Jmeter(二十)Beanshell or JSR223
有关Beanshell和JSR223组件的部分,早就想写一大篇幅随笔进行记录,苦于不知如何去描述这两部分的内容,一直在修改随笔。
介绍一下Beanshell:
Beanshell是轻量级Java,支持对象式的脚本语言特性,亦可嵌入到JAVA源代码中,能动态执行JAVA源代码并为其扩展了脚本语言的一些特性,像JavaScript和perl那样的弱类型、命令式、闭包函数等等特性都不在话下。(飞升传送门:http://www.beanshell.org/)
Beanshell在Jmeter有着相当强的地位,被称之为Jmeter脚本语言的King。不过前段时间在Blazemeter中看到一篇文章----《IS Beanshell Dead?》,仔细阅读了一番,其大致之意便是自Jmeter3.1以来,JSR223的脚本语言对Groovy的默认化,相对于Beanshell,开发人员更为喜欢Groovy;不过对于我们来说,到底是选择Beanshell还是Groovy?现阶段我觉得没必要讨论这样的话题。不过我认为适当的转变是有必要的,盲目跟风那绝对是大忌!有兴趣的可以去看看,究其根本原因是什么。金庸老爷子是这样描述独孤求败:草木竹石均可为剑。自此精进,渐入无剑胜有剑之境。剑神不是剑法有多高超,而是功力太深厚,草木竹石皆可为剑!Beanshell、Groovy皆可为剑!哈哈,看看Jmeter中的Beanshell和JSR223以及它们所能实现的功能吧!
首先,Beanshell和JSR223组件是涉及代码部分的组件,至于用途,能量所在来进行一一记载:
Beanshell和JSR223几乎在Jmeter的每部分都有涉及到:
1、Sampler
2、PreProcessor
3、PostProcessor
4、Timers
5、Assertions
6、Listeners
那么先添加一个Beanshell Sampler:
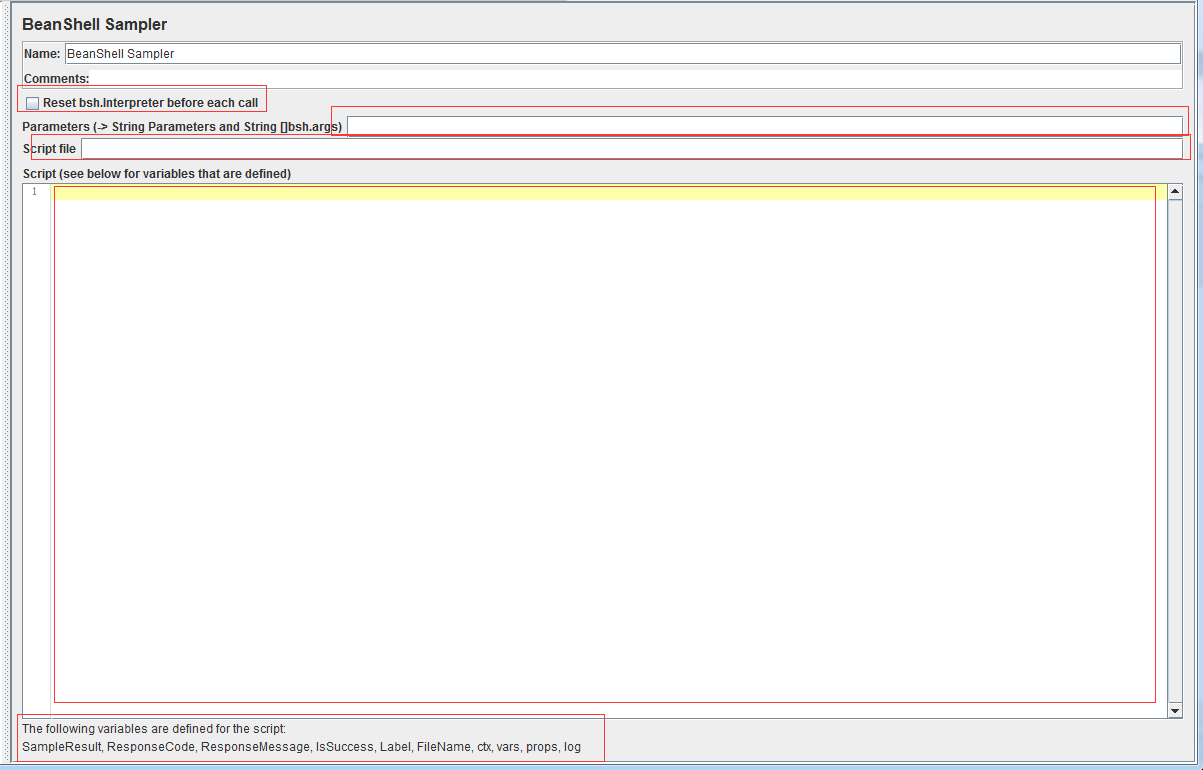
图上标注了五部分内容,几乎除了名称和注释以外的所有部分,都是十分重要的内容。来进行一一解读:
先贴官方文档:

Rest bsh.Interpreter before each call:(check box)不做解释,具体见官方文档中给出的示例(或转Best Practices - Beanshell seripting)
Parameters(String Parameters and String 【】bah.args):传递参数,可将GUI脚本中创建的Parameters参数传递至Beanshell脚本中。在Beanshell脚本中引用是使用bsh.args【x】进行实例化。
Script file:导入Beanshell脚本运行文件。文件名存储在脚本变量名中。
Script:脚本编写处。(Beanshell语法)
而最下方的一段话,我是特意框了起来,很多人可能会忽略,但是这段话中列举的变量便是为Beanshell脚本定义的:
SampleResult, ResponseCode, ResponseMessage, IsSuccess, Label, FileName, ctx, vars, props, log
用过的人肯定都很熟悉这里边的变量,具体用途同名一致!
