Python中文转拼音代码(支持全拼和首字母缩写)
本文的代码,从https://github.com/cleverdeng/pinyin.py升级得来,针对原文的代码,做了以下升级:
|
1
2
3
4
|
1、可以传入参数firstcode:如果为true,只取汉子的第一个拼音字母;如果为false,则会输出全部拼音;
2、修复:如果为英文字母,则直接输出;
3、修复:如果分隔符为空字符串,仍然能正常输出;
4、升级:可以指定词典的文件路径
|
代码很简单,直接读取了一个词典(字符和英文的映射),然后挨个替换中文中的拼音即可;
Python
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
原版代码:https://github.com/cleverdeng/pinyin.py
新增功能:
1、可以传入参数firstcode:如果为true,只取汉子的第一个拼音字母;如果为false,则会输出全部拼音;
2、修复:如果为英文字母,则直接输出;
3、修复:如果分隔符为空字符串,仍然能正常输出;
4、升级:可以指定词典的文件路径
"""
__version__ = '0.9'
__all__ = ["PinYin"]
import os.path
class PinYin(object):
def __init__(self):
self.word_dict = {}
def load_word(self, dict_file):
self.dict_file = dict_file
if not os.path.exists(self.dict_file):
raise IOError("NotFoundFile")
with file(self.dict_file) as f_obj:
for f_line in f_obj.readlines():
try:
line = f_line.split(' ')
self.word_dict[line[0]] = line[1]
except:
line = f_line.split(' ')
self.word_dict[line[0]] = line[1]
def hanzi2pinyin(self, string="", firstcode=False):
result = []
if not isinstance(string, unicode):
string = string.decode("utf-8")
for char in string:
key = '%X' % ord(char)
value = self.word_dict.get(key, char)
outpinyin = str(value).split()[0][:-1].lower()
if not outpinyin:
outpinyin = char
if firstcode:
result.append(outpinyin[0])
else:
result.append(outpinyin)
return result
def hanzi2pinyin_split(self, string="", split="", firstcode=False):
"""提取中文的拼音
@param string:要提取的中文
@param split:分隔符
@param firstcode: 提取的是全拼还是首字母?如果为true表示提取首字母,默认为False提取全拼
"""
result = self.hanzi2pinyin(string=string, firstcode=firstcode)
return split.join(result)
if __name__ == "__main__":
test = PinYin()
test.load_word('word.data')
string = "Java程序性能优化-让你的Java程序更快更稳定"
print "in: %s" % string
print "out: %s" % str(test.hanzi2pinyin(string=string))
print "out: %s" % test.hanzi2pinyin_split(string=string, split="", firstcode=True)
print "out: %s" % test.hanzi2pinyin_split(string=string, split="", firstcode=False)
|
实例中main函数的代码输出结果

代码使用方法:
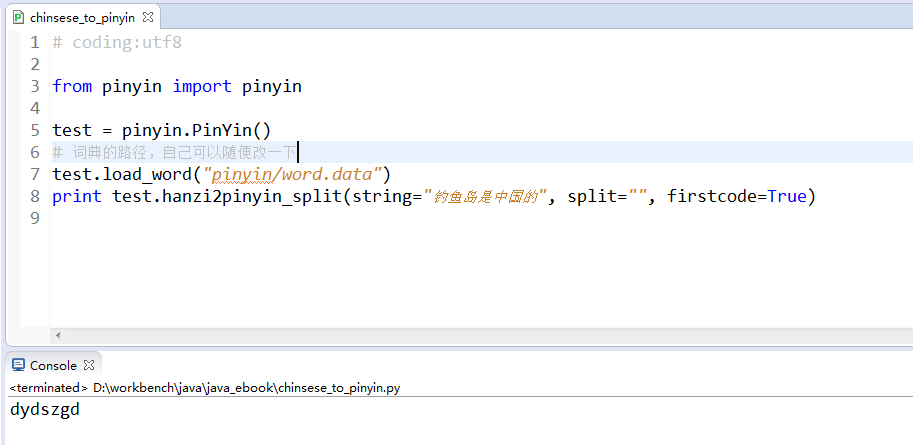
如果需要其他的提取,可以修改一下代码实现;
Python中文转拼音代码(支持全拼和首字母缩写)的更多相关文章
- PHP:汉字转拼音类(全拼与首字母)
[php] <?php class GetPingYing { private $pylist = array( 'a'=>-20319,'ai'=>-20317,'an'=> ...
