Impala的count(distinct QUESTION_ID) 与ndv(QUESTION_ID)
在impala中,一个select执行多个count(distinct col)会报错,举例:
select C_DEPT2,
count(distinct QUESTION_BUSI_ID) as wo_num,
count(distinct CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
报错信息:
ERROR: AnalysisException: all DISTINCT aggregate functions need to have the same set of parameters as count(DISTINCT QUESTION_BUSI_ID); deviating function: count(DISTINCT CREATOR_ID)
Consider using NDV() instead of COUNT(DISTINCT) if estimated counts are acceptable. Enable the APPX_COUNT_DISTINCT query option to perform this rewrite automatically.
这时候,可通过以下方法解决:
1、得到的是近似值,数据量越大越不准确:
(1)SQL运行前,先运行命令:set APPX_COUNT_DISTINCT=true;
set APPX_COUNT_DISTINCT=true;
select C_DEPT2,
count(distinct QUESTION_BUSI_ID) as wo_num,
count(distinct CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
order by C_DEPT2
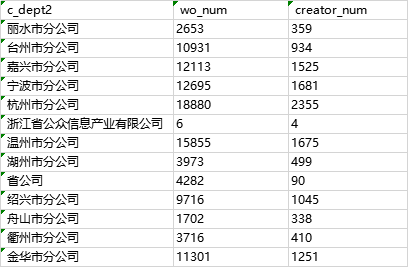
(2)将count(distinct col)用函数ndv(col)代替
select C_DEPT2,
ndv(QUESTION_BUSI_ID) as wo_num,
ndv(CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
order by C_DEPT2
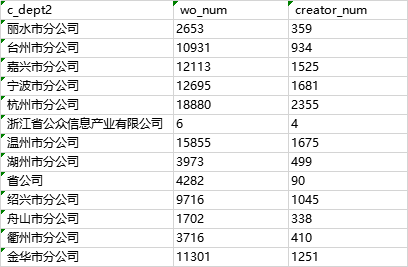
需要注意的是,在set APPX_COUNT_DISTINCT=true;的情况下,使用count(distinct col)会自动转化成ndv(col),得到的是近似值,所以以上两种方法的结果数据一致。
2、精确值。拆分为子查询,再关联,如下:
set APPX_COUNT_DISTINCT = false; -- 将参数置为false,使用count(distinct col),确保不会转化成ndv(col)
select a.C_DEPT2, a.wo_num, b.creator_num
from (select C_DEPT2, count(distinct QUESTION_BUSI_ID) as wo_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2) a
left join (select C_DEPT2, count(distinct CREATOR_ID) as creator_num
from pdm.kudu_q_basic
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2) b on a.C_DEPT2 = b.C_DEPT2
order by a.C_DEPT2
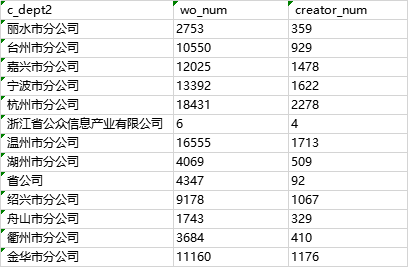
验证:
select C_DEPT2, count(*)
from pdm.kudu_q_basic -- 表中无重复数据
where substr(CREATE_DATE, 1, 7) = '2020-10'
group by C_DEPT2
order by C_DEPT2

总结:解决在impala中一个select执行多个count(distinct col)报错问题,可以用过设置参数set APPX_COUNT_DISTINCT = true;或将count(distinct col)用ndv(col)解决,但得到的是近似值,不准确。还可以通过分别在子查询中进行count(distinct col)再关联得到准确值,但要注意参数 APPX_COUNT_DISTINCT = false,不然会自动转化为ndv(col)得到的还是近似值。
Impala的count(distinct QUESTION_ID) 与ndv(QUESTION_ID)的更多相关文章
- 关于MySQL count(distinct) 逻辑的一个bug【转】
本文来自:http://dinglin.iteye.com/blog/1976026#comments 背景 客户报告了一个count(distinct)语句返回结果错误,实际结果存在值,但是用cou ...