OK、上个简单的例子(该Demo来自Blazemeter的示例,大家有兴趣可以去看看):
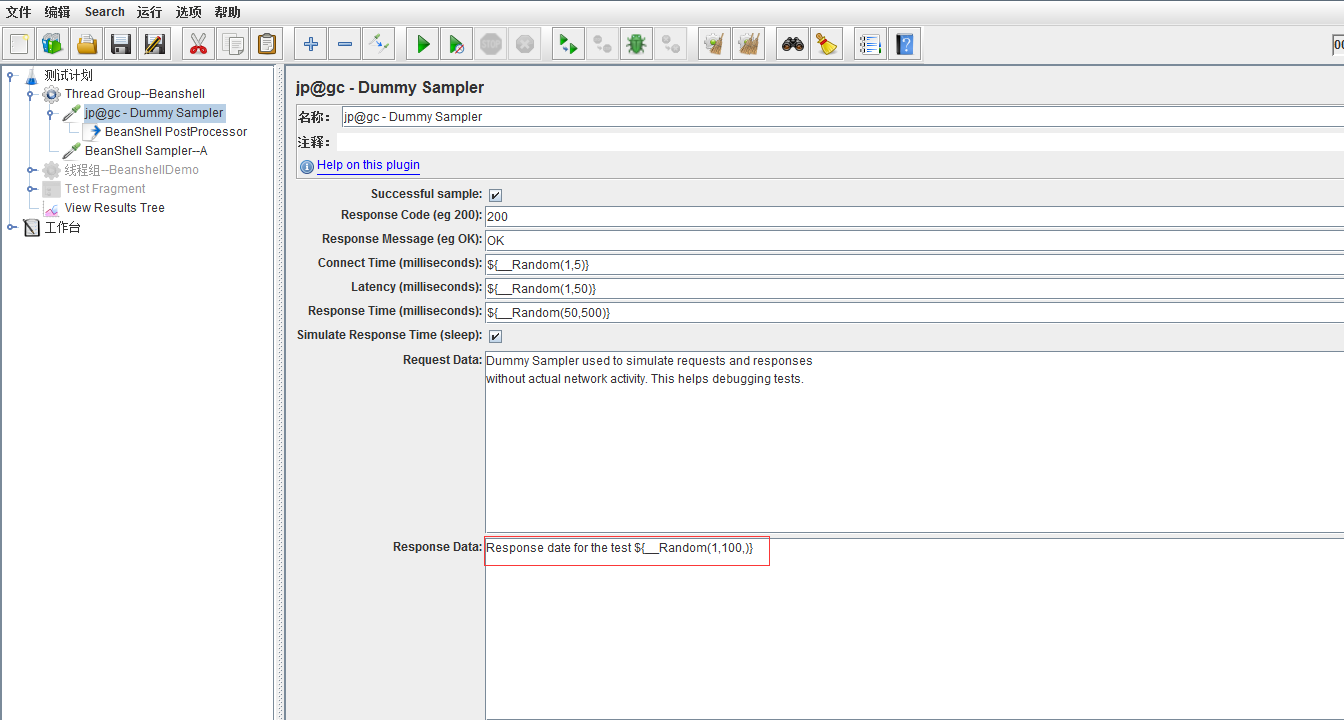
使用随机函数Random作为一个随机响应数据。
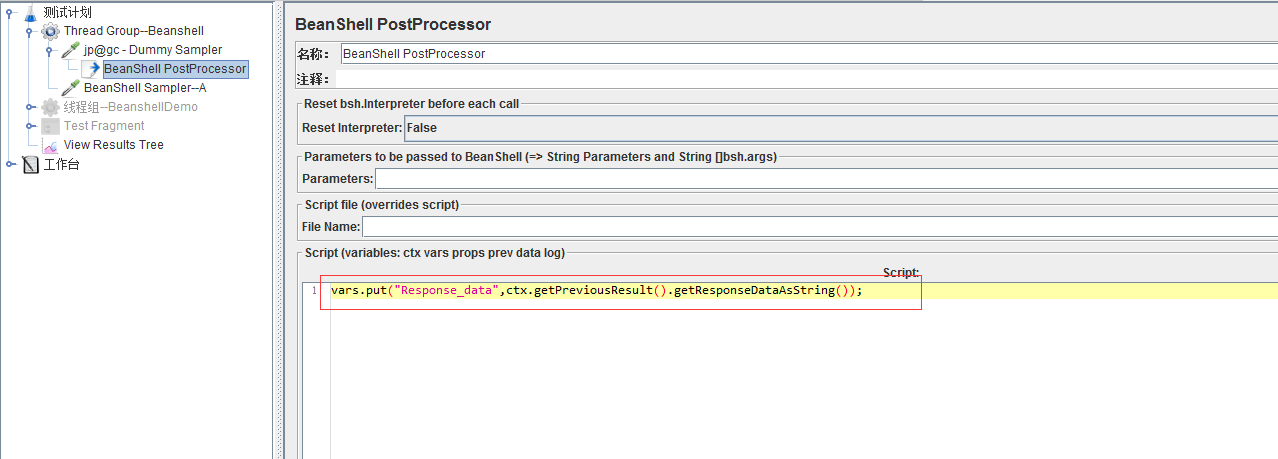
将Dummy Sampler的响应结果以及响应数据保存至“Response_data”变量中。
添加Beanshell Sampler进行使用该变量:
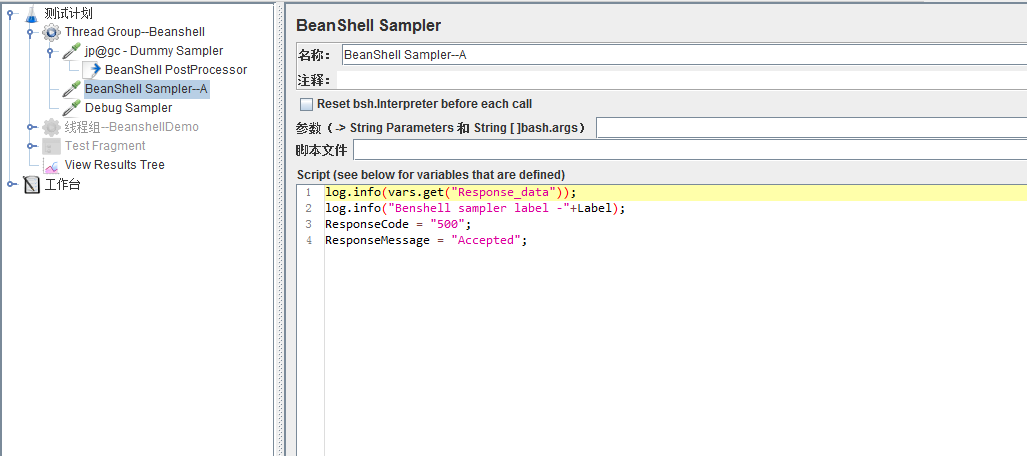
将Response_data的变量信息打印至日志;
将Label打印至日志;
