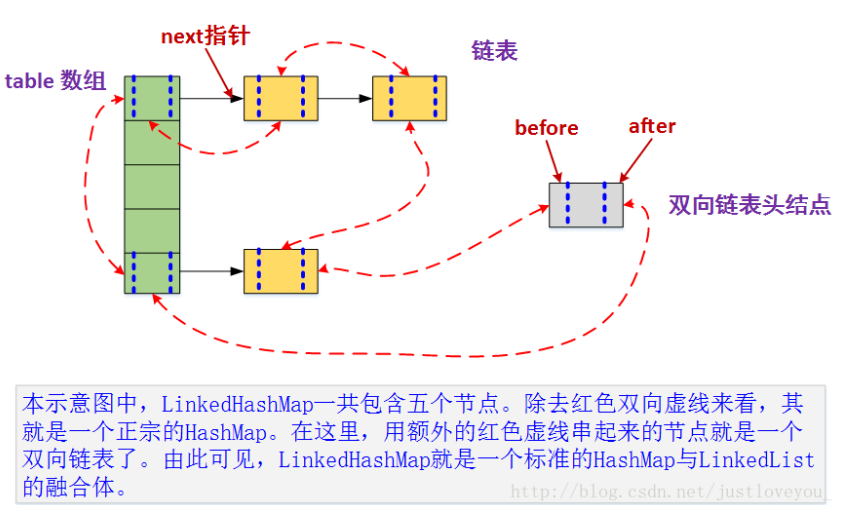
HashMap和双向链表的密切配合和分工合作造就了LinkedHashMap。特别需要注意的是,next用于维护HashMap各个桶中的Entry链,before、after用于维护LinkedHashMap的双向链表,虽然它们的作用对象都是Entry,但是各自分离,是两码事儿。
源码分析
1、LinkedHashMap的继承结构
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
从结构可以看出,LinkedHashMap继承HashMap并实现了Map接口。
2、LInkedHashMap构造函数
下面几个是LinkedHashMap的构造函数,每个构造函数都是直接调用父类HashMap的构造函数来完成相应的初始化工作。唯一的不同在于对变量:accessOrder 指定为 false。
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
构造函数中所提到的accessOrder
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
根据注释,理解如下:
accessOrder,简单说就是这个用来控制元素的顺序,
accessOrder为true: 表示按照访问的顺序来,也就是谁最先访问,就排在第一位
accessOrder为false表示按照存放顺序来,就是你put元素的时候的顺序。
3、LinkedHashMap类中的内部类Entry
Entry类继承的是HashMap.Node类,且引入了两个属性before/after,HashMap就是利用HashMap.Node类实现的单链表,再加上借助一个存储HashMap.Node的数组就实现了“数组链表”的结合体。而LinkedHashMap引入before/after两个属性,可以看出,是准备实现双向链表的,因此LinkedHashMap将是“数组和双链表”的结合体。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
//下面为HashMap的Node类
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
4、put方法
既然是集合,肯定会有put方法来往容器中添加元素,在LinkedHashMap搜索了半天,没有找到,在找put方法的过程中,发现有get方法,怎么会没有put方法呢??想了下,唯一的可能就是LinkedHashMap继承了HashMap没有重写HashMap中的put方法也。
下面我们贴出HashMap的put方法,看看这个put方法在LinkedHashMap中是如何来工作的。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;//重新开辟一个Node<K,V>的数组
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//1------LinkedHashMap
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
//2、LinkedHashMap
afterNodeInsertion(evict);
return null;
}
上面就是HashMap中put方法的代码,在看LinkedHashMap源码之前看HashMap的时候,看到put方法中调用afterNodeAccess(e)和afterNodeInsertion(evict);而这两个方法在HashMap是两个空实现的方法:
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
当时,还在郁闷,为什么调用了两个空实现的函数呢??
