PCA算法数学原理及实现
数学原理参考:https://blog.csdn.net/aiaiai010101/article/details/72744713
实现过程参考:https://www.cnblogs.com/eczhou/p/5435425.html
两篇博文都写的透彻明白。
自己用python实现了一下,有几点疑问,主要是因为对基变换和坐标变换理解不深。
先附上代码和实验结果:
code:
from numpy import *
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat cx = mat([[2.5, 2.4],
[0.5, 0.7],
[2.2, 2.9],
[1.9, 2.2],
[3.1, 3.0],
[2.3, 2.7],
[, 1.6],
[, 1.1],
[1.5, 1.6],
[1.1, 0.9]])
# print(cx.shape)
sz = cx.shape
m = sz[]
n = sz[] # 显示原数据
def plot_oridata( cx ):
plt.figure(num='原数据图', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , 0.5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(cx[:, ].tolist(), cx[:, ].tolist(), c='r', marker='+')
plt.plot([, ], [-, ], 'k-')
plt.plot([-, ], [, ], 'k-')
plt.show()
return #求协方差矩阵
def get_covMat( cx ):
print('+++++++++++++ 求协方差矩阵 +++++++++++++++')
# 零均值化
ecol = np.mean(cx, axis=)
cx1 = (cx[:, ]) - ecol[, ]
cx2 = cx[:, ] - ecol[, ]
Mcx = np.column_stack((cx1, cx2))
Covx = np.transpose(Mcx)*Mcx/(m-)
# print(Covx)
return Covx, Mcx #计算特征值和特征向量
def get_eign(Covx, k):
eVals, eVecs = np.linalg.eig(Covx)
# print(eVals)
# print(eVecs, ' ', eVecs.shape)
sorted_indices = np.argsort(eVals)
topk_evecs = eVecs[:, sorted_indices[:-k-:-]]
# print(topk_evecs) plt.figure(num='特征向量', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , )
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(cx[:, ].tolist(), cx[:, ].tolist(), c='r', marker='+')
plt.plot([, ], [-, ], 'k-.')
plt.plot([-, ], [, ], 'k-.')
# print(eVecs[, ], eVecs[, ])
# print(eVecs)
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
plt.show()
return eVecs, topk_evecs #转换数据
def transform_data(eVecs, Mcx):
print("------------------转换数据---------------------")
tran_data = Mcx * eVecs
plt.figure(num='转换数据', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , 0.5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(tran_data[:, ].tolist(), tran_data[:, ].tolist(), c='r', marker='+')#哪一维对应x,哪一维对应y
plt.plot([, ], [-, ], 'k-.')
plt.plot([-, ], [, ], 'k-.')
# print(eVecs[, ], eVecs[, ])
# print(eVecs)
plt.show()
return #压缩数据
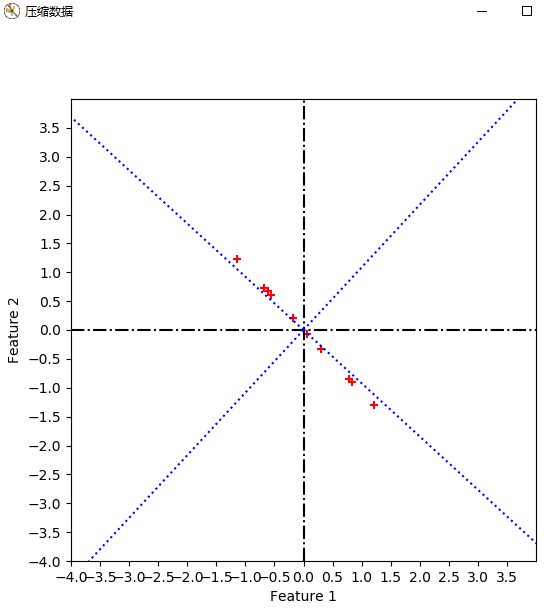
def compress_data(Mcx, topkevecs, eVecs):
print("------------------压缩数据---------------------")
comdata = Mcx * topkevecs
c1 = np.zeros((, ), dtype=int)
comdata1 = np.column_stack((c1, comdata))
comdata2 = comdata1 * eVecs plt.figure(num='压缩数据', figsize=(, ))
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.xlim((-, ))
plt.ylim((-, ))
new_ticks = np.arange(-, , 0.5)
plt.xticks(new_ticks)
plt.yticks(new_ticks)
plt.scatter(comdata2[:, ].tolist(), comdata2[:, ].tolist(), c='r', marker='+') # 哪一维对应x,哪一维对应y
plt.plot([, ], [-, ], 'k-.')
plt.plot([-, ], [, ], 'k-.')