定义该Sampler的响应状态码以及响应信息。
为直观,添加一个Debug Sampler查看变量读取情况:
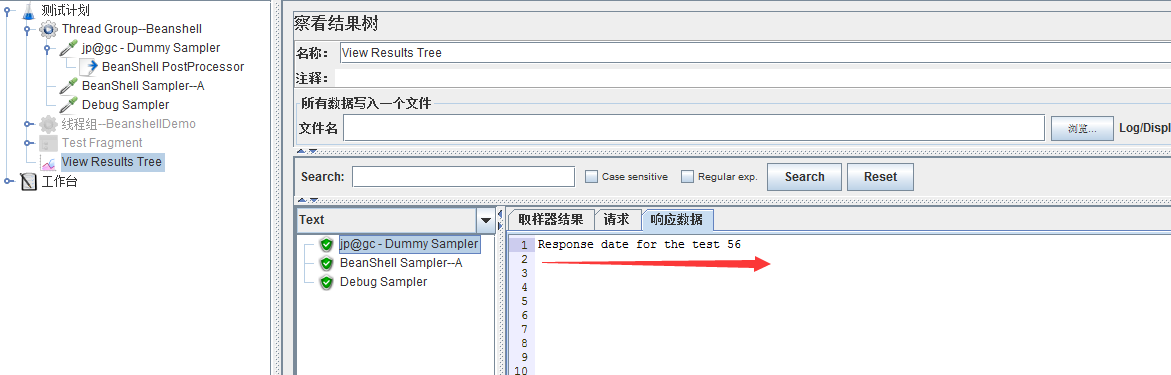
响应的随机数为56

在上方的Beanshell Sampler定义的Response Code和message。
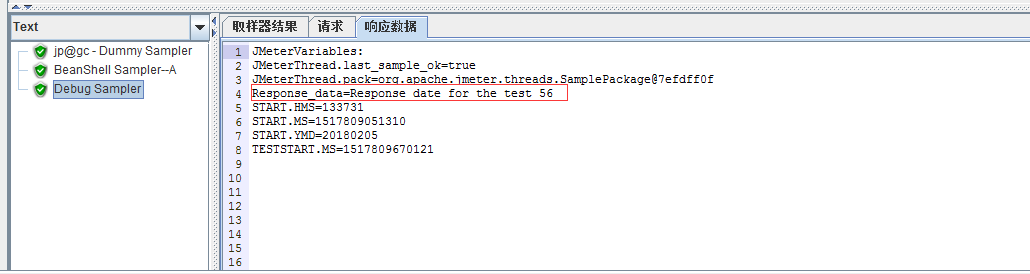
Debug Sampler的变量读取是正确的。
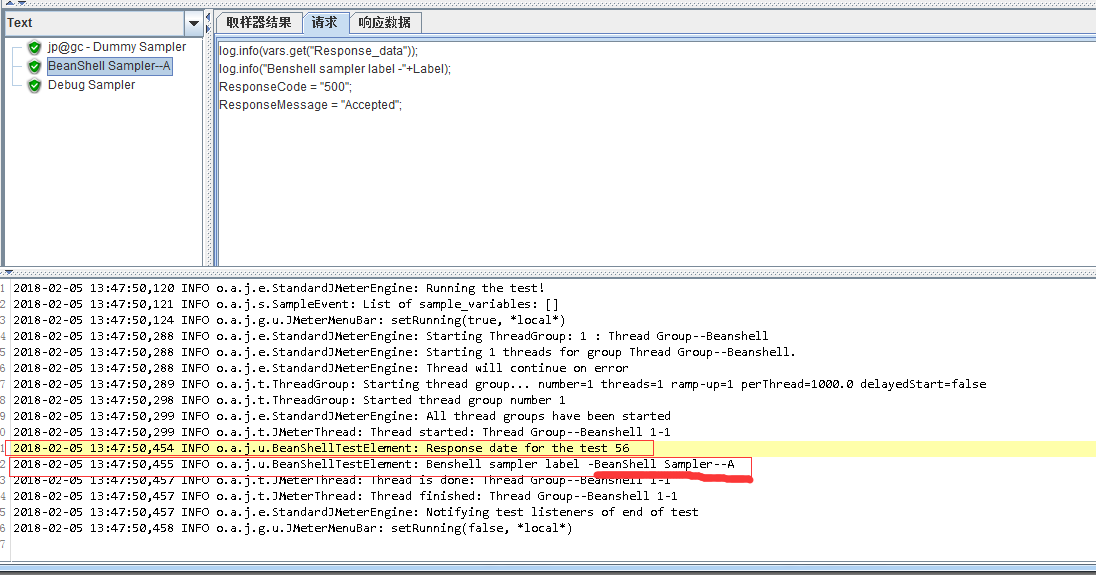
日志面板中打印出的Response data以及Label名称。
当然逻辑判断和引入外部jar包在有必要的情况下依然是支持的。
