从CPU缓存看缓存的套路
一、前言
不同存储技术的访问时间差异很大,从 计算机层次结构 可知,通常情况下,从高层往底层走,存储设备变得更慢、更便宜同时体积也会更大,CPU 和内存之间的速度存在着巨大的差异,此时就会想到计算机科学界中一句著名的话:计算机科学的任何一个问题,都可以通过增加一个中间层来解决。
二、引入缓存层
为了解决速度不匹配问题,可以通过引入一个缓存中间层来解决问题,但是也会引入一些新的问题。现代计算机系统中,从硬件到操作系统、再到一些应用程序,绝大部分的设计都用到了著名的局部性原理,局部性通常有如下两种不同的形式:
时间局部性:在一个具有良好的时间局部性的程序当中,被引用过一次的内存位置,在将来一个不久的时间内很可能会被再次引用到。
空间局部性:在一个具有良好的空间局部性的程序当中,一个内存位置被引用了一次,那么在不久的时间内很可能会引用附近的位置。
有上面这个局部性原理为理论指导,为了解决二者速度不匹配问题就可以在 CPU 和内存之间加一个缓存层,于是就有了如下的结构:
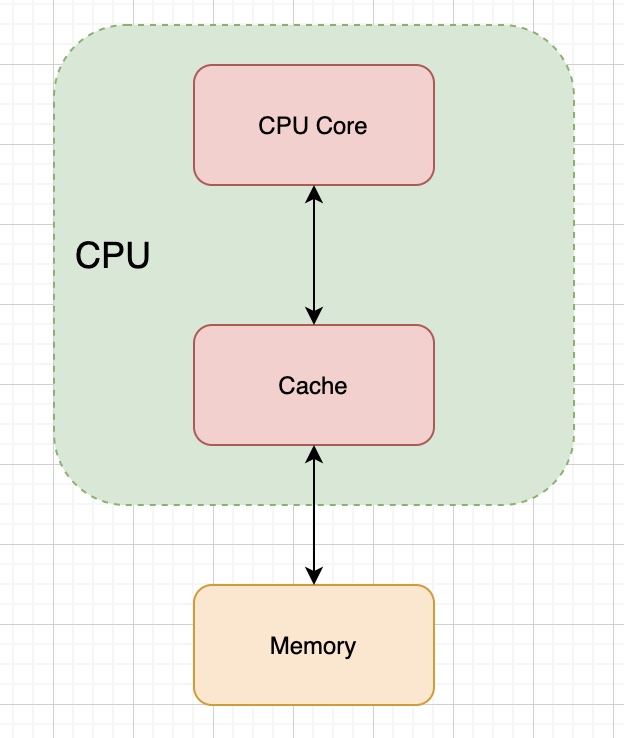
三、何时更新缓存
