keras神经网络做简单的回归问题
咸鱼了半个多月了,要干点正经事了。
最近在帮老师用神经网络做多变量非线性的回归问题,没有什么心得,但是也要写个博文当个日记。
该回归问题是四个输入,一个输出。自己并不清楚这几个变量有什么关系,因为是跟遥感相关的,就瞎做呗。
- 数据预处理的选择
刚开始选取了最大最小值的预处理方法,调了很久的模型但是最后模型的输出基本不变。
换了z-score的预处理方法,模型的输出才趋于正常。
- 损失函数的选择
对于回归问题,常用的损失函数有三种,一个是平方误差函数,一个是绝对值误差函数,还有一个是交叉熵函数。
在其他参数都不变的时候分别采用这三个损失函数:
1.交叉熵
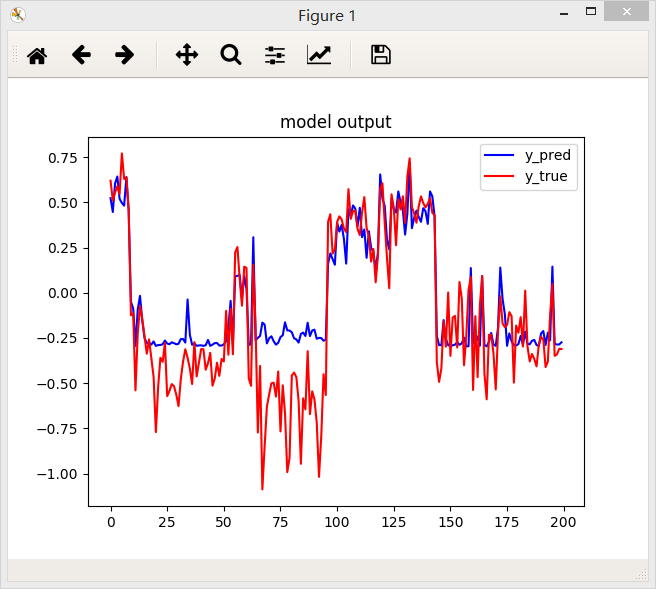
2.绝对值误差函数
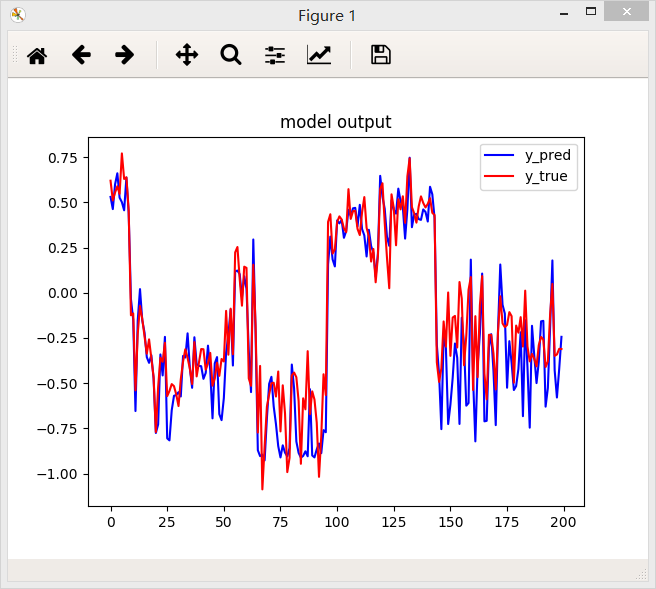
3.平方误差函数

结论:从上面三个图中国可以看出,相同条件下,绝对值误差函数得到的效果好一些。
- batch_size大小的选择
bach_size = 32
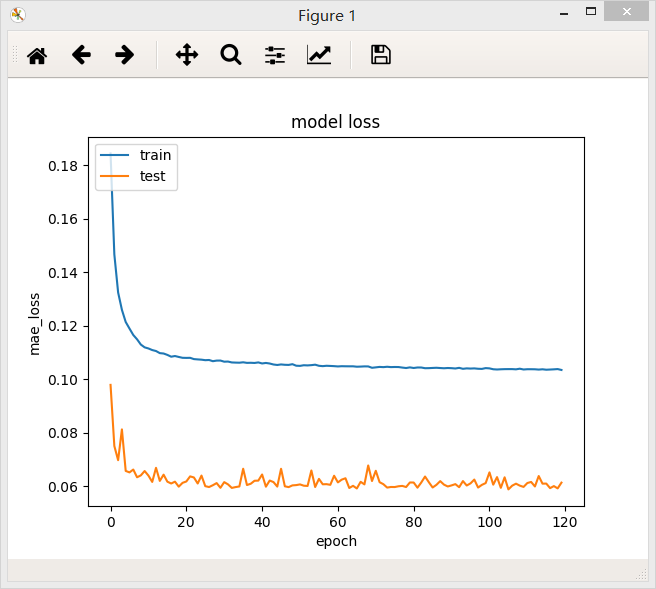
bach_size = 64
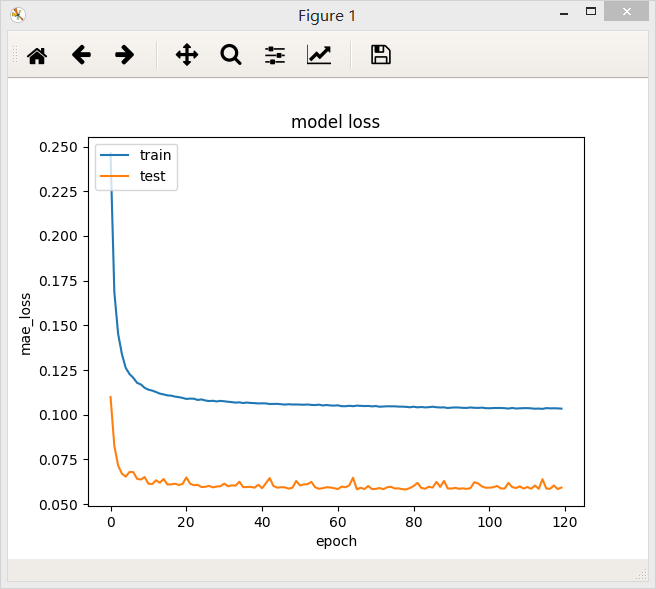
bach_size = 128

batch_size = 256
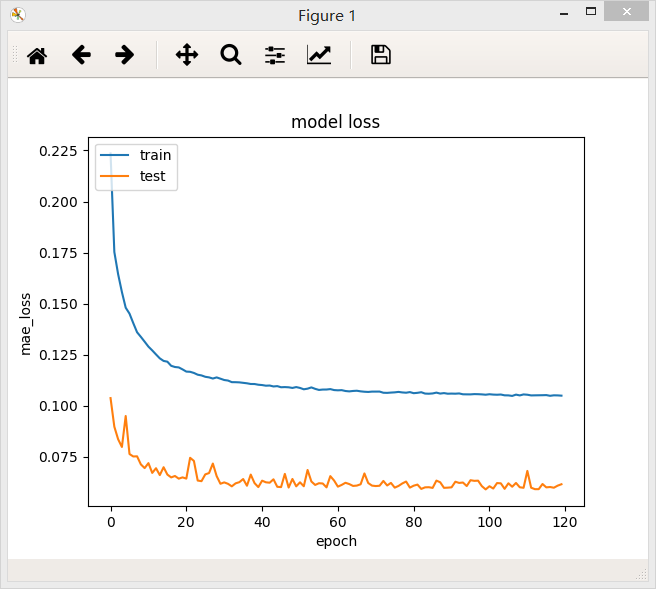
在两个不同的batch_size下,网络最后的loss值都差不多,但是在验证集上,当batch_size = 64/128时,loss曲线比较稳定。