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * ], [, eVecs[, ] * ], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
plt.plot([, eVecs[, ] * -], [, eVecs[, ] * -], 'b:')
# print(eVecs[, ], eVecs[, ])
# print(eVecs)
plt.show()
return plot_oridata(cx)
Covx, Mcx = get_covMat(cx)
eVecs, topk_evecs = get_eign(Covx, )
transform_data(eVecs, Mcx)
compress_data(Mcx, topk_evecs, eVecs)
print('end')
初学python,代码肯定很啰嗦,并且很丑。
实验结果:
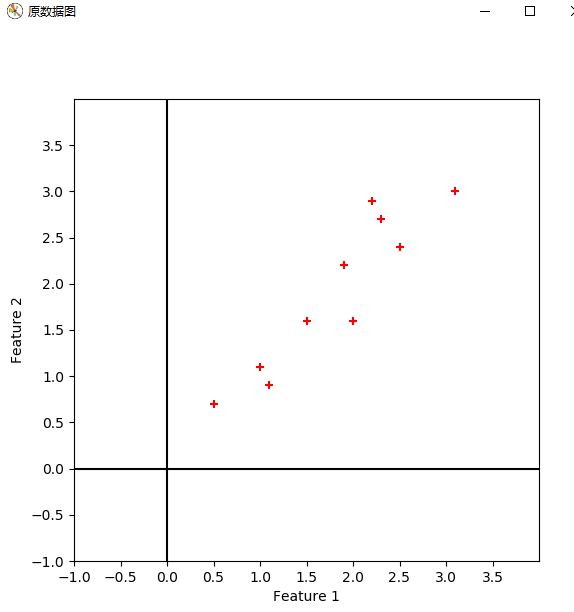
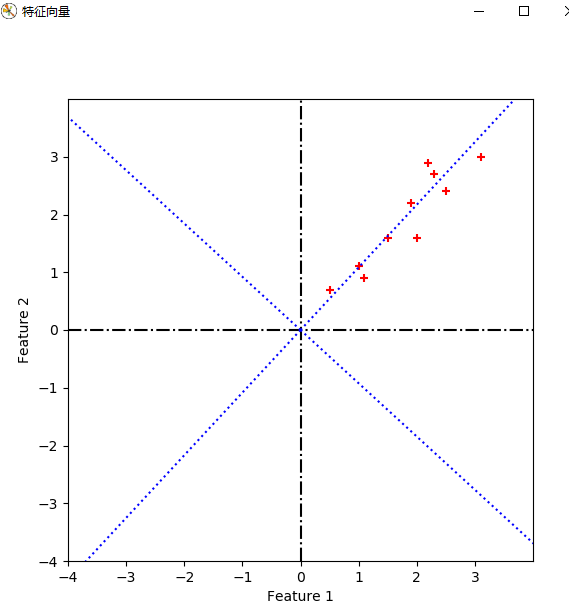
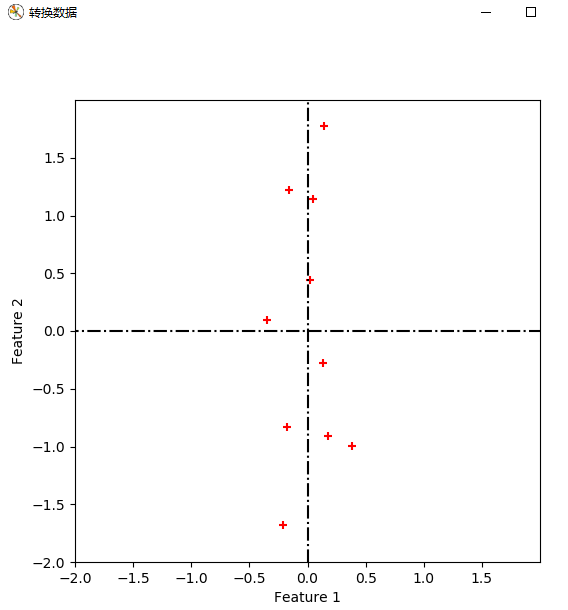
疑问1:对数据进行特征向量为基的转换时,公式如下。我得到的坐标是以原坐标系为参考的,那么哪一维对应x,哪一维对应y,如果我将特征向量按照特征值降序的顺序重新排列,是否有影响呢?