在 CPU 中引入缓存中间层后,虽然可以解决和内存速度不一致的问题,但是同时也面临着一个问题:当 CPU 更新了其缓存中的数据之后,要什么时候去写入到内存中呢?,比较容易想到的一个解决方案就是,CPU 更新了缓存的数据之后就立即更新到内存中,也就是说当 CPU 更新了缓存的数据之后就会从上到下更新,直到内存为止,英文称之为write through,这种方式的优点是比较简单,但是缺点也很明显,由于每次都需要访问内存,所以速度会比较慢。还有一种方法就是,当 CPU 更新了缓存之后并不马上更新到内存中去,在适当的时候再执行写入内存的操作,因为有很多的缓存只是存储一些中间结果,没必要每次都更新到内存中去,英文称之为write back,这种方式的优点是 CPU 执行更新的效率比较高,缺点就是实现起来会比较复杂。
上面说的在适当的时候写入内存,如果是单核 CPU 的话,可以在缓存要被新进入的数据取代时,才更新内存,但是在多核 CPU 的情况下就比较复杂了,由于 CPU 的运算速度超越了 1 级缓存的数据 I\O 能力,CPU 厂商又引入了多级的缓存结构,比如常见的 L1、L2、L3 三级缓存结构,L1 和 L2 为 CPU 核心独有,L3 为 CPU 共享缓存。
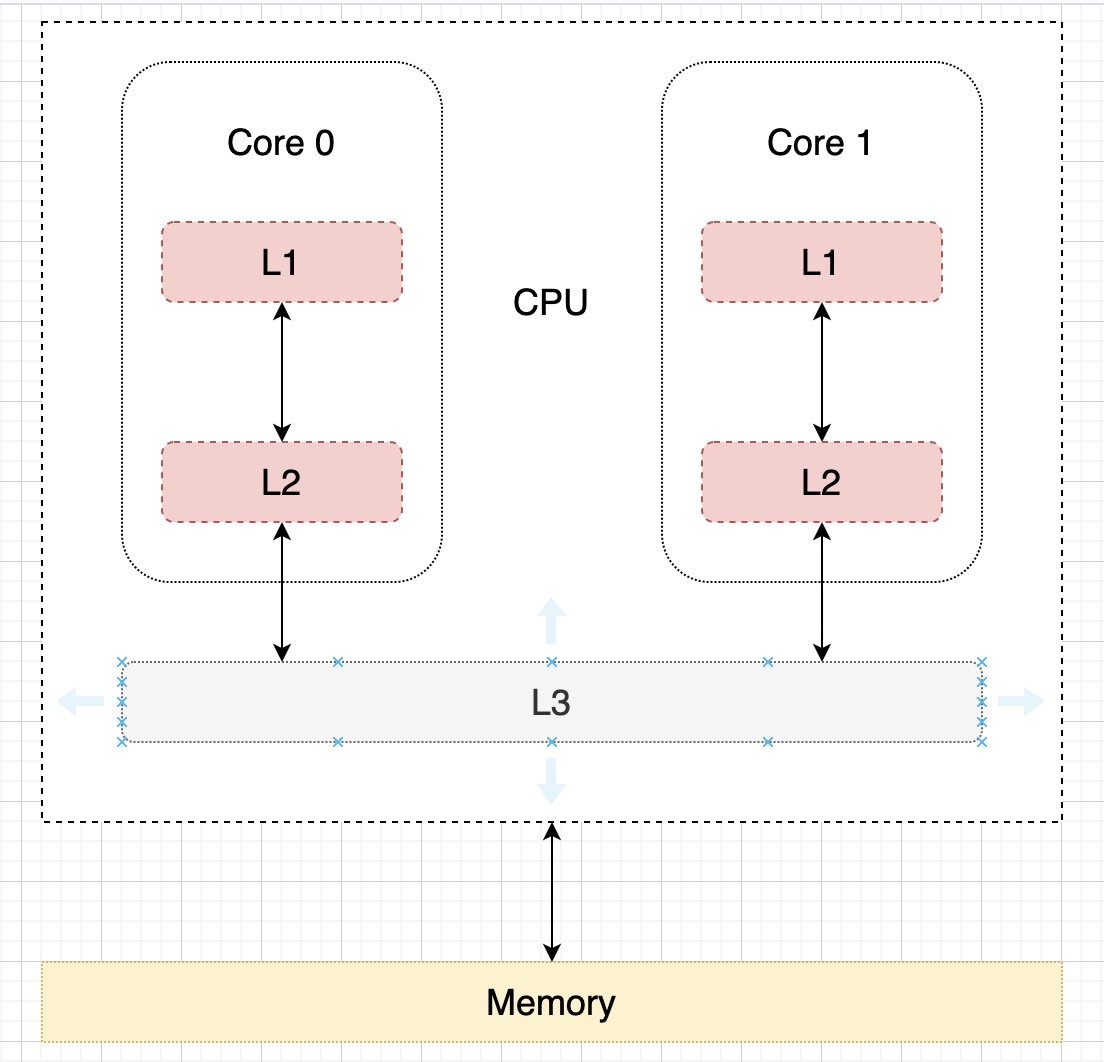