结论:一定范围内,batch_size越大,其确定的下降方向就越准,引起训练震荡越小.随着batch_size增大,处理相同的数据量的速度越快。但是随着batchsize增大,达到相同精度所需要的epoch数量越来越多。过大的batch_size的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch_size会使得训练速度很慢,训练不容易收敛。
- 是否添Dropout层
不加dropout层
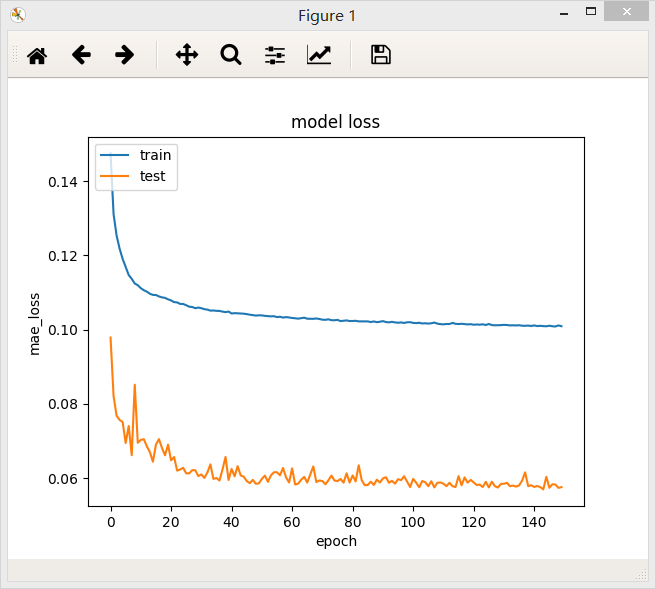
加了Dropout层

加了Dropout层后模型的loss值反而升高,但是测试集上的loss下降能平稳一些。
- 深层网络和浅层网络的选择
我自己觉得这样一个简单的问题其实浅层网络就能解决,但是老师想搭一下深度学习的车,没办法只能用比较一下两个模型。
含有一个隐层的全连接网络,64个神经元,最后模型的loss值为:0.1032
含有两个隐层的全连接网络,第一层32个神经元,第二层16个神经元,最后的loss值为0.0995
含有三个隐层的全连接网络,第一层32个神经元,第二层16个神经元,第三层8个神经元,最后模型的loss值为0.0986
含有四个隐层的全连接网络,第一层32个神经元,第二层16个神经元,第三层8个神经元,第四层4个神经元,最后模型的loss值为0.0993
含有五个隐层的全连接网络,第一层32个神经元,第二层16个神经元,第三层8个神经元,第四层4个神经元,第五层2个神经元,最后模型的loss值为0.0991
