pandas数据结构之Dataframe
Dataframe
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(多个series共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(numpy的二维数组)
dataframe的创建
最常用的方法是传递一个字典或者二维数组的方法创建
DataFrame(data=data,index=['张三','李四','王五'],columns=list('语数外'))
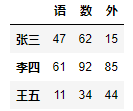
另外通过导入csv文件得到的也是DataFrame
import pandas as pd
df1 = pd.read_csv('../backup/data/president_heights.csv') # 路径名
DataFrame属性:values、columns、index、shape
values:表格中的数据(二维数组)
columns:列索引
index:行索引
shape:形状
Dataframe的索引
(1) 对列进行索引
- 通过类似字典的方式
- 通过属性的方式
按照列名进行索引,获取到一个Series
d = np.random.randint(0,100,size=(3,4))
d
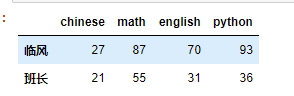
i = ['临风','班长','孙武空'] # 行索引
c = ['chinese','math','english','python'] # 列索引
df = DataFrame(d,i,c)

df['math']
临风 87
班长 55
孙武空 28
Name: math, dtype: int32 type(df['math'])
pandas.core.series.Series df.math
临风 87
班长 55
孙武空 28
Name: math, dtype: int32
(2) 对行进行索引
- 使用.loc[]加index来进行行索引,显式索引
- 使用.iloc[]加整数来进行行索引,隐式索引
同样返回一个Series,index为原来的columns。
# df.loc['临风'] # 显式索引
df.iloc[0] # 隐式所引进
chinese 27
math 87
english 70
python 93
Name: 临风, dtype: int32
总结
对 列 进行索引 df['列名'] df.列名 得到的是Series
对 行 进行索引 df.loc['行名'] df.iloc[行序号] 得到的是Series
(3) 对元素索引的方法
- 使用列索引
- 使用行索引
- 使用values属性(二维numpy数组)# 对具体元素进行定位
df.python.loc['班长'] # 先按列找 找到的是Series 在对Series进行索引
df.loc['班长'].iloc[-1] # df的loc或者iloc提供了更加优雅的方式
df.loc['班长','python']
df.iloc[1,-1] df.values # 如果DataFrame的索引记不清 可以直接通过values然后去定位值
array([[27, 87, 70, 93],
[21, 55, 31, 36],
[38, 28, 24, 37]])
df.values[1,-1]
【注意】 直接使用中括号时:
- 索引表示的是列索引
- 切片表示的是行切片
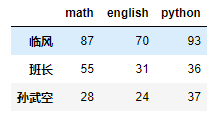
df['临风':'孙武空']
df['临风':'班长'] # 直接使用中括号 不能对列进行切片 而是对行进行切片(因为对行进行切片的需求比较常见)
# 如果非要对列 进行切片 可以使用loc或者iloc
df.loc[:,'math':'python']
Dataframe的运算
(0) df和数值
df +5
相当于给表中的所有的数据都+5
# 对某一行样本进行修改
df.loc['临风']+=100
(1) DataFrame之间的运算
同Series一样:
- 在运算中自动对齐不同索引的数据
- 如果索引不对应,则补NaN
# 创建DataFrame df1 不同人员的各科目成绩,月考一
d = np.random.randint(0,100,size=(4,3))
d
i = ['jack','rose','tom','jerry'] # 行索引
c = ['math','english','python'] # 列索引
df1 = DataFrame(d,i,c)
df1
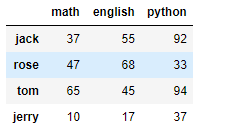
# 创建DataFrame df2 不同人员的各科目成绩,月考二 有新学生转入
d = np.random.randint(0,100,size=(5,3))
d
i = ['jack','rose','tom','jerry','bob'] # 行索引
c = ['math','english','python'] # 列索引
df2 = DataFrame(d,i,c)
df2
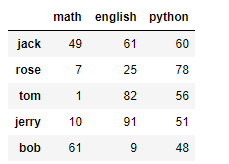
display(df1,df2) 可以让数据同时显示
df1+df2
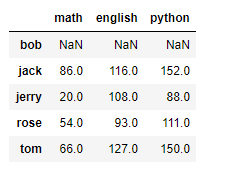
那么有没有办法不显示NaN呢,肯定是有的
其实对象使用 + 相加其实是执行了类中的add方法
所以
df1.add(df2,fill_value=0) # 设置上这个参数就可以给没有的数据设定一个默认值=
结果展示:

下面是Python 操作符与pandas操作函数的对应表:

(2) Series与DataFrame之间的运算
【重要】
使用Python操作符:以行为单位操作,对所有行都有效。(类似于numpy中二维数组与一维数组的运算,但可能出现NaN)
使用pandas操作函数:
axis=0:以列为单位操作(参数必须是列),对所有列都有效。
axis=1:以行为单位操作(参数必须是行),对所有行都有效。
例子:
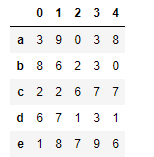
df = DataFrame(data=np.random.randint(0,10,size=(5,5)),index=list('abcde'),columns=list(''))
df
s1 = Series(data=np.random.randint(0,10,size=5),index=list(''))
s1
0 1
1 3
2 1
3 1
4 9
dtype: int32
df+s1 # 表格和序列 相加 默认 每一行都要和序列相加 对应项相加
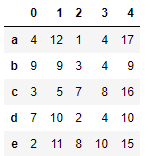
s2 = Series(data=np.random.randint(0,10,size=5),index=list('abcde'))
s2
df+s2 # 输出的结果全部都是NaN
# axis='columns' 默认是columns 每一行和Series相加 让列名和Series中的索引去对应
df.add(s2,axis='index')
pandas数据结构之Dataframe的更多相关文章
- pandas 学习(2): pandas 数据结构之DataFrame
DataFrame 类型类似于数据库表结构的数据结构,其含有行索引和列索引,可以将DataFrame 想成是由相同索引的Series组成的Dict类型.在其底层是通过二维以及一维的数据块实现. 1. ...
- pandas数据结构之DataFrame操作
这一次我的学习笔记就不直接用官方文档的形式来写了了,而是写成类似于“知识图谱”的形式,以供日后参考. 下面是所谓“知识图谱”,有什么用呢? 1.知道有什么操作(英文可以不看) 2.展示本篇笔记的结构 ...
- pandas数据结构之DataFrame笔记
DataFrame输出的为表的形式,由于要把输出的表格贴上来比较麻烦,在此就不在贴出相关输出结果,代码在jupyter notebook可以顺利运行代码中有相关解释用来加深理解方便记忆 import ...
- 03. Pandas数据结构
03. Pandas数据结构 Series DataFrame 从DataFrame中查询出Series 1. Series Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一 ...
- pandas数据结构:Series/DataFrame;python函数:range/arange
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- Pandas 数据结构Dataframe:基本概念及创建
"二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值.字符串.布尔值等. Dataframe中的数据以一个或多个二维块存放,不是列表.字 ...
- pandas 学习(1): pandas 数据结构之Series
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会 ...
- pandas教程1:pandas数据结构入门
pandas是一个用于进行python科学计算的常用库,包含高级的数据结构和精巧的工具,使得在Python中处理数据非常快速和简单.pandas建造在NumPy之上,它使得以NumPy为中心的应用很容 ...
- pandas数据结构练习题(部分)
更多函数查阅http://pandas.pydata.org/pandas-docs/stable/10min.htmlimport pandas as pd#两种数据结构from pandas im ...
随机推荐
- time和datetime和tzinfo
time和datetime模块还有tzinfo (时区)(一直不明白两者的区别,然后摘了两片文章(最后面的两个链接),很清晰...) 一.time模块 常用函数 1. time()函数 time()函 ...
- Centos7.1环境下搭建BugFree
环境准备: 系统 配置 IP Centos7.1 1核2G+60GB硬盘 10.10.28.204 1. 安装apache yum install httpd 2. 安装mysql yum inst ...
- 20190422 DW/BI系统
其实很多人都不能理解操作型应用系统和分析型系统的意义,主要问题在于这两个系统所面对的用户和需求是不相同的. 建模重点“凡事应该简单,简单到不能再简单”
- 为什么python中没有switch case语句
终于知道了python中映射的设计哲学. 我自己写的code : class order_status_switcher(object): def get_order_status(self,argu ...
- python笔记-正则表达式常用函数
1.re.findall()函数 语法:re.findall(pattern,string,flags=0) --> list(列表) 列出字符串中模式的所有匹配项,并作为一个列表返回.如果无匹 ...
- servlet-servlet的简单认识——源码解析
Servlet的基本认识 本内容主要来源于<看透Spring MVC源码分析与实践——韩路彪>一书 Servlet是server+Applet的缩写,表示一个服务器的应用.Servlet其 ...
- 初识GitHub之创建文件
在新建了一个项目(repository)后,会跳转到项目主页,如下图 Create new file(创建新文件)就是新建一个代码文件,Upload file(上传文件)即从内存中将代码文件上传至本项 ...
- 1*1的卷积核与Inception
https://www.zhihu.com/question/56024942 https://blog.csdn.net/a1154761720/article/details/53411365 本 ...
- SiteCore Experience Analytics-路径分析地图
路径分析地图 路径分析器是一个应用程序,允许您查看联系人在浏览网站时所采用的各种路径.您可以查看联系人在转换目标并与广告系列互动时所采用的路径,让您深入了解哪些路径为每次转化提供最佳参与价值,以及哪些 ...
- 和 (DFS)
和 Time Limit: 1000MS Memory Limit: 65536KB Total Submissions: 177 Accepted: 93 Share Description: ...