如果现在分别有两个线程运行在两个不同的核 Core 1 和 Core 2 上,内存中 i 的值为 1,这两个分别运行在两个不同核上的线程要对 i 进行加 1 操作,如果不加一些限制,两个核心同时从内存中读取 i 的值,然后进行加 1 操作后再分别写入内存中,可能会出现相互覆盖的情况,解决的方法相信大家都能想得到,第一种是只要有一个核心修改了缓存的数据之后,就立即把内存和其它核心更新。第二种是当一个核心修改了缓存的数据之后,就把其它同样复制了该数据的 CPU 核心失效掉这些数据,等到合适的时机再更新,通常是下一次读取该缓存的时候发现已经无效,才从内存中加载最新的值。
四、缓存一致性协议
不难看出第一种需要频繁访问内存更新数据,执行效率比较低,而第二种会把更新数据推迟到最后一刻才会更新,读取内存,效率高(类似于懒加载)。 缓存一致性协议(MESI) 就是使用第二种方案,该协议主要是保证缓存内部数据的一致,不让系统数据混乱。MESI 是指 4 种状态的首字母。每个缓存存储数据单元(Cache line)有 4 种不同的状态,用 2 个 bit 表示,状态和对应的描述如下:
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该 Cache line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中 | Cache line 必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成 S(共享)状态之前被延迟执行 |
| E 独享、互斥 (Exclusive) | 该 Cache line 有效,数据和内存中的数据一致,数据只存在于本 Cache 中 | Cache line 必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成 S(共享)状态 |
| S 共享 (Shared) | 该 Cache line 有效,数据和内存中的数据一致,数据存在于很多 Cache 中 | Cache line 必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该 Cache line 变成无效 |
| I 无效 (Invalid) | 该 Cache line 无效 | 无监听任务 |
下面看看基于缓存一致性协议是如何进行读取和写入操作的, 假设现在有一个双核的 CPU,为了描述方便,简化一下只看其逻辑结构:
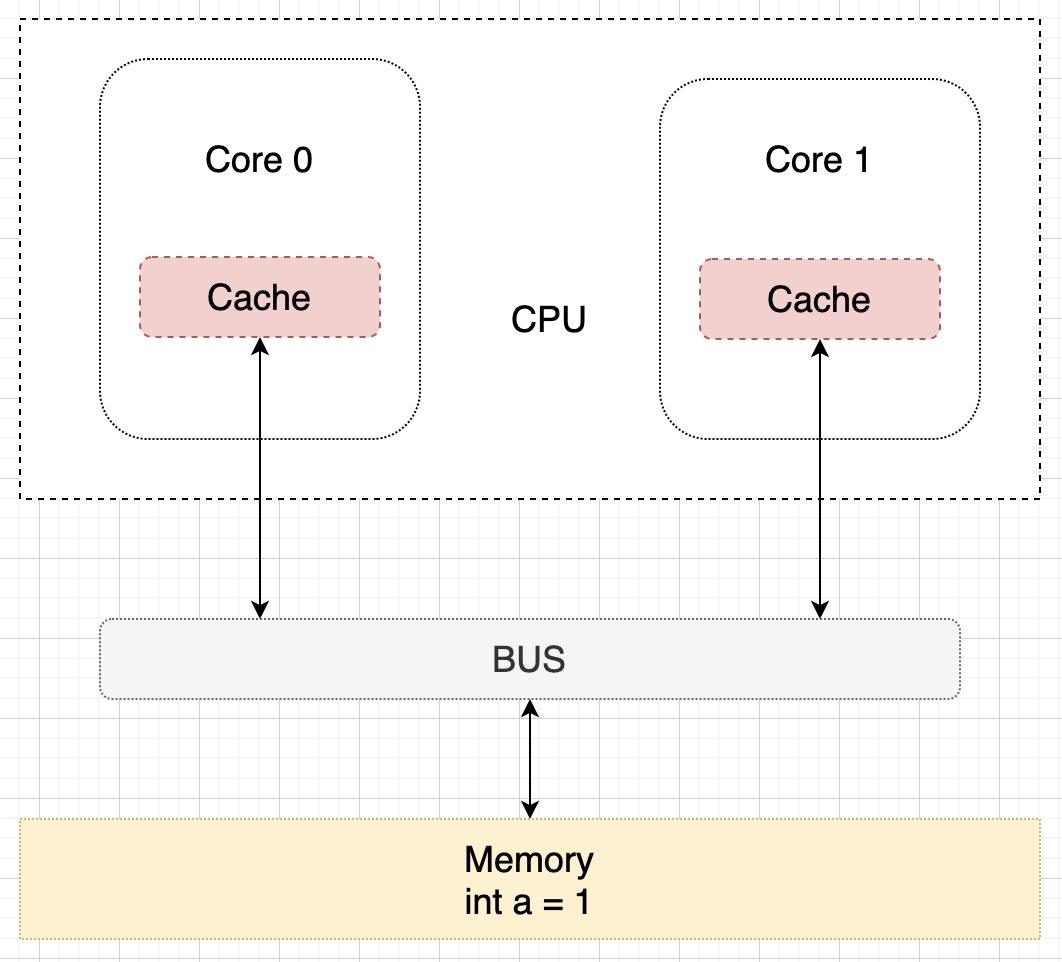
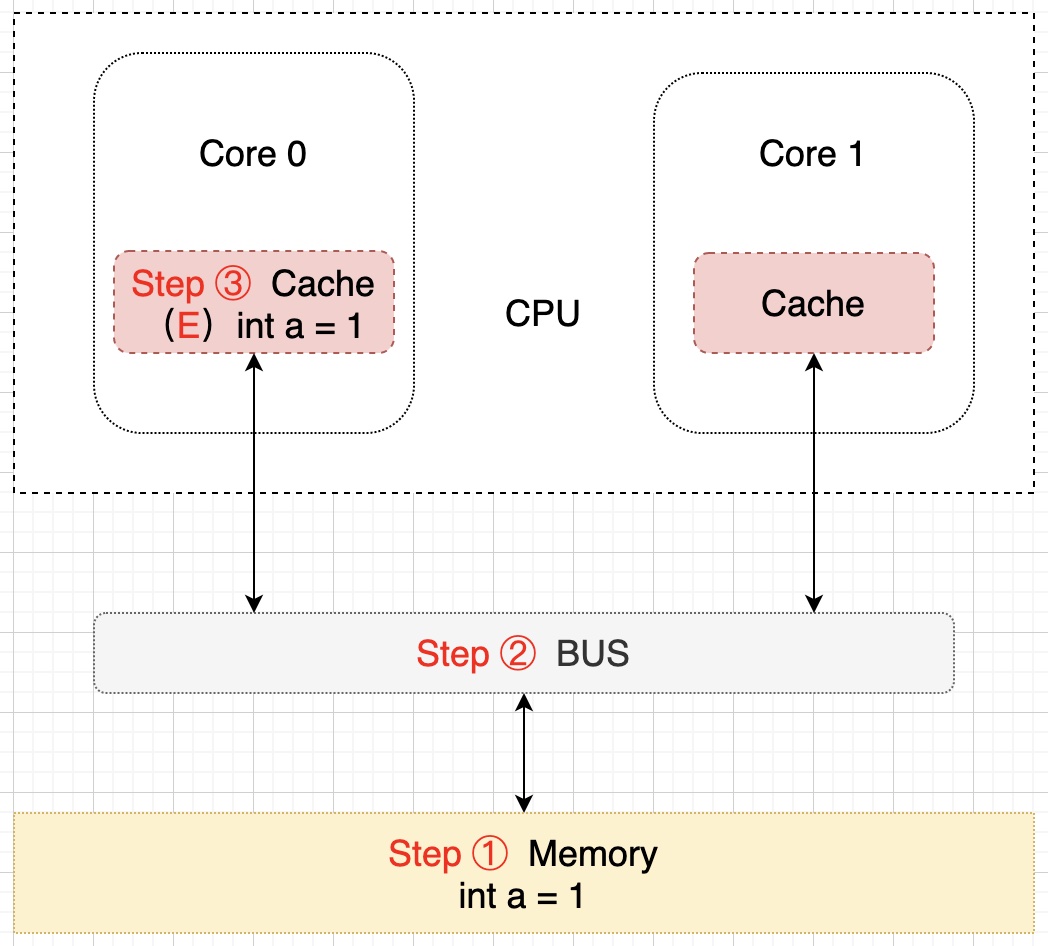