- select2 全拼以及首字母
转自:https://blog.csdn.net/kanhuadeng/article/details/78475317 具体实现方法为: 首先需要在网上下载select2的源码,并引入到项目中,具体 ...
- js汉语转拼音(全拼、首字母、拼音首字母)
新建js文件first_alphabet.js // JavaScript Document // 汉字拼音首字母列表 本列表包含了20902个汉字,用于配合 ToChineseSpell //函数使 ...
- java 汉语转拼音(全拼,首字母)
import java.util.*; import net.sourceforge.pinyin4j.PinyinHelper;import net.sourceforge.pinyin4j.for ...
- java根据汉字获取全拼和首字母
import net.sourceforge.pinyin4j.PinyinHelper; import net.sourceforge.pinyin4j.format.HanyuPinyinCase ...
- 【Java】使用pinyin4j获取汉字的全拼或首字母
汉字转拼音的工具类,常用于做汉字拼音的模糊查询. https://www.cnblogs.com/htyj/p/7891918.html
- c#中文转全拼或首拼
参考:http://www.jb51.net/article/42217.htmhttp://blog.csdn.net/cstester/article/details/4758172 Chines ...
- NPinyin 中文转换拼音代码
Mono 3.2 测试NPinyin 中文转换拼音代码 C#中文转换为拼音NPinyin代码 在Mono 3.2下运行正常,Spacebuilder 有使用到NPinyin组件,代码兼容性没有问 ...
- Java获取中文拼音、中文首字母缩写和中文首字母
获取中文拼音(如:广东省 -->guangdongsheng) /** * 得到中文全拼 * @param src 需要转化的中文字符串 * @return */ public static S ...
随机推荐
- linux 创建用户和密码
:useradd -m 用户名//添加用户 :passwd 用户名 //然后设置密码 :userdel -r newuser1 //删除用户 newuser1,同时删除其自家目录 samba 设置账号 ...
- bzoj1036点权模板题
/* HYSBZ1036 树上有1-n个结点,每个节点都有一个权值w 操作 CHANGE u t:把结点u的权值改为t QMAX u v:询问从点u到v的路径上的节点的最大权值 QSUM u v:询问 ...
- 深度优先搜索(DFS)和广度优先搜索(BFS)
深度优先搜索(DFS) 广度优先搜索(BFS) 1.介绍 广度优先搜索(BFS)是图的另一种遍历方式,与DFS相对,是以广度优先进行搜索.简言之就是先访问图的顶点,然后广度优先访问其邻接点,然后再依次 ...
- python 线程间通信之Condition, Queue
Event 和 Condition 是threading模块原生提供的模块,原理简单,功能单一,它能发送 True 和 False 的指令,所以只能适用于某些简单的场景中. 而Queue则是比较高级的 ...
- (第1篇)什么是hadoop大数据?我又为什么要写这篇文章?
摘要: hadoop是什么?hadoop是如何发展起来的?怎样才能正确安装hadoop环境? 这些天,有很多人咨询我大数据相关的一些信息,觉得大数据再未来会是一个朝阳行业,希望能尽早学会.入行,借这个 ...
- poj1743
题解: 后缀数组+二分答案 首先会发现这题实质上就是求最长不重复的相同子段 首先二分答案长度,之后对每一段信息进行维护 一段信息即保证这一段的sa值都大于mid即可 然后找到这段中后缀位置最大和最小处 ...
- BZOJ4974 八月月赛 Problem D 字符串大师 KMP
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ4974 - 八月月赛 Problem D 题意概括 一个串T是S的循环节,当且仅当存在正整数k,使得 ...
- L3-020 至多删三个字符 (30 分) 线性dp
给定一个全部由小写英文字母组成的字符串,允许你至多删掉其中 3 个字符,结果可能有多少种不同的字符串? 输入格式: 输入在一行中给出全部由小写英文字母组成的.长度在区间 [4, 1] 内的字符串. 输 ...
- 试安装pyQt5+eric6+python安装
1.先安装pip最新版 安装之前把sit-packages----pip旧版本删掉 然后再cmd输入pip install --user update pip 2.安装pyqt5 pip instal ...
- python tkinter-单选、多选
单选按钮 tkinter.Radiobutton(root,text='a').pack() tkinter.Radiobutton(root,text='b').pack() tkinter.R ...