- 使用GROUP BY统计记录条数 COUNT(*) DISTINCT
例如这样一个表,我想统计email和passwords都不相同的记录的条数 CREATE TABLE IF NOT EXISTS `test_users` ( `email_id` ) unsigne ...
- COUNT(*),count(1),COUNT(ALL expression),COUNT(DISTINCT expression)
创建一个测试表 IF OBJECT_ID( 'dbo.T1' , 'U' )IS NOT NULL BEGIN DROP TABLE dbo.T1; END; GO )); GO INSERT INT ...
- SQL server 中 COUNT DISTINCT 函数
目的:统计去重后表中所有项总和. 直观想法: SELECT COUNT(DISTINCT *) FROM [tablename] 结果是:语法错误. 事实上,我们可以一同使用 DISTINCT 和 C ...
- pandas pivot_table或者groupby实现sql 中的count distinct 功能
pandas pivot_table或者groupby实现sql 中的count distinct 功能 import pandas as pd import numpy as np data = p ...
- COUNT DISTINCT ROW_NUMBER DENSE_RANK 以及对COUNT去重(非PARTITION)
1:COUNT DISTINCT SELECT COUNT(DISTINCT [QS_QuestionStem].Id) AS ReqCount1, ...
- count(distinct) 与group by 浅析
x在传统关系型数据库中,group by与count(distinct)都是很常见的操作.count(distinct colA)就是将colA中所有出现过的不同值取出来,相信只要接触过数据库的同学都 ...
- 使用子查询可提升 COUNT DISTINCT 速度 50 倍
注:这些技术是通用的,只不过我们选择使用Postgres的语法.使用独特的pgAdminIII生成解释图形. 很有用,但太慢 Count distinct是SQL分析时的祸根,因此它是我第一篇博客的不 ...
- 【hive】count() count(if) count(distinct if) sum(if)的区别
表名: user_active_day (用户日活表) 表内容: user_id(用户id) user_is_new(是否新用户 1:新增用户 0:老用户) location_city(用户所在地 ...
随机推荐
- Android中Application的意义及使用方法
首先,在一个Android程序中,有且只有一个Application对象,在程序启动的时候,首先执行Application的onCreate方法,这是一个Android应用的入口,在开发中,我们常常自 ...
- 查询Oracle日志文件的方法
Oracle日志文件相信经常使用Oracle数据库的朋友都比较熟悉了,下面将为您介绍的是查询Oracle日志文件的几种方法,供您参考学习. 1.查询系统使用的是哪一组日志文件: select * fr ...
- 第四十一章、PyQt显示部件:TextBrowser、CalendarWidget、LCDNumber、ProgressBar、Label、HorizontalLine和VerticalLine简介
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 一.概述 在Designer中,显示部件有Labe ...
- 虚拟IP原理及使用
一.前言 高可用性 HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性.HA 系统是目前企业防止核心 ...
- caffe源码 全连接层
图示全连接层 如上图所示,该全链接层输入n * 4,输出为n * 2,n为batch 该层有两个参数W和B,W为系数,B为偏置项 该层的函数为F(x) = W*x + B,则W为4 * 2的矩阵,B ...
- C++编程指南续(10-11)
十.类的继承与组合 对象(Object)是类(Class)的一个实例(Instance).如果将对象比作房子,那么类就是房子的设计图纸.所以面向对象设计的重点是类的设计,而不是对象的设计. 对于C++ ...
- mybatis-generator 插件用法
xml 配置 1 <?xml version="1.0" encoding="UTF-8"?> 2 <!DOCTYPE generatorCo ...
- 深入理解Java虚拟机(二)——HotSpot对象创建、内存、访问
对象的创建 虚拟机遇到一条字节码new指令时,开始对象创建过程. 首先去检查这个指令的参数是否能在常量池定位到一个类的符号引用: 检查这个符号引用代表的类是否已被加载.解析和初始化,如果没有就必须执行 ...
- 服务器ganglia安装(带有登录验证)
1.ganglia组件gmond相当于agent端,主要手机各node的性能状态:gmetad相当于server端,从gmond以poll的方式收集和存储原数据:ganglia-web相当于一个web ...
- Day3 条件判断和循环
条件判断 if...else if...elif...else 格式: 注意缩进! if x: active elif y: active else : active 注 ...