得到的坐标是新坐标系下的。根据转换向量对应。

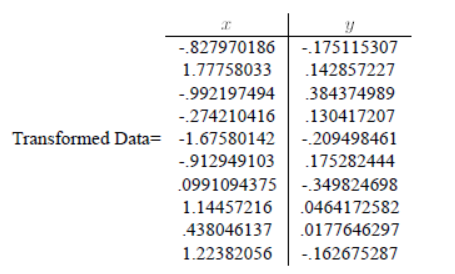
疑问2:取最大特征值对应的特征向量为基时,对数据进行降维,此时我得到的一维坐标是以这个特征向量为参考的吗?此时我应该如何在原坐标系show出这些数据?
我的代码中,取第一维为0,第二维为得到的坐标,以此再进行以此疑问1中的二维基转换,得到坐标,并且plot。不太理解道理。
对一维坐标,分别对两个坐标轴投影即可得到新坐标系下的两个坐标。
PCA算法数学原理及实现的更多相关文章
- PCA的数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维 数据的 ...
- 【机器学习笔记之七】PCA 的数学原理和可视化效果
PCA 的数学原理和可视化效果 本文结构: 什么是 PCA 数学原理 可视化效果 1. 什么是 PCA PCA (principal component analysis, 主成分分析) 是机器学习中 ...
- PCA的数学原理(转)
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- 非对称加密技术- RSA算法数学原理分析
非对称加密技术,在现在网络中,有非常广泛应用.加密技术更是数字货币的基础. 所谓非对称,就是指该算法需要一对密钥,使用其中一个(公钥)加密,则需要用另一个(私钥)才能解密. 但是对于其原理大部分同学应 ...
- PCA的数学原理Matlab演示
关于 PCA(Principal component analysis)主成分分析.是SVD(Singular value decomposition)神秘值分析的一种特殊情况.主要用于数据降维.特征 ...
- PCA数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- pca数学原理(转)
PCA的数学原理 前言 数据的向量表示及降维问题 向量的表示及基变换 内积与投影 基 基变换的矩阵表示 协方差矩阵及优化目标 方差 协方差 协方差矩阵 协方差矩阵对角化 算法及实例 PCA算法 实例 ...
- python实现PCA算法原理
PCA主成分分析法的数据主成分分析过程及python原理实现 1.对于主成分分析法,在求得第一主成分之后,如果需要求取下一个主成分,则需要将原来数据把第一主成分去掉以后再求取新的数据X’的第一主成分, ...
随机推荐
- ss命令详解
ss是Socket Statistics的缩写.顾名思义,ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容.ss的优势在于它能够显示更多更详细的有关TCP和连接状态的信息 ...
- package.json的配置理解
一.初步理解 1. npm安装package.json时 直接转到当前项目目录下用命令npm install 或npm install --save-dev安装即可,自动将package.json中 ...
- isolate demo
dependencies dependencies: flutter: sdk: flutter # The following adds the Cupertino Icons font to yo ...
- Android组件系列----Intent详解(转载笔记)
[正文] Intent组件虽然不是四大组件,但却是连接四大组件的桥梁,学习好这个知识,也非常的重要. 一.什么是Intent 1.Intent的概念: Android中提供了Intent机制来协助应用 ...
- Java第一、二次实训作业
1.有1.2.3.4共4个数字,能组成多少个互不相同且无重复数字的三位数?都是多少? 程序分析:可填在百位.十位.个位的数字都是1.2.3.4.组成所有的排列后再去掉不满足条件的排列. 代码 pack ...
- threadpool源码学习
threadpool源码学习 __all__ = [ 'makeRequests', 'NoResultsPending', 'NoWorkersAvailable', 'ThreadPool', ' ...
- Python游戏编程入门2
I/O.数据和字体:Trivia游戏 本章包括如下内容:Python数据类型获取用户输入处理异常Mad Lib游戏操作文本文件操作二进制文件Trivia游戏 其他的不说,我先去自己学习文件类型和字符串 ...
- vue-router使用 看着篇就够了
官网地址:https://router.vuejs.org/zh/ 先来个自我介绍吧,我就是你们口中的路由,我的作用就是告诉你们怎么到达某地,比如你想去一个地方(前提是这个地方是已经存在的)我会查询我 ...
- 【HNOI 2018】转盘
Problem Description 一次小 \(G\) 和小 \(H\) 原本准备去聚餐,但由于太麻烦了于是题面简化如下: 一个转盘上有摆成一圈的 \(n\) 个物品(编号 \(1\) 至 \(n ...
- CSRF、XSS、clickjacking、SQL 的攻击与防御
CSRF攻击 原理: 跨站请求伪造.是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法. 网站通过cookie来实现登录功能.而cookie只要存在浏览器中,那么浏览器在访问含有这 ...