含有五个隐层的全连接网络,第一层32个神经元,第二层16个神经元,第三层8个神经元,第四层4个神经元,第五层2个神经元,第六层2个神经元,最后模型的loss值为0.0988
........
结论:在一定范围内,随着网络层的加深,模型的准确率升高。超过一定范围,随着网络层的加深,模型的准确率不但不升反而下降,测试集上的准确率也会下降,所以这并不是出现了过拟合。
- 模型宽度的选择
由于上一个实验中三层模型的loss值最低,所以我选择三层模型来做这个对于模型宽度选择的实验。
1、含有三个隐层的全连接网络,第一层32个神经元,第二层16个神经元,第三层8个神经元,最后模型的loss值为0.0986
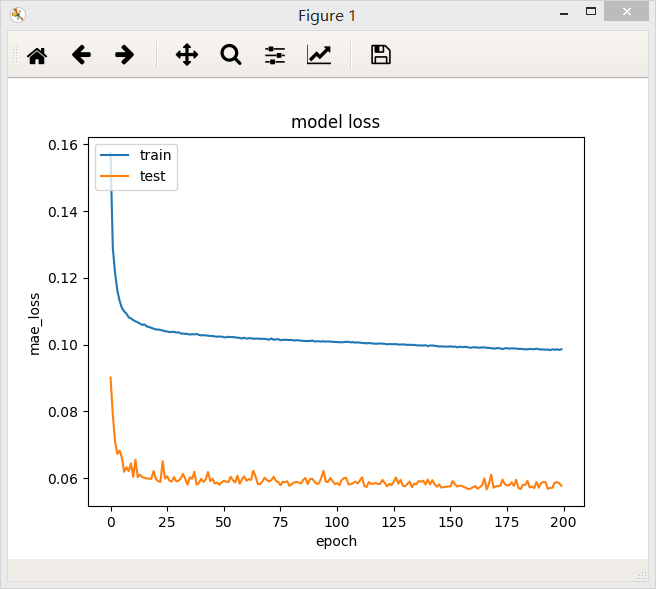
2、含有三个隐层的全连接网络,第一层32个神经元,第二层32个神经元,第三层16个神经元,最后模型的loss值为0.0986
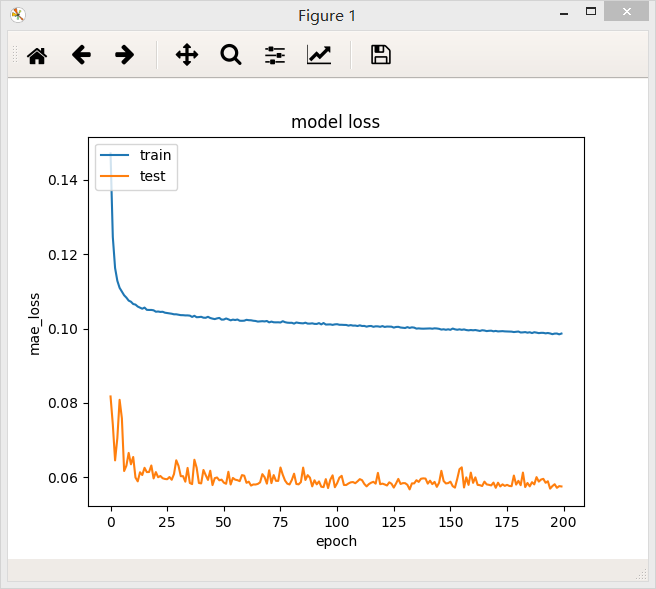
3、含有三个隐层的全连接网络,第一层32个神经元,第二层32个神经元,第三层32个神经元,最后模型的loss值为0.0960
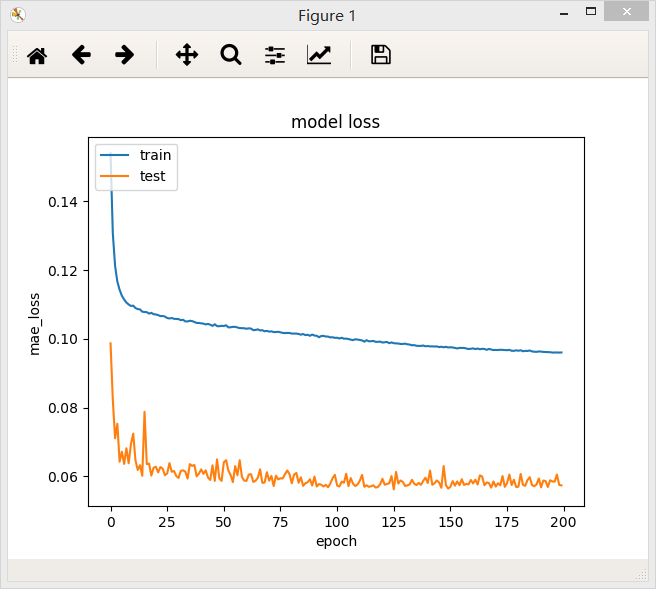
4、含有三个隐层的全连接网络,第一层32个神经元,第二层64个神经元,第三层32个神经元,最后模型的loss值为0.0967
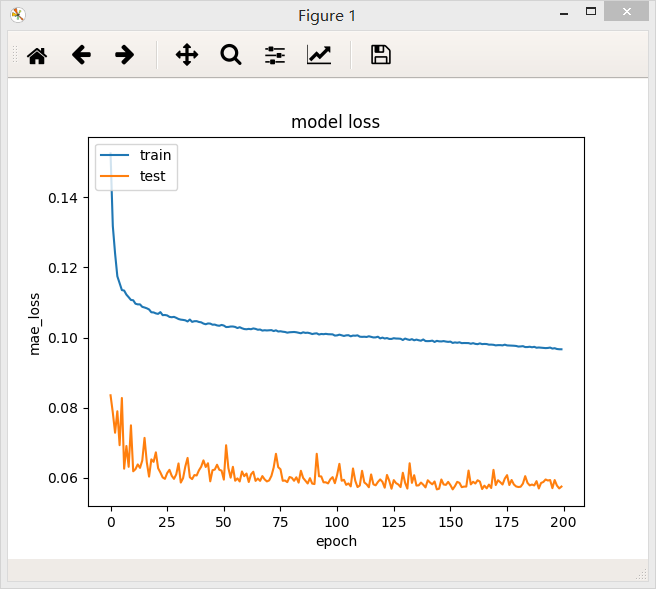
5、含有三个隐层的全连接网络,第一层32个神经元,第二层64个神经元,第三层64个神经元,最后模型的loss值为0.0967

