lucene随笔 IKAnalyzer StandardAnalyzer
StandardAnalyzer 是单词分词器:
String msg = "我喜欢你,我的祖国!china 中国,I love you!中华人民共和国";
分词后的结果:[我],[喜],[欢],[你],[我],[的],[祖],[国],[china],[中],[国],[i],[love],[you],[中],[华],[人],[民],[共],[和],[国]
IKAnalyzer 是中文分词器:
分词后的结果:[我],[喜欢],[你],[我],[的],[祖国],[china],[中国],[i],[love],[you],[中华人民共和国]
package com.shrio.lucene; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.IOException;
import java.io.StringReader; /**
* Created by luojie on 2018/4/24.
*/
public class ChineseAnalyerDemo {
/**standardAnalyer分析器 ,Lucene内置中文分析器*/
public void standardAnalyer(String msg){
StandardAnalyzer analyzer = new StandardAnalyzer(Version.LUCENE_4_10_4);
this.getTokens(analyzer, msg);
} /**IK Analyzer分析器*/
public void iKanalyer(String msg){
IKAnalyzer analyzer = new IKAnalyzer(true);//当为true时,分词器进行最大词长切分
//IKAnalyzer analyzer = new IKAnalyzer();
this.getTokens(analyzer, msg);
} private void getTokens(Analyzer analyzer, String msg) {
try {
TokenStream tokenStream=analyzer.tokenStream("content", new StringReader(msg));
tokenStream.reset();
this.printTokens(analyzer.getClass().getSimpleName(),tokenStream);
tokenStream.end();
} catch (IOException e) {
e.printStackTrace();
} } private void printTokens(String analyzerType,TokenStream tokenStream){
CharTermAttribute ta = tokenStream.addAttribute(CharTermAttribute.class);
StringBuffer result =new StringBuffer();
try {
while(tokenStream.incrementToken()){
if(result.length()>0){
result.append(",");
}
result.append("["+ta.toString()+"]");
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(analyzerType+"->"+result.toString());
}
}
package com.shrio.lucene; import org.junit.Before;
import org.junit.Test; /**
* Created by luojie on 2018/4/24.
*/
public class TestChineseAnalyizer { private ChineseAnalyerDemo demo = null; private String msg = "我喜欢你,我的祖国!china 中国,I love you!中华人民共和国";
//private String msg = "I love you, China!B2C";
@Before
public void setUp() throws Exception {
demo=new ChineseAnalyerDemo();
}
@Test
public void testStandardAnalyer(){
demo.standardAnalyer(msg);
demo.iKanalyer(msg);
}
@Test
public void testIkAnalyzer(){
demo.iKanalyer(msg);
}
}
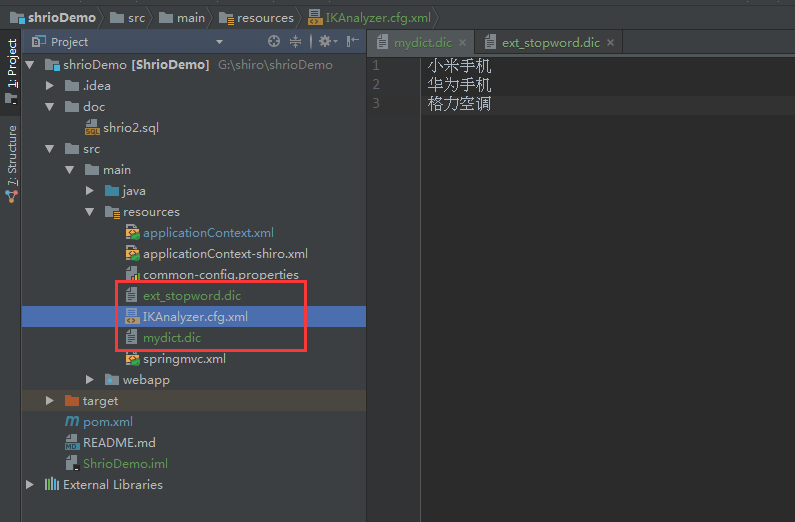
IKAnalyzer 独立使用 配置扩展词典
IKAnalyzer.cfg.xml必须在src根目录下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties> <comment>IK Analyzer 扩展配置</comment>
<!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">mydict.dic</entry>
<!-- 用户可以在这里配置自己的扩展停用词字典 -->
<entry key="ext_stopwords">ext_stopword.dic</entry> </properties>
lucene随笔 IKAnalyzer StandardAnalyzer的更多相关文章
- solr、Lucene、IKAnalyzer这三者关系是怎样的?
lucene 是开源搜索引擎 solr 是基于 lucene开发的搜索引擎 IK 是中文分词. lucene 不是一个搜索引擎,只是一个基础的文件索引工具包,或者叫“搜索引擎开发包”.不能单独作为程序 ...