单核读取步骤:Core 0 发出一条从内存中读取 a 的指令,从内存通过 BUS 读取 a 到 Core 0 的缓存中,因为此时数据只在 Core 0 的缓存中,所以将 Cache line 修改为 E 状态(独享),该过程用示意图表示如下:
双核读取步骤:首先 Core 0 发出一条从内存中读取 a 的指令,从内存通过 BUS 读取 a 到 Core 0 的缓存中,然后将 Cache line 置为 E 状态,此时 Core 1 发出一条指令,也是要从内存中读取 a,当 Core 1 试图从内存读取 a 的时候, Core 0 检测到了发生地址冲突(其它缓存读主存中该缓存行的操作),然后 Core 0 对相关数据做出响应,a 存储于这两个核心 Core 0 和 Core 1 的缓存行中,然后设置其状态为 S 状态(共享),该过程示意图如下:
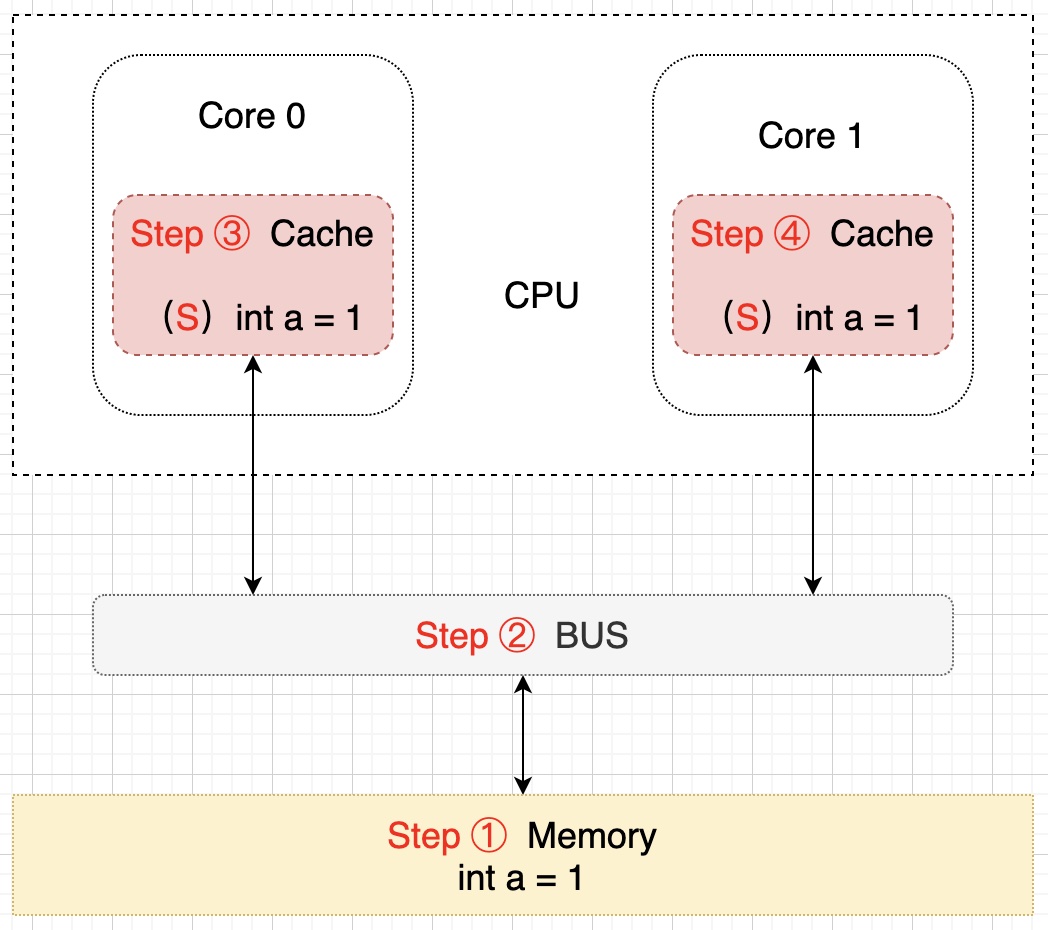
假设此时 Core 0 核心需要对 a 进行修改了,首先 Core 0 会将其缓存的 a 设置为 M(修改)状态,然后通知其它缓存了 a 的其它核 CPU(比如这里的 Core 1)将内部缓存的 a 的状态置为 I(无效)状态,最后才对 a 进行赋值操作。该过程如下所示:
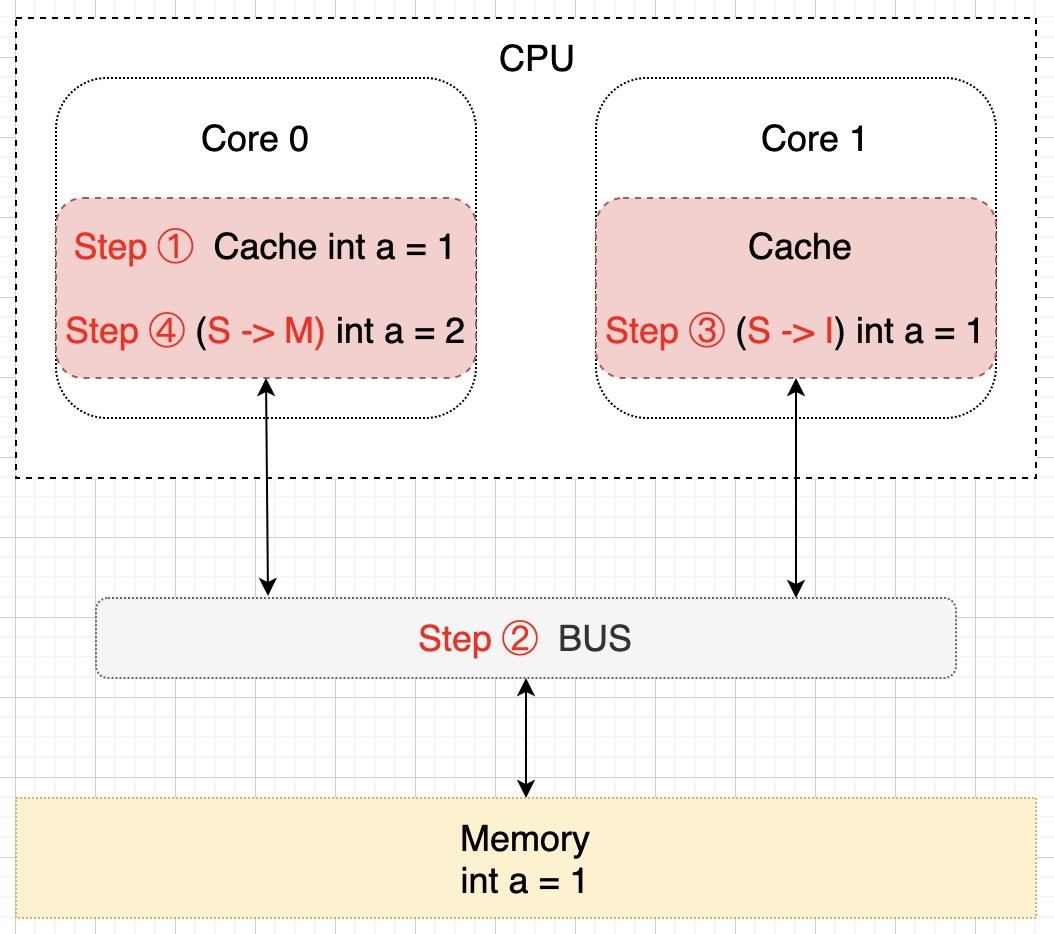
细心的朋友们可能已经注意到了,上图中内存中 a 的值(值为 1)并不等于 Core 0 核心中缓存的最新值(值为 2),那么要什么时候才会把该值更新到内存中去呢?就是当 Core 1 需要读取 a 的值的时候,此时会通知 Core 0 将 a 的修改后的最新值同步到内存(Memory)中去,在这个同步的过程中 Core 0 中缓存的 a 的状态会置为 E(独享)状态,同步完成后将 Core 0 和 Core 1 中缓存的 a 置为 S(共享)状态,示意图描述该过程如下所示:
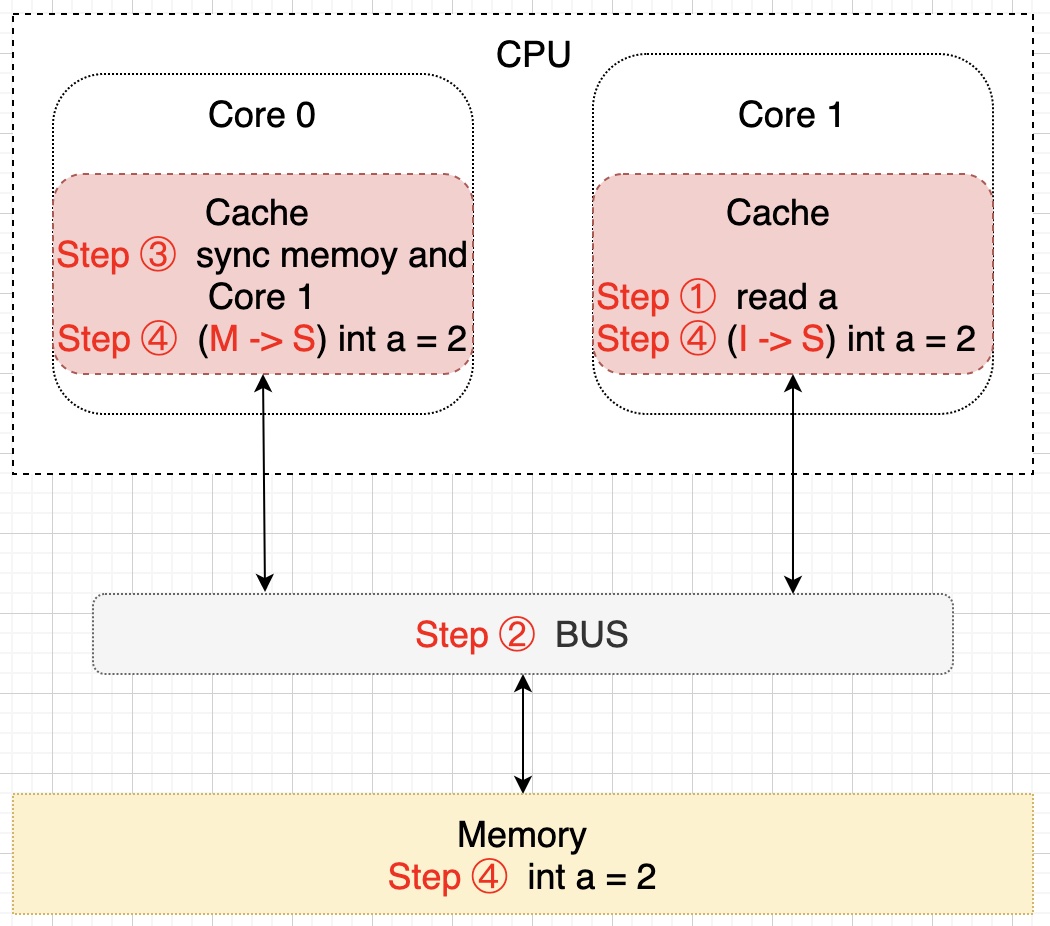
至此,变量 a 在 CPU 的两个核 Core 0 和 Core 1 中回到了 S(共享)状态了,以上只是简单的描述了一下大概的过程,实际上这些都是在 CPU 的硬件层面上去保证的,而且操作比较复杂。
五、总结
现在很多一些实现缓存功能的应用程序都是基于这些思想设计的,缓存把数据库中的数据进行缓存到速度更快的内存中,可以加快我们应用程序的响应速度,比如我们使用常见的 Redis 数据库可能是采用下面这些策略:① 首先应用程序从缓存中查询数据,如果有就直接使用该数据进行相应操作后返回,如果没有则查询数据库,更新缓存并且返回。② 当我们需要更新数据时,先更新数据库,然后再让缓存失效,这样下次就会先查询数据库再回填到缓存中去,可以发现,实际上底层的一些思想都是相通的,不同的只是对于特定的场景可能需要增加一些额外的约束。基础知识才是技术这颗大树的根,我们先把根栽好了,剩下的那些枝和叶都是比较容易得到的东西了。
从CPU缓存看缓存的套路的更多相关文章
- 【转载】为什么CPU有多层缓存
原文:为什么CPU有多层缓存 http://mp.weixin.qq.com/s?__biz=MzI1NDM2Nzg5Mw==&mid=2247483712&idx=1&sn= ...
- 浅谈CPU三级缓存和缓存命中率
CPU: CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多.缓存的出现主要是 为了解决CPU运算速度与内存读写速度不匹配的矛盾 ...
- cpu中的缓存和操作系统中的缓存分别是什么?
cpu中的缓存和操作系统中的缓存分别是什么? 在操作系统中,为了提高系统的存取速度,在地址映射机制中增加了一个小容量的联想寄存器,即块表.用来存放当前访问最频繁的少数活动页面的页数.当某用户需要存取数 ...