结论:在一定范围内,网络模型越宽,模型的准确率越高,但是超过某一阈值后,模型的准确率不再提高,测试集上loss下降震荡越来越明显,说明模型的复杂度已经高于回归问题真是模型的复杂度。
- 尝试残差网络
第一种残差网络:
def identity_block(x):
out = Dense(32)(x)
#out = BatchNormalization()(out)
out = Activation('tanh')(out)
#out = Dropout(0.1)(out)
out = Dense(32)(x)
#out = Dropout(0.1)(out)
#out = BatchNormalization()(out)
out = Activation('tanh')(out) out = Dense(4)(out)
#out = BatchNormalization()(out) out = merge([out,x],mode='sum')
out = Activation('tanh')(out)
return out

结论:和全连接网络相比,残差网络loss下降很快,测试集上loss下降曲线很平滑,但是模型的准确率却不如普通三层的全连接网络,最终的loss值为0.1021。
第二种残差网络:
def fc_block(x):
out = Dense(32)(x)
out = Activation('tanh')(out)
out = Dense(32)(x)
out = Dropout(0.1)(out)
out = Activation('tanh')(out)
out = Dense(32)(out) x = Dense(32)(x) out = merge([out, x], mode = 'sum')
out = Activation('tanh')(out)
return out
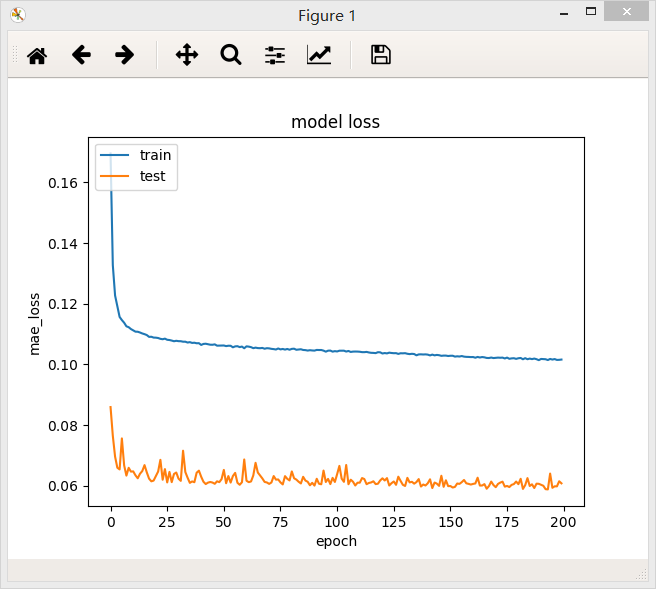
结论:第二种残差网络的loss值为0.1016,比第一种残差网络的效果能好一点。在ResNet中,这两个模块是交替使用的。
将两个模块叠加之后,模型的准确率并没有提升,应该是模型过度复杂了,最后模型的loss值为0.1027。
- relu还是tanh
由于输出值的范围是[-1, 1],因此模型的输出层的激活函数只能选择tanh。
在隐藏层中,可以选择relu和tanh作为隐藏层的激活函数。
模型结构为3层,神经元分别是32,32,32。就是上一个步骤中loss最低的网络结构,在上一个步骤中隐层的激活层使用的是tanh,loss值为0.0960
将tanh换成relu:

采用relu作为激活函数,模型的计算速度会加快,因为求导很简单。在这个问题只使用relu会使模型的准确率下降。一般在复杂的模型中使用relu比较多。
keras神经网络做简单的回归问题的更多相关文章
- [转]Theano下用CNN(卷积神经网络)做车牌中文字符OCR
Theano下用CNN(卷积神经网络)做车牌中文字符OCR 原文地址:http://m.blog.csdn.net/article/details?id=50989742 之前时间一直在看 Micha ...