现在,看了LinkedHashMap的源码,原来这两个函数是专门给LinkedHashMap重写用的。只要LinkedHashMap重写了这两个函数,也就完成了LinkedHashMap自己的put方法实现。
put方法的思路在HashMap中已经分析过了,大致如下:根据key的hash值得到存储位置,然后判断该存储位置是否已经有了元素,如果有了,则在该位置的链表中,找是否含有该key,如果有该key,则更新value。如果没有找到,则将节点插入到该位置的链表头。
现在,由于针对的是LinkedHashMap,因此思路稍微发生了点变化,在链表中找到key之后调用了afterNodeAccess函数,LinkedHashMap中的此函数不再为空,如果没有找到key,在插入节点之后返回之前,调用了afterNodeInsertion方法。
下面我们就来看下这两个函数的具体内容。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//accessOrder 为true时,才会进入下面if的语句块中
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
/*
调整链表指向,将e的前一个节点和后一个节点连接起来
*/
if (b == null)//前一个节点为null的情况
head = a;
else
b.after = a;
if (a != null)//后一个节点不为null的情况
a.before = b;
else
last = b;
//将p节点放在链表的最后面
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
下面介绍afterNodeInsertion(boolean evict)
从源码中可以看到,这个函数相当于什么都没有做。
原因为:removeEldestEntry函数一直返回false,导致这个函数afterNodeInsertion的if条件也就一直为false。
因此,不知道这个函数为什么这么写,分析了下,由于LinkedHashMap当accessOrder为false时,要按照添加元素的顺序进行维护链表,而HashMap就是直接将新节点放入到链表头,因此这个函数也就不需要做什么了。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
以上就是关于LinkedHashMap的put方法,
LinkedHashMap与HashMap的区别真心不大,从put方法上可以看出,唯一的区别在于,如果我们设置了accessOrder = true,则会将访问的节点放入到链表的尾结点处,其它的都一样。
5、get方法
get方法的思路虽然对HashMap的get方法进行了重写,但基本与HashMap的思路一致:也是直接调用getNode获取到节点对象,然后返回其值。
但是,在LinkedHashMap中,由于需要有顺序需要维护,因此,当accessOrder = true 时,则需要调用afterNodeAccess(e)方法将此节点放到双向链表的末尾。而如果accessOrder = false.则完全与HashMap类中的get方法一模一样。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
6、getOrDefault方法
getOrDefault方法与get方法唯一的区别在于,如果key不存在,则返回默认值而不是返回null。
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
LinkedHashMap类中其它的方法基本与HashMap类中的方法差不多,这里就不再进行介绍。
小结
LinkedHashMap 和hashMap 功能基本一样,都是维护的键值对集合,连遍历 以及方法都类似,唯一的区别在于HashMap 里面的元素是根据hash值来决定存放位置的,是无序的,而LinkedHashMap 维护的是一个按顺序存放的双向链表,是有序的。
LinkedHashMap是HashMap+LinkList。
转自:https://blog.csdn.net/u010412719/article/details/51984455
java源码之LinkedHashMap的更多相关文章
- 【数据结构】10.java源码关于LinkedHashMap
目录 1.LinkedHashMap的内部结构 2.LinkedHashMap构造函数 3.元素新增策略 4.元素删除 5.元素修改和查找 6.特殊操作 7.扩容 8.总结 1.LinkedHashM ...
- Java源码阅读LinkedHashMap
1类签名与注释 public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> 哈 ...
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- Java源码系列1——ArrayList
本文简单介绍了 ArrayList,并对扩容,添加,删除操作的源代码做分析.能力有限,欢迎指正. ArrayList是什么? ArrayList 就是数组列表,主要用来装载数据.底层实现是数组 Obj ...
- Java源码系列2——HashMap
HashMap 的源码很多也很复杂,本文只是摘取简单常用的部分代码进行分析.能力有限,欢迎指正. HASH 值的计算 前置知识--位运算 按位异或操作符^:1^1=0, 0^0=0, 1^0=0, 值 ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- Android反编译(一)之反编译JAVA源码
Android反编译(一) 之反编译JAVA源码 [目录] 1.工具 2.反编译步骤 3.实例 4.装X技巧 1.工具 1).dex反编译JAR工具 dex2jar http://code.go ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
随机推荐
- Hadoop(2)_机器信息分布表
1.分布式环境搭建 采用4台安装Linux环境的机器来构建一个小规模的分布式集群. 图1 集群的架构 其中有一台机器是Master节点,即名称节点,另外三台是Slaver节点,即数据节点.这四台机器彼 ...
- POJ 2407
裸 的求欧拉函数 #include <iostream> #include <cstdio> #include <cstring> #include <alg ...
- ISAM Indexed Sequential Access Method 索引顺序存取方法
ISAM Indexed Sequential Access Method 索引顺序存取方法 学习了:https://baike.baidu.com/item/ISAM/3013855 是IBM发展起 ...
- [Angular] Service Worker Version Management
If our PWA application has a new version including some fixes and new features. By default, when you ...
- sqlite学习笔记6:更新表数据-update
一 条件推断 在SQL中条件推断使用where,相当于其它变成语言中的if,基本使用方法如: SELECT column1, column2, columnN FROM table_name WHER ...
- C# 用ManulResetEvent 控制Thread的 Suspend、Resume
class Program { static void Main(string[] args) { Thread thread = new Thread(Work); thread.Start(); ...
- NDK历史版本
https://developer.android.google.cn/ndk/downloads/older_releases.html https://developer.android.goog ...
- 编译安装FFmpeg 要支持xvid、x264、mp3、ogg、amr、faac
编译安装FFmpeg 要支持xvid.x264.mp3.ogg.amr.faac libfaac faac格式的编解码包libmp3lame mp3格式编解码包libopencore-am ...
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- Kafka.net使用编程入门
最近研究分布式消息队列,分享下! 首先zookeeper 和 kafka 压缩包 解压 并配置好! 我本机zookeeper环境配置如下: D:\Worksoftware\ApacheZookeep ...