Python爬虫基础之lxml
一、Python lxml的基本应用
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
; and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
1.使用lxml.etree和lxml.cssselect解析html源码
from lxml import etree, cssselect
from cssselect import GenericTranslator, SelectorError parser = etree.HTMLParser(remove_blank_text=True)
document = etree.fromstring(html_doc, parser) # 使用CSS选择器
sel = cssselect.CSSSelector('p a')
results_sel_href = [e.get('href') for e in sel(document)] # 打印a标签的href属性
results_sel_text = [e.text for e in sel(document)] # 打印<a></a>之间的文本
print(results_sel_href)
print(results_sel_text) # 使用CSS样式
results_css = [e.get('href') for e in document.cssselect('p a')]
print(results_css) # 使用xpath
try:
expression = GenericTranslator().css_to_xpath('p a')
print(expression)
except SelectorError:
print('Invalid selector.') results_xpath = [e.get('href') for e in document.xpath(expression)] # document.xpath('//a')
print(results_xpath)
2.cleaning up html
使用html清理器,可以移除一些嵌入的脚本、标签、CSS样式等html元素,这样可以提高搜索效率。
# cleaning up html
# 1.不使用Cleaner
from lxml.html.clean import Cleaner
html_after_clean = clean_html(html_doc)
print(html_after_clean)
# <div>
# The Dormouse's story
# <body>
# <p class="title">
# <b>
# The Dormouse's story
# </b>
# </p>
# <p class="story">
# Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">
# Elsie
# </a>
# ,
# <a class="sister" href="http://example.com/lacie" id="link2">
# Lacie
# </a>
# and
# <a class="sister" href="http://example.com/tillie" id="link3">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p class="story">
# ...
# </p>
# </body>
# </div> # 2.使用Cleaner
cleaner = Cleaner(style=True, links=True, add_nofollow=True, page_structure=False, safe_attrs_only=False)
html_with_cleaner = cleaner.clean_html(html_doc)
print(html_with_cleaner)
# <html>
# <head>
# <title>
# The Dormouse's story
# </title>
# </head>
# <body>
# <p class="title">
# <b>
# The Dormouse's story
# </b>
# </p>
# <p class="story">
# Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">
# Elsie
# </a>
# ,
# <a class="sister" href="http://example.com/lacie" id="link2">
# Lacie
# </a>
# and
# <a class="sister" href="http://example.com/tillie" id="link3">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p class="story">
# ...
# </p>
# </body>
# </html>
二、Python lxml的实际应用
1.解析网易云音乐html源码
这是网易云音乐华语歌曲的分类链接http://music.163.com/#/discover/playlist/?order=hot&cat=华语&limit=35&offset=0,打开Chrome F12的Elements查看到页面源码,我们发现每页的歌单都在一个iframe浮窗上面,每首单曲的信息构成一个li标签,包含歌单图片、
歌单链接、歌单名称等。
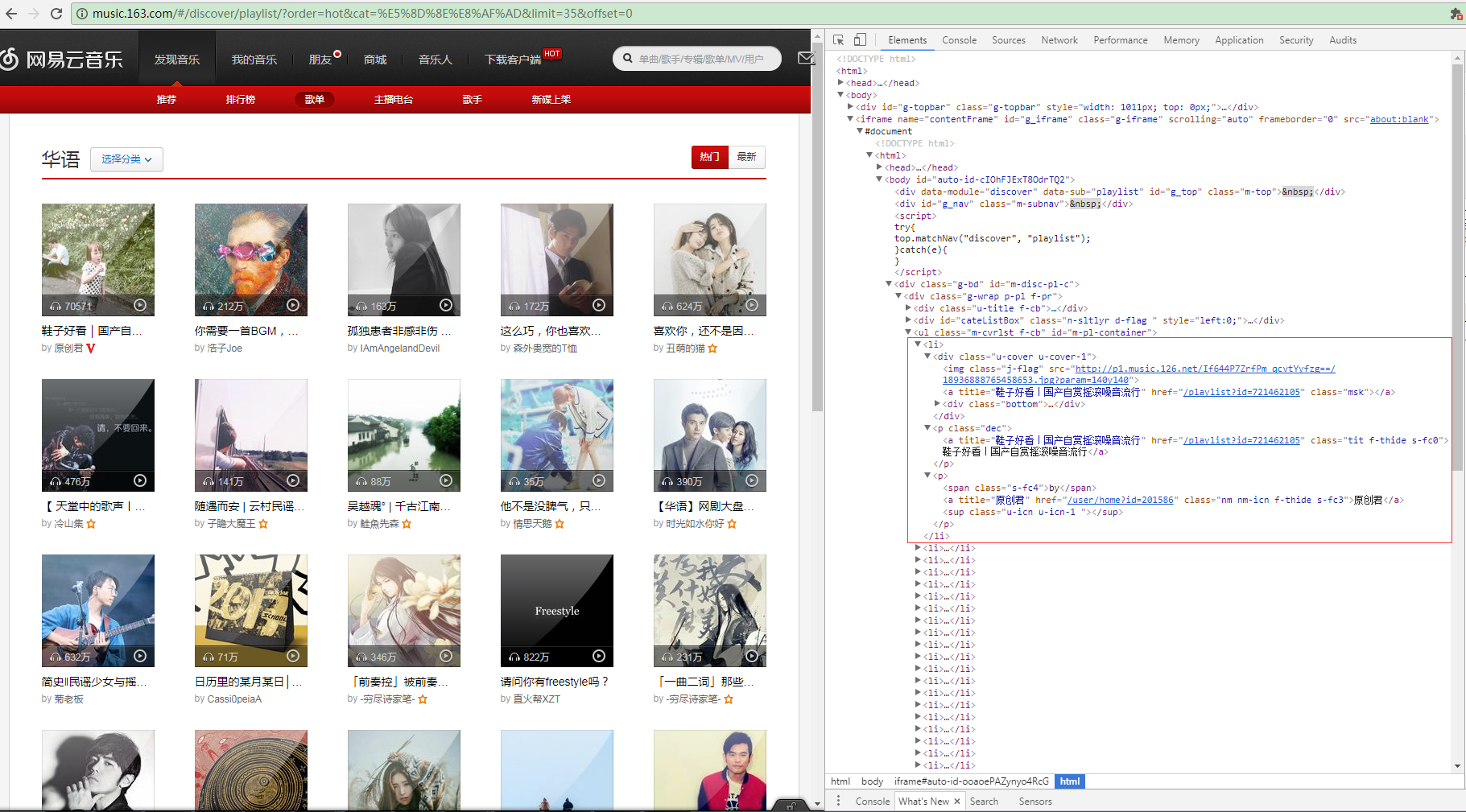
<ul class="m-cvrlst f-cb" id="m-pl-container">