一个将数据写入文件的小Demo:
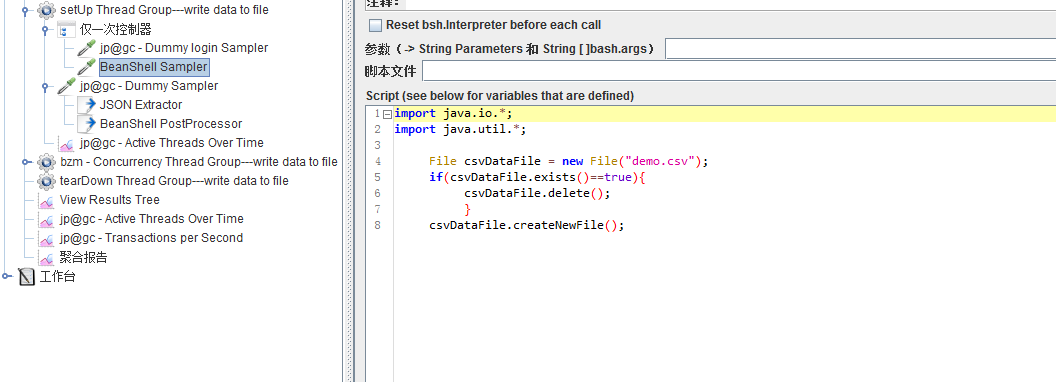
判断目录下有没有该文件(此处默认为/bin目录下),如果存在,将其删除掉,创建新的文件
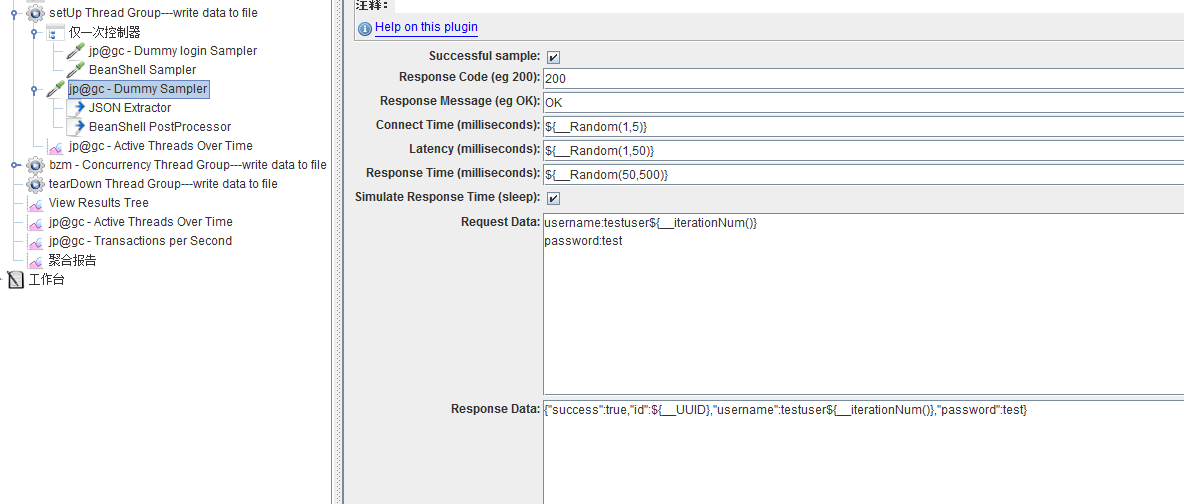
Dummy Sampler自定义写入request和response信息。(涉及函数__UUID、__iterationNum)
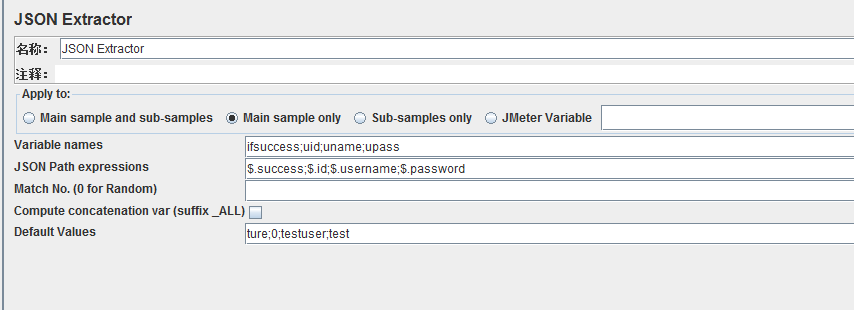
将该响应信息中id、name、password提取出来,定义为新的变量。