- 基于BP神经网络的简单字符识别算法自小结(C语言版)
本文均属自己阅读源代码的点滴总结.转账请注明出处谢谢. 欢迎和大家交流.qq:1037701636 email:gzzaigcn2009@163.com 写在前面的闲话: 自我感觉自己应该不是一个非常 ...
- [转] Siamese network 孪生神经网络--一个简单神奇的结构
转自: 作者:fighting41love 链接:https://www.jianshu.com/p/92d7f6eaacf5 1.名字的由来 Siamese和Chinese有点像.Siam是古时候泰 ...
- 利用php的序列化和反序列化来做简单的数据本地存储
利用php的序列化和反序列化来做简单的数据本地存储 如下程序可以做为一个工具类 /** * 利用php的序列化和反序列化来做简单的数据本地存储 */ class objectdb { private ...
- 阿里云api调用做简单的cmdb
阿里云api调用做简单的cmdb 1 步骤 事实上就是调用阿里api.获取可用区,比方cn-hangzhou啊等等.然后在每一个区调用api 取ecs的状态信息,最好写到一个excel里面去.方便排序 ...
- Keras 实现一个简单GAN
Keras 实现一个简单GAN 代码中需提供: Loss Function 参见Keras 或者 Tensorflow 文档 model_param_matrix 反向调整的模型参数/参数矩阵 ...
- Java用户输入数值,做简单的猜数字游戏,导入基础的工具包util
Java用户输入数值,做简单的猜数字游戏,导入基础的工具包util,导入包的方法为,import java.util.*: 完整的实例代码: /* 导入基础工具包 */ import java.uti ...
- 使用jmeter做简单的场景设计
使用jmeter做简单的场景设计 Jmeter: Apache JMeter是Apache组织开发的基于Java的压力测试工具.用于对软件做压力测试.我之所以选择它,最重要的一点就是----开源 个人 ...
- Mycat 做简单的读写分离(转载)
大漠小狼的个人空间 http://www.51testing.com/html/34/369434-3686088.html 使用Mycat 做简单的读写分离(一) 原本使用的是amoeba做的读 ...
随机推荐
- 执行python解释器的两种方式
执行python解释器的两种方式 1.交互式 python是高级语言,是解释型语言,逐行翻译,写一句翻译一句 print ('hello world') 2.命令行式 python和python解释器 ...
- 《linux 必读》
1. linux 内核设计与实现 2. 深入理解 linux 内核
- Navicat Premium 简体中文版 12.0.16 以上版本国外官网下载地址(非国内)
国内Navicat网址是:http://www.navicat.com.cn 国外Navicat网址是:http://www.navicat.com 国外的更新比国内的快,而且同一个版本,国内和国外下 ...
- docker enable overlay2 quota on Centos 7
参考文档 docker overlay2的 --storage-opt 需要启动mount 参数中有pquota 参考上边的文档mount中的xfs 含有pquota 将 /etc/fstab 文件中 ...
- python画手绘图
第一步:插入代码 #e17.1HandDrawPic.py from PIL import Image import numpy as np vec_el = np.pi/2.2 # 光源的俯视角度, ...
- 为KindEditor 添加“一键去除空格功能”
环境说明:KindEditor 4.1.11 一.确定你在使用KindEditor时,引用的是kindEditor-all.js,找到任何一个已经存在的功能,例如,清除HTML代码,我在做的时候本来 ...
- java枚举类型详解
枚举类型是JDK1.5的新特性.显然,enum很像特殊的class,实际上enum声明定义的类型就是一个类.而这些类都是类库中Enum类的子类(java.lang.Enum<E>).它 ...
- 无序hashset与hashmap让其有序
今天迭代hashmap时,hashmap并不能按照put的顺序,迭代输出值.用下述方法可以: HashMap<String,String> hashmap = new LinkedHash ...
- kali linux安装教程及VMware Tool工具的安装
一.Kali Linux在VMware下的安装 kali系统的简介 1.Kali Kali Linux是基于 Debian 的 Linux发行版,设计用于数字取证和渗透测试的操作系统.由Offensi ...
- mysql5.7.21下载及安装步骤
以前都是用的5.6的数据库,现在想着换个新版本数据库.跟上时代的步伐,于是安装了一天才安装好.具体步骤如下: 1.官网下载mysql解压zip版,由于客户端安装版都是32位的,我的电脑是64位系统,所 ...