<li>
<div class="u-cover u-cover-1">
<img class="j-flag" src="http://p1.music.126.net/FGe-rVrHlBTbnOvhMR99PQ==/109951162989189558.jpg?param=140y140" />
<a title="【说唱】留住你一面,画在我心间" href="/playlist?id=832790627" class="msk"></a>
<div class="bottom">
<a class="icon-play f-fr" title="播放" href="javascript:;" data-res-type="13" data-res-id="832790627" data-res-action="play"></a>
<span class="icon-headset"></span>
<span class="nb">1615</span>
</div>
</div> <p class="dec"> <a title="【说唱】留住你一面,画在我心间" href="/playlist?id=832790627" class="tit f-thide s-fc0">【说唱】留住你一面,画在我心间</a> </p> <p><span class="s-fc4">by</span> <a title="JediMindTricks" href="/user/home?id=17647877" class="nm nm-icn f-thide s-fc3">JediMindTricks</a> <sup class="u-icn u-icn-84 "></sup> </p> </li>
<li>
<div class="u-cover u-cover-1">
<img class="j-flag" src="http://p1.music.126.net/If644P7ZrfPm_qcvtYyfzg==/18936888765458653.jpg?param=140y140" />
<a title="鞋子好看|国产自赏摇滚噪音流行" href="/playlist?id=721462105" class="msk"></a>
<div class="bottom">
<a class="icon-play f-fr" title="播放" href="javascript:;" data-res-type="13" data-res-id="721462105" data-res-action="play"></a>
<span class="icon-headset"></span>
<span class="nb">77652</span>
</div>
</div> <p class="dec"> <a title="鞋子好看|国产自赏摇滚噪音流行" href="/playlist?id=721462105" class="tit f-thide s-fc0">鞋子好看|国产自赏摇滚噪音流行</a> </p> <p><span class="s-fc4">by</span> <a title="原创君" href="/user/home?id=201586" class="nm nm-icn f-thide s-fc3">原创君</a> <sup class="u-icn u-icn-1 "></sup> </p> </li>
</ul>
开始解析html源码
首先实例化一个etree.HTMLParser对象,对html源码简单做下处理,创建cssselect.CSSSelector CSS选择器对象,搜索出无序列表ul下的所有li元素(_Element元素对象),再通过sel(document)遍历所有的_Element对象,使用find方法
find(self, path, namespaces=None) Finds the first matching subelement, by tag name or path. (lxml.ettr/lxml.cssselect 详细API请转义官网http://lxml.de/api/index.html)
通过xpath找到li的子元素img和a,通过_Element的属性attrib获取到属性字典,成功获取到歌单的图片链接,歌单列表链接和歌单名称。
from lxml import etree, cssselect html = '''上面提取的html源码'''
parser = etree.HTMLParser(remove_blank_text=True)
document = etree.fromstring(html_doc, parser) sel = cssselect.CSSSelector('#m-pl-container > li')
for e in sel(document):
img = e.find('.//div/img')
img_url = img.attrib['src']
a_msk = e.find(".//div/a[@class='msk']")
musicList_url = 'http:/%s' % a_msk.attrib['href']
musicList_name = a_msk.attrib['title']
print(img_url,musicList_url,musicList_name)
Python爬虫基础之lxml的更多相关文章
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python爬虫基础之认识爬虫
一.前言 爬虫Spider什么的,老早就听别人说过,感觉挺高大上的东西,爬网页,爬链接~~~dos黑屏的数据刷刷刷不断地往上冒,看着就爽,漂亮的校花照片,音乐网站的歌曲,笑话.段子应有尽有,全部都过来 ...