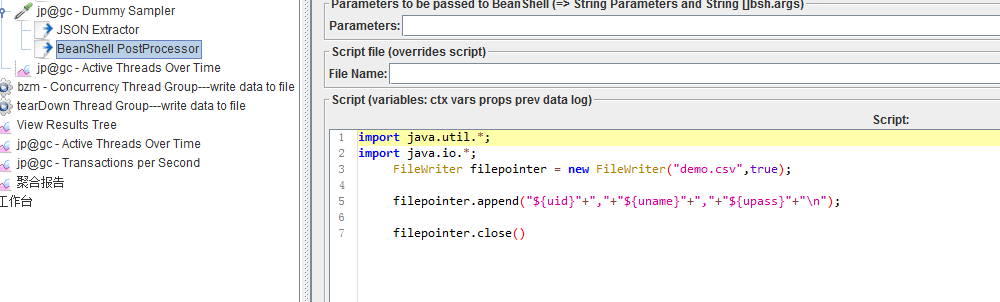
将提取出来的数据写入该文件中。
OK,我已经运行过一遍了,看看写入数据是否成功。
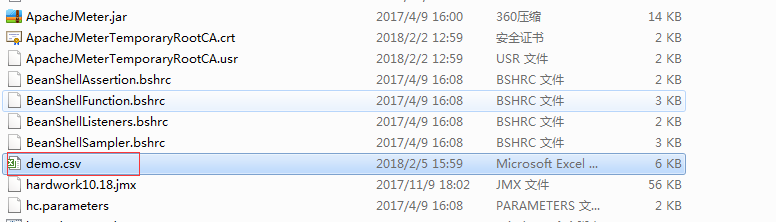
我的/bin目录下是生成了该文件,打开数据是否写入:
可以看到是写入成功了。
Setup Group Thread中做创建文件和数据写入工作。
bzm - Concurrency Thread Group----------该线程组大致就是一个测试setup线程组中的数据过程。
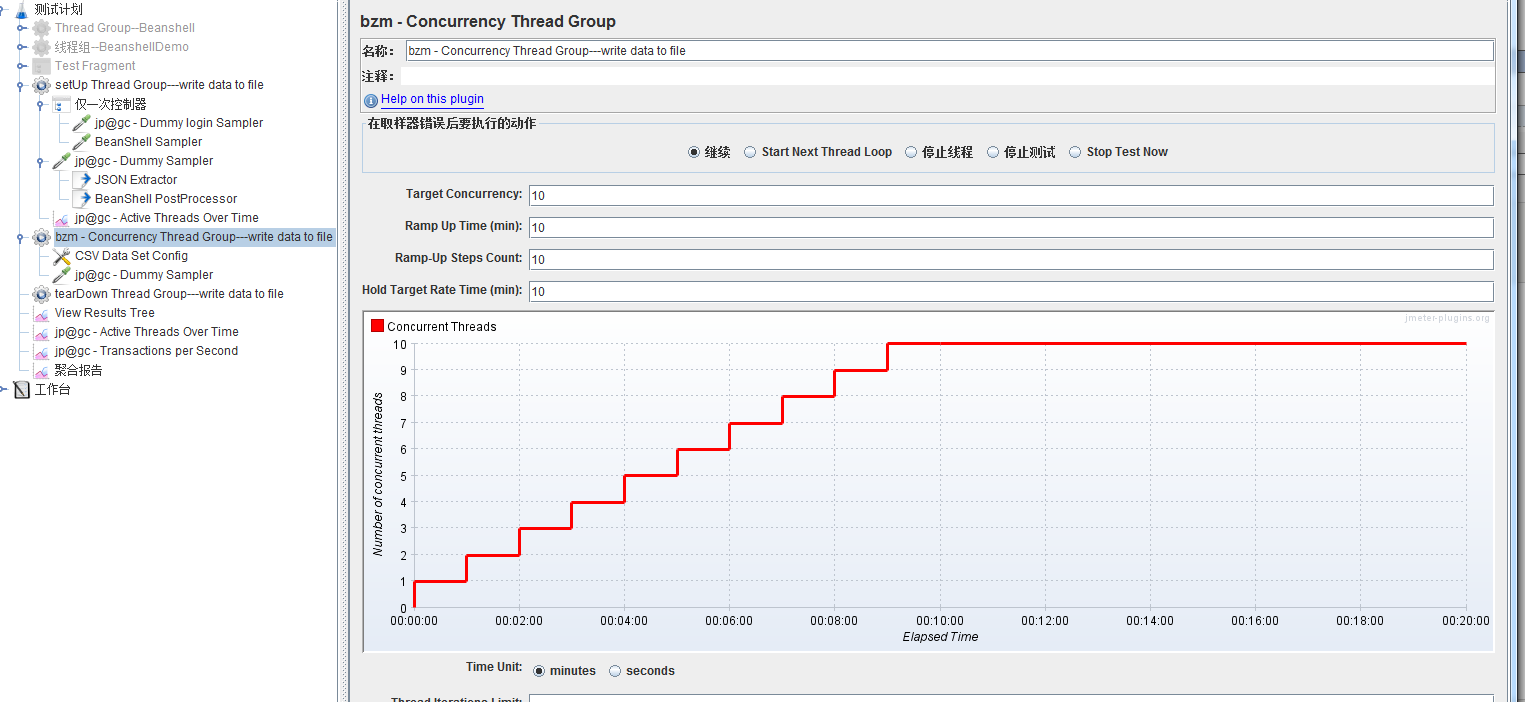
