Chinese word segment based on character representation learning 论文笔记
|
论文名和编号 |
摘要/引言 |
相关背景和工作 |
论文方法/模型 |
实验(数据集)及 分析(一些具体数据) |
未来工作/不足 |
是否有源码 |
|||
|
问题 |
原因 |
解决思路 |
优势 |
||||||
|
基于表示学习的中文分词 编号:1001-9081(2016)10-2794-05 |
1.为提高中文分词的准确率和未登录词识别率。 |
1.分词后计算机才能得知中文词语的确切边界,进而理解文本中所包含的语义信息。中文分词是中文自然语言处理的一项基础性工作,是中文信息处理技术发展的技术瓶颈。 |
1.使用skip-gram模型将文本中的词映射为高维向量空间中的向量;其次用K-means聚类算法将词向量聚类,并将聚类结果作为条件随机场(CRF)模型的特征进行训练;最后基于该语言模型进行分词和未登录词识别。 |
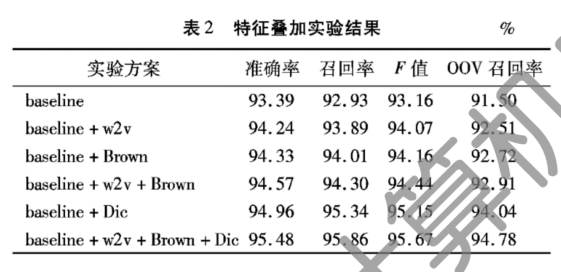
1.在未利用外部知识的条件下,分词的F值和OOV识别率分别达到了95.67%和94.78%,证明将此地聚类特征加入到条件随机场模型中能有效提高中文短文本的分词性能。 |
1.中文分词和未登录词识别都可以看作一个序列标记任务来完成,应用广泛的序列标注模型主要有隐马尔科夫模型(HMM)、最大熵马尔可夫模型(MEMM)和条件随机场模型(CRF)等。其中CRF比HMM和MEMM更能灵活地选择特征和控制训练数据地拟合程度。但是传统地CRF模型的使用难以避免“词汇鸿沟”,因为其大多使用基于词袋模型的特征表示,另外低频词也容易导致训练不足,及过拟合现象。 2.2006年Hinton等提出深度学习后,从大量未标记文本中学习字的方法已经被证实是对识别未登录词、命名实体识别、词性标注和依存分析有效的了。 |
1.简要说明:先从大量未标记的微博语料中学习中文字符的语义向量,基于这些语义向量作K-means聚类,同时对中文字符进行布朗聚类,然后再将这些字的表示特征应用于CRF模型中进行有监督的中文分词。 2.具体框架:先用空格将原始文本全部分开,然后利用word2vec对处理后的预料进行学习以得到字符的向量表示。接着利用K-means聚类算法得到字的一种聚类类别。最后将两种不同的聚类结果最为CRF的特征训练语言模型。 |
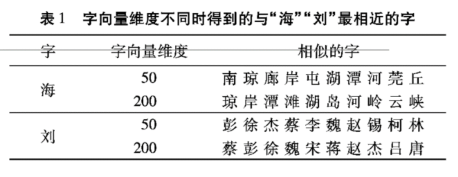
1.数据:采用NLPCC2015中文微博文本分词任务所提供的训练(1.96MB,共10000个句子,215567个词)及测试(662KB,共5000个句子,106843个词)语料。 2.如图2,测试了利用word2vec训练得到的不同维度的字向量以及K-means聚类类别数不同的情况下对分词结果的影响,以分词结果F值为参考。当向量维度d=200,K-means聚类类别数k=400时分词效果较好,F值达到94.07%。F值随着字向量维度d值的增大而趋于平滑,意味着随着向量维度的增加,向量所表示的字的语义信息更为全面和准确,聚类特征表现得更良好。 同时从聚类结果也可看出,党字向量维度增大时,聚类结果中各类别所包含的字的语义表现得更为相近。如表1,当字向量维度较大时,类别内部的字之间的相似度更好,语义更相关。 3.图3对比了布朗聚类与字向量分别为200维和300维时K-means聚类在类别数不同时对分词结果的影响。当类别数k=200时,布朗聚类对分词结果的影响达到峰值,其后分词效果随着k值的增加而递减。整体而言,当类别数k值较小时,布朗聚类效果比K-means聚类效果更好,随着k值的增大,布朗聚类的效果比K-means聚类的效果下降的更快。 4.综上,仅加入字向量的K-means聚类特征时,在d=200,k=400时分词效果达到最佳,仅加入字的布朗聚类特征时,在k=200时CRF分词效果达到最佳。 5.相对于baseline结果,两种不同的字表示方法的加入均对分词结果有积极作用,且布朗聚类优于K-means聚类,两者共同使用时效果优于只使用任意一种的效果,最高值达到94.44%,OOV召回率达到92.91%,相对baseline分别提升了1.28%和1.41%,说明两种不同聚类表示提供了不同的信息,弥补了各自部分的缺点。 6.引用词典知识也可降低未登录词和交叠歧义对分词结果的影响,词典中的词均来源于NLPCC提供的已有正确标记序列的微博语料。结果显示,引用词典特征后,F值和OOV召回率比baseline分别提高了1.99%和2.54%,说明了词典引入的重要性。同时,在引入词典特征的基础上再叠加使用两种字的表示特征后,F值和OOV召回率相比仅加入词典特征再次提高了0.52%和0.74%,体现了字表示对中文分词结果的改善作用。 |
1.对语料中不同长度的字块进行表示学习,如2-gram字块和3-gram字块,将其加入到CRF型中,通过多长度的表示学习来提高分词准确率。 2.增加外部知识学习,扩大语料库,进行开放测试并提升其分词效果。 |
无 |


Chinese word segment based on character representation learning 论文笔记的更多相关文章
- Hierarchical Attention Based Semi-supervised Network Representation Learning
Hierarchical Attention Based Semi-supervised Network Representation Learning 1. 任务 给定:节点信息网络 目标:为每个节 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(一)K-means特征学习
Deep Learning论文笔记之(一)K-means特征学习 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Deep Learning论文笔记之(三)单层非监督学习网络分析
Deep Learning论文笔记之(三)单层非监督学习网络分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记
Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记 2018年12月03日 00: ...
