利用R与SAS进行关联规则挖掘
一、利用R进行关联规则挖掘
数据结构如下:
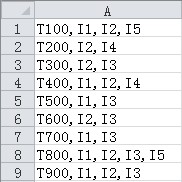
(共9个itemsets,5个items)
首先读入数据:
demodata = read.transactions("C:\\Documents and Settings\\Administrator\\桌面\\DemoData.csv", rm.duplicates= TRUE, format="basket",sep=",",cols =c(1))
查看数据:
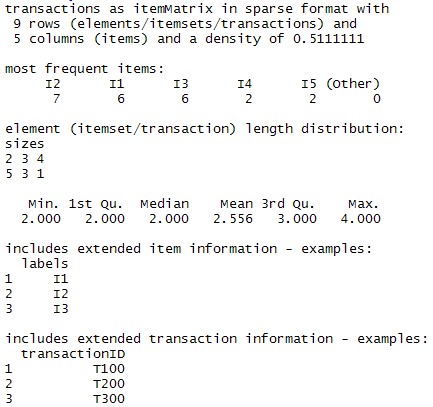
inspect(demodata)

或者:
summary(demodata)
加载arules包
library(arules)
先求频繁项集(建议用eclat)
frequentsets=eclat(demodata,parameter=list(support=0.2,maxlen=4))
(没办法,itemsets太少了,红色框中的warning可以无视)
观察挖掘出来的频繁项集
inspect(frequentsets)

当频繁项集较多时可以根据支持度对挖掘出来的频繁项集排序并察看最前面的几个即可
inspect(sort(frequentsets,by="support")[1:10])