- python 爬虫基础知识一
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 网络爬虫必备知识点 1. Python基础知识2. P ...
- Python爬虫基础(一)——HTTP
前言 因特网联系的是世界各地的计算机(通过电缆),万维网联系的是网上的各种各样资源(通过超文本链接),如静态的HTML文件,动态的软件程序······.由于万维网的存在,处于因特网中的每台计算机可以很 ...
- 【学习笔记】第二章 python安全编程基础---python爬虫基础(urllib)
一.爬虫基础 1.爬虫概念 网络爬虫(又称为网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或脚本.用爬虫最大的好出是批量且自动化得获取和处理信息.对于宏观或微观的情况都可以多一个侧面去了 ...
随机推荐
- 软工+C(4): Alpha/Beta换人
// 上一篇:超链接 // 下一篇:工具和结构化 注:在一次软件工程讨论课程进度设计的过程中,出现了这个关于 Alpha/Beta换人机制的讨论,这个机制在不同学校有不同的实施,本篇积累各方观点,持续 ...
- Manifest merger failed : Attribute application@icon value=(@mipmap/ic_launcher) from AndroidManifest
情况是这样子的,导入一个比较老的项目(两年前),它依赖于一个 Libraray,已经先导入了 library,现在导入项目的时候出了错 (1) Android Studio 目前提供将 SDK包成 . ...
- RabbitMQ消息队列
RabbitMQ消息队列 !!! 注意,保证服务器的内存足够,磁盘足够,以及删除/etc/hosts中没有用的dns解析 # 优点,能够保证消息数据持久化,不丢失,支持高并发 安装学习rabbitm ...
- npm link & unlink
npm link & unlink https://dev.to/erinbush/npm-linking-and-unlinking-2h1g
- C# call webservice方法
https://www.cnblogs.com/Fooo/p/5507153.html
- P1438 无聊的数列 (差分+线段树)
题目 P1438 无聊的数列 解析: 先考虑修改,用差分的基本思想,左端点加上首项\(k\),修改区间\((l,r]\)内每个数的差分数组都加上公差\(d\),最后的\(r+1\)再减去\(k+(r- ...
- Dlib Opencv cv2.fitEllipse用于人眼轮廓椭圆拟合
dlib库的安装以及人脸特征点的识别分布分别在前两篇博文里面 Dlib Python 检测人脸特征点 Face Landmark Detection Mac OSX下安装dlib (Python) 这 ...
- Sublime Text 3 安装简记
1.下载:( Sublime Text Version 3.1.1 Build 3176 ) https://www.sublimetext.com/3 2.安装Package Control: &q ...
- 如何在Linux中使用命令行卸载软件
您可以使用“dpkg”命令来查看您的计算机,按“Ctrl + Alt + T”的所有已安装包的列表,打开一个终端窗口. 在提示符下键入以下命令,然后按Enter键.dpkg -- list 要卸载程序 ...
- 我的python中级班学习之路(全程笔记第一模块) (第一章)(第2部分:如何设置python中的字体颜色,猜年龄练习题解答,while else语句,pycharm的使用)
第一章: python 基础语法 第 2 部分: 一.猜年龄练习题解答 直接上代码 >>> age = 26 >>> count = 0 >>&g ...