- Lucene使用IKAnalyzer分词实例 及 IKAnalyzer扩展词库
文章转载自:http://www.cnblogs.com/dennisit/archive/2013/04/07/3005847.html 方案一: 基于配置的词典扩充 项目结构图如下: IK分词器还 ...
- Lucene学习——IKAnalyzer中文分词
一.环境 1.平台:MyEclipse8.5/JDK1.5 2.开源框架:Lucene3.6.1/IKAnalyzer2012 3.目的:测试IKAnalyzer的分词效果 二.开发调试 1.下载框架 ...
- Lucene使用IKAnalyzer分词
1.分析器 所有分析器最终继承的类都是Analyzer 1.1 默认标准分析器:StandardAnalyzer 在我们创建索引的时候,我们使用到了Index ...
- Lucene基于IKAnalyzer配置的词典扩充
在web项目的src目录下创建IKAnalyzer.cfg.xml文件,内容如下 <?xml version="1.0" encoding="UTF-8" ...
- lucene+IKAnalyzer实现中文纯文本检索系统
首先IntelliJ IDEA中搭建Maven项目(web):spring+SpringMVC+Lucene+IKAnalyzer spring+SpringMVC搭建项目可以参考我的博客 整合Luc ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- 通过lucene的StandardAnalyzer分析器来了解分词
本文转载http://blog.csdn.net/jspamd/article/details/8194919 不同的Lucene分析器Analyzer,它对TokenStream进行分词的方法是不同 ...
- Lucene第一讲——概述与入门
一.概述 1.什么是Lucene? Lucene是apache下的一个开源的全文检索引擎工具包. 它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现全文检索的功能. 2.能干什 ...
随机推荐
- 字符串和数组----vector
vector能容纳绝大多数类型的对象作为其元素,但是因为引用不是对象,所以不存在包含引用的vector. 使用vector需要包含头文件vector. 1.初始化vector对象的方法 1)vecto ...
- linux 添加环境变量(php为例)
find / -name php vim /etc/profile 文件最后添加 export PATH=$PATH:/usr/local/php/bin source /etc/profile p ...
- go中for循环使用多个变量避坑
go for循环语法为: for expression1, expression2, expression3 { // ... } 使用多个变量时,使用平行赋值,需要留意的是expression3处的 ...
- Angular4-配置
基于 Angular Quickstart git clone https://github.com/angular/quickstart ng4-quickstart npm i npm start ...
- XML(二)
XML XML介绍 1.什么是xml? 概念:XML(EXtensible Markup Language)XML 指可扩展标记语言(EXtensible Markup Language) 可扩展:我 ...
- DevExpress WinForms v18.2新版亮点(六)
行业领先的.NET界面控件2018年第二次重大更新——DevExpress v18.2日前正式发布,本站将以连载的形式为大家介绍各版本新增内容.本文将介绍了DevExpress WinForms v1 ...
- 关于这次安装Oracle
前后大概经历了一个星期,今天下午(先是用的Navicat)当我尝试性的把用户名上方的复选项从服务名换成SID时,竟然瞬间连接成功了,整个人都是蒙B的,这样就好了? 之后我又用PLsql测试了一下,秒进 ...
- Android开发---基本UI组件1:自动拨电话,自动上网,输入框不换行、只输数字、只输文本、只输密码
1.activity_main.xml 描述:构建一个按钮 <?xml version="1.0" encoding="utf-8"?> <L ...
- Android开发 ---xml布局元素
1.android:orientation="vertical/horizontal" vertical为垂直布局, horizontal为水平布局 2.android:layou ...
- java语言登陆界面(菜鸟版)
最近在看的Java入门书是<Head First Java>,一本很棒的Java书. 老师要求的程序流程图我没有,之前我们的做法是写完代码再画流程图,我想这样的做法是不对的,流程图应该是在 ...