该线程组下进行以参数化的方式读取生成的文件:

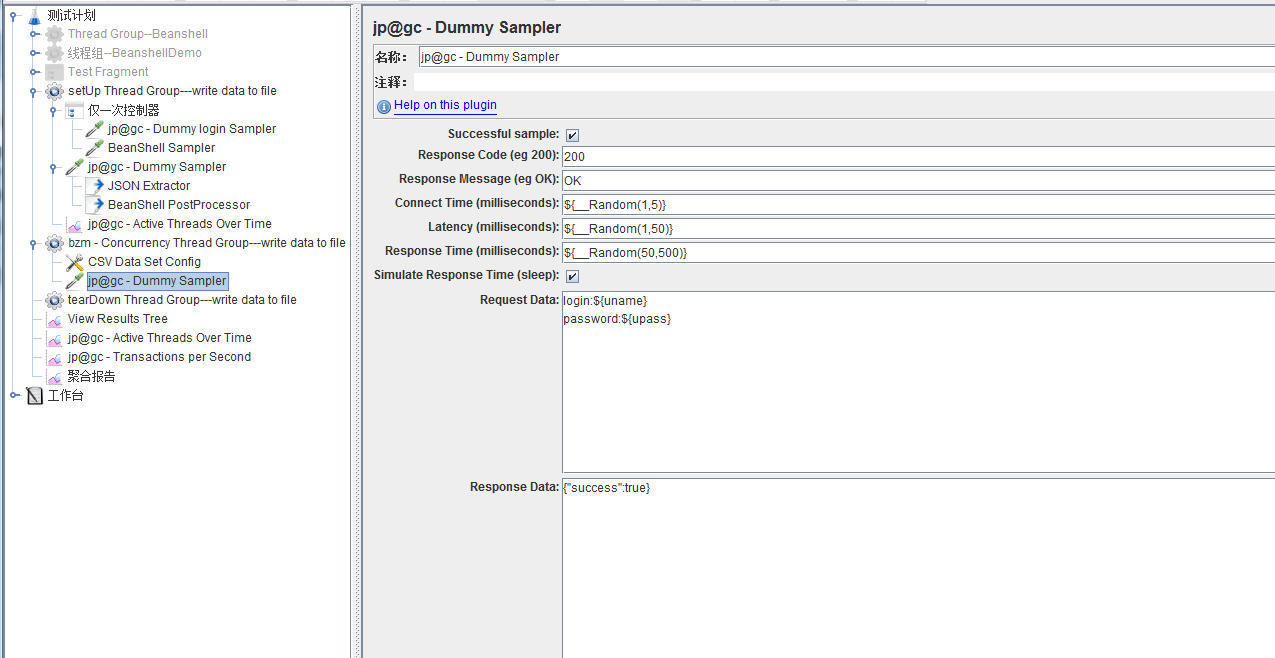
OK,Beanshell几乎用于处理复杂业务逻辑,例如生成随机手机号码、随机身份证号、加密、解密等业务。其灵活之处更在于可以实例化外部java文件。
Jmeter(二十)Beanshell or JSR223的更多相关文章
- Jmeter(二十) - 从入门到精通 - JMeter监听器 -下篇(详解教程)
1.简介 监听器用来监听及显示JMeter取样器测试结果,能够以树.表及图形形式显示测试结果,也可以以文件方式保存测试结果,JMeter测试结果文件格式多样,比如XML格式.CSV格式.默认情况下,测 ...
- Jmeter(二十二) - 从入门到精通 - JMeter断言 - 下篇(详解教程)
1.简介 断言组件用来对服务器的响应数据做验证,常用的断言是响应断言,其支持正则表达式.虽然我们的通过响应断言能够完成绝大多数的结果验证工作,但是JMeter还是为我们提供了适合多个场景的断言元件,辅 ...
- Jmeter(二十四) - 从入门到精通 - JMeter函数 - 中篇(详解教程)
1.简介 在性能测试中为了真实模拟用户请求,往往我们需要让提交的表单内容每次都发生变化,这个过程叫做参数化.JMeter配置元件与前置处理器都能帮助我们进行参数化,但是都有局限性,为了帮助我们能够更好 ...