- android 网络加载图片,对图片资源进行优化,并且实现内存双缓存 + 磁盘缓存
经常会用到 网络文件 比如查看大图片数据 资源优化的问题,当然用开源的项目 Android-Universal-Image-Loader 或者 ignition 都是个很好的选择. 在这里把原来 ...
- PHP的OB缓存(输出缓存)
使用PHP自带的缓存机制 原则:如果ob缓存打开,则echo的数据首先放在ob缓存.如果是header信息,直接放在程序缓存.当页面执行到最后,会把ob缓存的数据放到程序缓存,然后依次返回给浏览器. ...
- MySQL内存----使用说明全局缓存+线程缓存) 转
MySQL内存使用说明(全局缓存+线程缓存) 首先我们来看一个公式,MySQL中内存分为全局内存和线程内存两大部分(其实并不全部,只是影响比较大的 部分): per_thread_buffers=(r ...
- redis-缓存穿透,缓存雪崩,缓存击穿,并发竞争
目录 缓存穿透 定义 解决方案 利用互斥锁 采用异步更新策略 使用布隆过滤器 空置缓存 缓存雪崩 定义 解决方案 给缓存的加一个随机失效时间 使用互斥锁 双缓存策略 缓存击穿 定义 解决方案 使用互斥 ...
- 缓存穿透 & 缓存击穿 & 缓存雪崩
参考文档: 缓存穿透和缓存失效的预防和解决:https://blog.csdn.net/qq_16681169/article/details/75138876 缓存穿透 缓存穿透是指查询一个一定不存 ...
- Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:缓存、Checkpoint
4. 缓存 概要 缓存的意义 缓存相关的 API 缓存级别以及最佳实践 4.1. 缓存的意义 使用缓存的原因 - 多次使用 RDD 需求: 在日志文件中找到访问次数最少的 IP 和访问次数最多的 IP ...
随机推荐
- js实现将时分秒转化成毫秒,将秒转化成时分秒
// 时间转为毫秒 timeToSec(time) { var hour = time.split('[0] var min = time.split('[1] var sec = time.spli ...
- Alpha阶段项目复审(鸽牌开发小分队)
团队:鸽牌开发专业小分队 项目:必备记 集合帖:集合帖 项目复审: 团队名字 项目链接 优点 缺点和bug报告 最终名次 歪瑞古德小队 海岛漂流 1.功能齐全,上手简单2.界面简洁美观3.想法新颖,可 ...
- 问卷星导入数据到SPSS,数据变成-3是什么原因?
问卷星将数字“-3”表示为筛选或者跳转题:如果问卷中有设计筛选或者跳转,此时则会出现“-3”这个数字. 解决办法1 分析时首先进行筛选,然后再分析,便不会出现“-3”,而且一定需要这样进行.“筛选样本 ...
- element-ul二次封装table表格
在项目中el的表格使用的地方太多了,若不进行封装,使用的时候页面会显得非常的冗余且难以维护,有时表格样式还不能做到一致:今天分享一个在工作中封装的表格 由于大多代码都在页面有介绍,就不在外面解释了 一 ...
- python给excel文件加密码,并重新生成文件
需安装pywin32 pip install pywin32 直接上源码.简单几行就搞定 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手. ...
- Photon PUN 一 介绍
有句话说的好 , 官网永远是最好的学习地方 . 虽然国内的资料不多 , 但是官网的资料还是很充足 , 这就带着英汉词典就着作阅读理解的劲头去官网学习吧 https://doc.photonengine ...
- C#显示百度地图API
http://dev.baidu.com/wiki/static/map/API/examples/?v=1.3&2_0#2&0 太原市的经纬度:112.596, 37.884 北京市 ...
- 熟练剖分(tree) 树形DP
熟练剖分(tree) 树形DP 题目描述 题目传送门 分析 我们设\(f[i][j]\)为以\(i\)为根节点的子树中最坏时间复杂度小于等于\(j\)的概率 设\(g[i][j]\)为当前扫到的以\( ...
- [Java数据结构]Queue
Queue扩展了Collection,它添加了支持根据先进先出FIFO原则对元素排序的方法. 当对Queue调用add和offer方法时,元素始终添加在Queue的末尾:要检索一个元素,就要使用一个元 ...
- Zookeeper原生客户端
1.1.1.1. 客户端基本操作 package cn.enjoy.javaapi; import org.apache.zookeeper.*; import java.io.IOException ...