- [CVPR 2017] Semantic Autoencoder for Zero-Shot Learning论文笔记
http://openaccess.thecvf.com/content_cvpr_2017/papers/Kodirov_Semantic_Autoencoder_for_CVPR_2017_pap ...
- Correlation Filter in Visual Tracking系列二:Fast Visual Tracking via Dense Spatio-Temporal Context Learning 论文笔记
原文再续,书接一上回.话说上一次我们讲到了Correlation Filter类 tracker的老祖宗MOSSE,那么接下来就让我们看看如何对其进一步地优化改良.这次要谈的论文是我们国内Zhang ...
随机推荐
- Python内置函数(55)——round
英文文档: round(number[, ndigits]) Return the floating point value number rounded to ndigits digits afte ...
- Grapher--寂寞无名的神器
承自上一篇中的函数图形,有人问,能不能别把画个图搞那么复杂,我说当然,只要你有一台mac. 话说出来很潇洒的样子,充斥着一股迷之自信. 可能这就是mac用户典型的特征,尽管也许并没有那么值得骄傲. 其 ...
- 《HelloGitHub月刊》第 10 期
前言 这一年感谢大家的支持,小弟这里给大家拜年了! <HelloGitHub月刊>会一直做下去,欢迎大家加入进来提供更多的好的项目. 最后,祝愿大家:鸡年大吉- <HelloGitH ...
- TypeScript 基础知识点整理
一.TypeScript的特点 1.支持ES6规范 2.强大的IDE支持(集成开发环境) 允许为变量指定类型,减少你在开发阶段犯错误的几率. 语法提示,在IDE编写代码时,它会根据你所处的上下文把你能 ...
- Spring Cloud-微服务架构集大成者
本文不是讲解如何使用Spring Cloud的教程,而是探讨Spring Cloud是什么,以及它诞生的背景和意义. 1 背景 2008年以后,国内互联网行业飞速发展,我们对软件系统的需求已经不再是过 ...
- msf登陆Windows 2
使用ms17_010(永恒之蓝)进行攻击登陆(XP) 1)加载模块 2)连接靶机 3)设置payload 4)设置lhost(攻击主机IP) 5)exploit进行攻击登陆
- web进修之—Hibernate起步(1)(2)
想开始写博客了,尝试了CSDN和cnblog之后还是觉得cnblog更加简洁.专注(不过cnblog不支持搬家),所以把刚刚写的两篇学习博客链接放在这儿,这样这个系列也算是完整了: web进修之—Hi ...
- linux下(fdisk,gdisk,parted)三种分区工具比较
1 2种分区结构简介 MBR分区 硬盘主引导记录MBR由4个部分组成 主引导程序(偏移地址0000H--0088H),它负责从活动分区中装载,并运行系统引导程序. 出错信息数据区,偏移地址0089H- ...
- Linux基础知识第八讲,系统相关操作命令
目录 Linux基础知识第八讲,系统相关操作命令 一丶简介命令 2.磁盘信息查看. 3.系统进程 Linux基础知识第八讲,系统相关操作命令 一丶简介命令 时间和日期 date cal 磁盘和目录空间 ...
- 【Linux】Rsync的剖析与使用
目录 Rsync的工具剖析与使用 0.Rsync的介绍 1.Rsync的特性 2.Rsync的部署安装 3.搭建远程备份系统. Rsync的工具剖析与使用 0.Rsync的介绍 rsync是Linux ...