接着就可以挖掘关联规则了(使用apriori,可以适当调整支持度)
rules=apriori(demodata,parameter=list(support=0.2,confidence=0.5))
察看关联规则的主要内容
summary(rules)
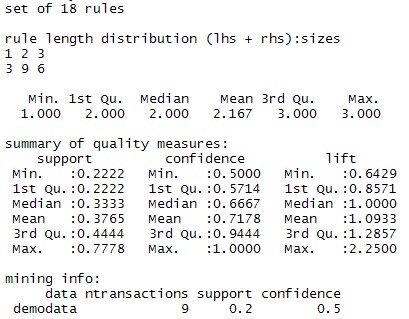
最后求出所需要的关联规则子集(注意:lift > 1 时才表示前项、后项正相关,且越大越好,此处取1.2)
results=subset(rules,subset=lift>=1.2)
inspect(sort(results,by="support"))
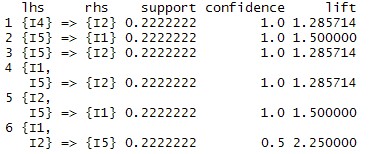
到此,利用R进行关联规则挖掘就暂时告一段落。
二、利用SAS进行关联规则挖掘
(留坑,待填)
利用R与SAS进行关联规则挖掘的更多相关文章
- 数据挖掘算法之-关联规则挖掘(Association Rule)
在数据挖掘的知识模式中,关联规则模式是比较重要的一种.关联规则的概念由Agrawal.Imielinski.Swami 提出,是数据中一种简单但很实用的规则.关联规则模式属于描述型模式,发现关联规则的 ...
- 数据挖掘算法之-关联规则挖掘(Association Rule)(购物篮分析)
在各种数据挖掘算法中,关联规则挖掘算是比較重要的一种,尤其是受购物篮分析的影响,关联规则被应用到非常多实际业务中,本文对关联规则挖掘做一个小的总结. 首先,和聚类算法一样,关联规则挖掘属于无监督学习方 ...
- 数据挖掘系列(1)关联规则挖掘基本概念与Aprior算法
整理数据挖掘的基本概念和算法,包括关联规则挖掘.分类.聚类的常用算法,敬请期待.今天讲的是关联规则挖掘的最基本的知识. 关联规则挖掘在电商.零售.大气物理.生物医学已经有了广泛的应用,本篇文章将介绍一 ...
- 大数据挖掘: FPGrowth初识--进行商品关联规则挖掘
@(hadoop)[Spark, MLlib, 数据挖掘, 关联规则, 算法] [TOC] 〇.简介 经典的关联规则挖掘算法包括Apriori算法和FP-growth算法.Apriori算法多次扫描交 ...
- 数据挖掘系列(4)使用weka做关联规则挖掘
前面几篇介绍了关联规则的一些基本概念和两个基本算法,但实际在商业应用中,写算法反而比较少,理解数据,把握数据,利用工具才是重要的,前面的基础篇是对算法的理解,这篇将介绍开源利用数据挖掘工具weka进行 ...
- apriori && fpgrowth:频繁模式与关联规则挖掘
已迁移到我新博客,阅读体验更佳apriori && fpgrowth:频繁模式与关联规则挖掘 详细代码我放在github上:click me 一.实验说明 1.1 任务描述 1.2 数 ...
- 关联规则挖掘算法之Apriori算法
Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集. 关于这个算法有一个非常有名的故事:"尿布和啤酒".故事是 ...
- SAS笔记(8) 利用数组重构SAS数据集
在实际应用中,我们经常会把宽数据(一个患者一条观测)转化为长数据(一个患者多条观测)或者将长数据(一个患者多条观测)转换为宽数据(一个患者一条观测),在R中我们可以利用Reshape2包来实现.在SA ...
- 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法
转自:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法 我计划 ...
随机推荐
- SharePoint Framework解决方案管理参考(二)
博客地址:http://blog.csdn.net/FoxDave 使用外部脚本 在使用现有的JavaScript脚本库时,开发者可以选择将它们包含在web部件代码包中,或者从外部的URL加载.从外部 ...
- 目标检测(二) SPPNet
引言 先简单回顾一下R-CNN的问题,每张图片,通过 Selective Search 选择2000个建议框,通过变形,利用CNN提取特征,这是非常耗时的,而且,形变必然导致信息失真,最终影响模型的性 ...
- 分布式session个人理解浅谈
在分布式中,用户的session如何处理呢? 服务器中的原生session是无法满足需求的,因为用户的请求有可能随机落入到不同的服务器中,这样的结果将会导致用户的session丢失,传统做法中有解决方 ...
- python3读取MySQL-Front的MYSQL密码
python3读取MySQL-Front的MYSQL密码 python3 mysql 密码 MySQL-Front 前言 同样的套路又来了,继续尝试从配置文件中读取敏感的信息,这次轮到的是MySQL- ...
- zookeeper分布式服务中选主的应用
通常zookeeper在分布式服务中作为注册中心,实际上它还可以办到很多事.比如分布式队列.分布式锁 由于公司服务中有很多定时任务,而这些定时任务由于一些历史原因暂时不能改造成框架调用 于是想到用zo ...
- Linux中挂载详解以及mount命令用法
转自:https://blog.csdn.net/daydayup654/article/details/78788310 挂载概念 Linux中的根目录以外的文件要想被访问,需要将其“关联”到根目录 ...
- Minimum Spanning Trees
Kruskal’s algorithm always union the lightest link if two sets haven't been linked typedef struct { ...
- 【SHELL】:定时任务删除指定目录
现有一个需求,需要定时删除积累过久的目录,并且部分目录不可删除.在此,我们分析了一下该父目录的命名结构:非连续性数字命名,部分目录中包含a.txt文件.如下图所示: 在此,我们对此可作如下操作,获取该 ...
- 开发H5页面遇到的问题以及解决
1.第一个问题就是规范问题,现在边注释边编程以及语义化命名的问题已经基本的改善,页面的层级结构设计也条理了许多,现在的问题就是我对于页面的更深的应用还不够,比如我知道文档流自上而下从左至右,写在下面的 ...
- 在JSP中使用el函数标签获取默认值(男女性别选项)
http://blog.csdn.net/b10060224/article/details/45771025