Pandas 数据结构Dataframe:基本概念及创建
"二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值、字符串、布尔值等。
Dataframe中的数据以一个或多个二维块存放,不是列表、字典或一维数组结构。
1. Dataframe的数据结构
# Dataframe 数据结构
# Dataframe是一个表格型的数据结构,“带有标签的二维数组”。
# Dataframe带有index(行标签)和columns(列标签) data = {'name':['Jack','Tom','Mary'],
'age':[18,19,20],
'gender':['m','m','w']}
frame = pd.DataFrame(data)
print(frame,'\n')
print(type(frame),'\n')
print(frame.index,'\n该数据类型为:',type(frame.index),'\n')
print(frame.columns,'\n该数据类型为:',type(frame.columns),'\n')
print(frame.values,'\n该数据类型为:',type(frame.values),'\n')
# 查看数据,数据类型为dataframe
# .index查看行标签
# .columns查看列标签
# .values查看值,数据类型为ndarray
输出结果:
age gender name
0 18 m Jack
1 19 m Tom
2 20 w Mary <class 'pandas.core.frame.DataFrame'> RangeIndex(start=0, stop=3, step=1)
该数据类型为: <class 'pandas.indexes.range.RangeIndex'> Index(['age', 'gender', 'name'], dtype='object')
该数据类型为: <class 'pandas.indexes.base.Index'> [[18 'm' 'Jack']
[19 'm' 'Tom']
[20 'w' 'Mary']]
该数据类型为: <class 'numpy.ndarray'>
2.数据结构其他注意的地方
print(frame,'\n')
print(frame.columns.tolist(),'\n') #查看列名
print(frame.values,'\n') #嵌套列表
print(frame.values.tolist())
输出结果:
age gender name
0 18 m Jack
1 19 m Tom
2 20 w Mary ['age', 'gender', 'name'] [[18 'm' 'Jack']
[19 'm' 'Tom']
[20 'w' 'Mary']] [[18, 'm', 'Jack'], [19, 'm', 'Tom'], [20, 'w', 'Mary']]
3. #Series 与 Dataframe的关系 其实就是Dataframe的一列
age = frame['age'] #列的索引
print(age)
print(type(age))
输出结果:
0 18
1 19
2 20
Name: age, dtype: int64
<class 'pandas.core.series.Series'>
二. DataFrame 的创建方法
1.由数组/list组成的字典
# Dataframe 创建方法一:由数组/list组成的字典
# 创建方法:pandas.Dataframe() data1 = {'a':[1,2,3],
'b':[3,4,5],
'c':[5,6,7]}
data2 = {'one':np.random.rand(3),
'two':np.random.rand(3)} # 这里如果尝试 'two':np.random.rand(4) 会怎么样?
print(data1)
print(data2)
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
print(df1)
print(df2)
# 由数组/list组成的字典 创建Dataframe,columns为字典key,index为默认数字标签
# 字典的值的长度必须保持一致! df1 = pd.DataFrame(data1, columns = ['b','c','a','d'])
print(df1)
df1 = pd.DataFrame(data1, columns = ['b','c'])
print(df1)
# columns参数:可以重新指定列的顺序,格式为list,如果现有数据中没有该列(比如'd'),则产生NaN值
# 如果columns重新指定时候,列的数量可以少于原数据
df1['s'] = 10 #添加列
print(df1)
del df1['s'] #删除列
print(df1) df2 = pd.DataFrame(data2, index = ['f1','f2','f3']) # 这里如果尝试 index = ['f1','f2','f3','f4'] 会怎么样?——》会报错
print(df2)
# index参数:重新定义index,格式为list,长度必须保持一致 添加列没事,添加标签就不行了
输出结果:
{'b': [3, 4, 5], 'a': [1, 2, 3], 'c': [5, 6, 7]}
{'one': array([0.53592778, 0.1429434 , 0.40188575]), 'two': array([0.59196586, 0.40463609, 0.66488198])}
a b c
0 1 3 5
1 2 4 6
2 3 5 7
one two
0 0.535928 0.591966
1 0.142943 0.404636
2 0.401886 0.664882
b c a d
0 3 5 1 NaN
1 4 6 2 NaN
2 5 7 3 NaN
b c
0 3 5
1 4 6
2 5 7
b c s
0 3 5 10
1 4 6 10
2 5 7 10
b c
0 3 5
1 4 6
2 5 7
one two
f1 0.535928 0.591966
f2 0.142943 0.404636
f3 0.401886 0.664882
2. # Dataframe 创建方法二:由Series组成的字典
# Dataframe 创建方法二:由Series组成的字典
data1 = {'one':pd.Series(np.random.rand(2)),
'two':pd.Series(np.random.rand(3))} # 没有设置index的Series
data2 = {'one':pd.Series(np.random.rand(2), index = ['a','b']),
'two':pd.Series(np.random.rand(3),index = ['a','b','c'])} # 设置了index的Series
print(data1)
print(data2)
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
print(df1)
print(df2)
# 由Seris组成的字典 创建Dataframe,columns为字典key,index为Series的标签(如果Series没有指定标签,则是默认数字标签)
# Series可以长度不一样,生成的Dataframe会出现NaN值
输出结果:
{'two': 0 0.331382
1 0.508265
2 0.615997
dtype: float64, 'one': 0 0.857739
1 0.165800