- Jmeter(二十)_Mock接口
首先解释一下什么是mock接口. Mock通常是指,在测试一个对象时,我们构造一些假的对象来模拟与其交互.而这些Mock对象的行为是我们事先设定且符合预期.通过这些Mock对象来测试对象在正常逻辑,异 ...
- Jmeter(二十四)_服务器性能监控
下载插件 1.访问网址http://jmeter-plugins.org/downloads/all/,下载三个文件.其中JMeterPlugins-Standard和JMeterPlugins-Ex ...
- Jmeter(二十五)_Xpath关联
在Jmeter中,除了正则表达式可以用作关联,还有一种方式也可以做关联,那就是 XPath Extractor.它是利用xpath提取出关键信息,传递变量. 具体用法 添加一个后置处理器-XPath ...
- Jmeter(二十六)_数据驱动测试
花了一点时间做了一个通用的执行引擎,好处就是我不用再关注测试脚本的内容,而是用测试用例的数据去驱动我们执行的方向.(这个只适合单个接口的测试,具体运用到接口自动化时,还是要靠手动去编写脚本!) 首先我 ...
- Jmeter(二十九)_dotnet搭建本地接口服务
这里使用的服务名为Bookshelf,在github上,自行下载.要运行此服务,需要.Net Core SDK 2.1或更高版本.如果尚未安装,从.Net Core官方网站下载并安装. 在本地克隆项目 ...
- Jmeter(二十八)_Docker+Jmeter+Gitlab+Jenkins+Ant(容器化的接口自动化持续集成平台)
这套接口自动化持续集成环境已经部署差不多了,现在说说我的设计思路 1:利用Docker容器化Gitlab,Jenkins,Jmeter,Ant,链接如下 Docker_容器化gitlab Docker ...
- Jmeter(二十二)_脚本上传Gitlab
Docker部署接口自动化持续集成环境第四步,代码上传到远程仓库! 接上文:Ubuntu部署jmeter与ant Gitlab在容器中部署好了之后,本地直接打开.我们可以在里面创建项目,上传脚本. 新 ...
随机推荐
- webpack中hash、chunkhash、contenthash区别
webpack中对于输出文件名可以有三种hash值: 1. hash 2. chunkhash 3. contenthash 这三者有什么区别呢? hash 如果都使用hash的话,因为这是工程级别的 ...
- centos7.3使用花生壳映射端口
首先下载花生壳客户端(其实我觉得更应该叫做服务端),选择相应的版本就可,例如我就是选择的linux->centos版本的 https://hsk.oray.com/download/ 我的版本为 ...
- day6 python学习
---恢复内容开始--- 今日讲课内容: 1. 新内容: 字典 1.字典有无序性,没有顺序,2字典的键:key必须是可哈希的.可哈希表示key必须是不可变类型,如:数字.字符串.元组.不可变的,字 ...
- sqler sql 转rest api 数据聚合操作
sqler 2.0 提供了一个新的指令aggregate,注意这个和sql 的聚合函数不是一个概念,这个只是为了 方便api数据的拼接 参考格式 databases { exec = &qu ...
- jupyter命令把.ipynb文件转化为.py文件
jupyter nbconvert --to script *.ipynb 就能把当前文件夹下面的所有的.ipynb文件转化为.py文件
- sql-索引的作用
(一)深入浅出理解索引结构 何时使用聚集索引/非聚集索引 结合实际,谈索引使用的误区 其他书上没有的索引使用经验总结 其他注意事项 (二)改善SQL语句 (三)实现小数据量和海量数据的通用分页显示存储 ...
- Oracle11g 密码延迟认证导致library cache lock的情况分析
在 Oracle 11g 中,为了提升安全性,Oracle 引入了『密码延迟验证』的新特性.这个特性的作用是,如果用户输入了错误的密码尝试登录,那么随着登录错误次数的增加,每次登录前验证的时间也会增加 ...
- webpack 中,loader、plugin 的区别
loader 和 plugin 的主要区别: loader 用于加载某些资源文件. 因为 webpack 只能理解 JavaScript 和 JSON 文件,对于其他资源例如 css,图片,或者其他的 ...
- httpclient中文乱码
https://blog.csdn.net/teamlet/article/details/8605840
- java 反射创建实例与new创建实例的区别
new创建实例 new创建一个编译时已知的类的实例,也即是静态的创建实例: 可以调用类的任何构造器来创建实例: 速度更快,由于可以将需要的类写入字节文件中(hardcoded into the byt ...