dtype: float64}
{'two': a 0.826446
b 0.983392
c 0.187749
dtype: float64, 'one': a 0.920073
b 0.215178
dtype: float64}
one two
0 0.857739 0.331382
1 0.165800 0.508265
2 NaN 0.615997
one two
a 0.920073 0.826446
b 0.215178 0.983392
c NaN 0.187749
3.# Dataframe 创建方法三:通过二维数组直接创建
# Dataframe 创建方法三:通过二维数组直接创建 ar = np.random.rand(9).reshape(3,3)
print(ar)
df1 = pd.DataFrame(ar)
df2 = pd.DataFrame(ar, index = ['a', 'b', 'c'], columns = ['one','two','three']) # 可以尝试一下index或columns长度不等于已有数组的情况
print(df1)
print(df2)
# 通过二维数组直接创建Dataframe,得到一样形状的结果数据,如果不指定index和columns,两者均返回默认数字格式
# index和colunms指定长度与原数组保持一致
输出结果:
[[0.33940056 0.77384698 0.25308293]
[0.28151251 0.02875986 0.7516066 ]
[0.34746659 0.25245068 0.68979615]]
0 1 2
0 0.339401 0.773847 0.253083
1 0.281513 0.028760 0.751607
2 0.347467 0.252451 0.689796
one two three
a 0.339401 0.773847 0.253083
b 0.281513 0.028760 0.751607
c 0.347467 0.252451 0.689796
4.其他注意的地方:
df = pd.DataFrame(np.random.randn(100,3),columns = ['A','B','C']) #后面常用到的
df
import matplotlib.pyplot as plt
df.plot()
plt.show()
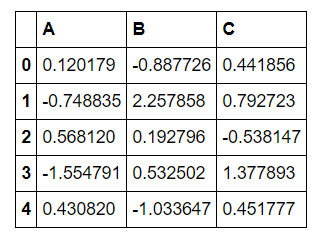
df.head() #查看表头,默认查看前五条数据
输出结果:
Pandas 数据结构Dataframe:基本概念及创建的更多相关文章
- Pandas 数据结构Series:基本概念及创建
Series:"一维数组" 1. 和一维数组的区别 # Series 数据结构 # Series 是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象 ...
- 数据分析入门——pandas之DataFrame基本概念
一.介绍 数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列. 可以看作是Series的二维拓展,但是df有行列索引:index.column 推荐参考:https://www. ...
- Pandas之DataFrame——Part 1
''' [课程2.] Pandas数据结构Dataframe:基本概念及创建 "二维数组"Dataframe:是一个表格型的数据结构,包含一组有序的列,其列的值类型可以是数值.字符 ...
- pandas(DataFrame)
DataFrame是二维数据结构,即数据以行和列的表格方式排列!特点:潜在的列是不同的类型,大小可变,标记行和列,可以对列和行执行算数运算. 其中Name,Age即为对应的Columns,序号0,1, ...
- Pandas | 03 DataFrame 数据帧
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列. 数据帧(DataFrame)的功能特点: 潜在的列是不同的类型 大小可变 标记轴(行和列) 可以对行和列执行算术运算 结构体 ...
- [译]从列表或字典创建Pandas的DataFrame对象
原文来源:http://pbpython.com/pandas-list-dict.html 介绍 每当我使用pandas进行分析时,我的第一个目标是使用众多可用选项中的一个将数据导入Pandas的D ...
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的, 导入如下: from panda ...
- pandas中的数据结构-DataFrame
pandas中的数据结构-DataFrame DataFrame是什么? 表格型的数据结构 DataFrame 是一个表格型的数据类型,每列值类型可以不同 DataFrame 既有行索引.也有列索引 ...
- pandas数据结构之DataFrame笔记
DataFrame输出的为表的形式,由于要把输出的表格贴上来比较麻烦,在此就不在贴出相关输出结果,代码在jupyter notebook可以顺利运行代码中有相关解释用来加深理解方便记忆 import ...
随机推荐
- python的元组
Python的元组和列表很相似,只是元组一旦定义就无法修改,比如定义一个学生的元组: names = ('alex','jack') print(names)#('alex', 'jack') pri ...
- nvd3基于时间轴流程图
doc http://nvd3-community.github.io/nvd3/examples/documentation.html https://github.com/mbostock/d3/ ...
- Centos 7.0_64bit 下安装 Zabbix server 3.0服务器的安装
一.关闭selinux 修改配置文件/ etc / selinux / config,将SELINU置为禁用(disabled) vim /etc/selinux/config # This ...
- win10下各种问题的解决办法
本来申请这个博客是为了写一些Java学习笔记的,但是鉴于我半年内无数次重装系统的惨痛经历,所以把win10系统的一些问题总结一下. 此账号密码:1994llz. 1.win10取消开机密码: http ...
- 笨办法学Python(十九)
习题 19: 函数和变量 函数这个概念也许承载了太多的信息量,不过别担心.只要坚持做这些练习,对照上个练习中的检查点检查一遍这次的联系,你最终会明白这些内容的. 有一个你可能没有注意到的细节,我们现在 ...
- 在微信小程序里自动获得当前手机所在的经纬度并转换成地址
效果:我在手机上打开微信小程序,自动显示出我当前所在的地理位置: 具体步骤: 1. 使用微信jssdk提供的getLocation API拿到经纬度: 2. 调用高德地图的api使用经纬度去换取地址的 ...
- 如何计算并测量ABAP及Java代码的环复杂度Cyclomatic complexity
代码的环复杂度(Cyclomatic complexity,有的地方又翻译成圈复杂度)是一种代码复杂度的衡量标准,在1976年由Thomas J. McCabe, Sr. 提出. 在软件测试的概念里, ...
- 委托代码func和Action的基本用法
这是微软简化后的委托写法,其中,func适合带返回参数的方法调用,action适合没有返回参数的方法调用 FUNC方法代码: public string GetPeopleInfo(string na ...
- paper-list
1.yolo-v1,yolo-v2,yolo-v3 2.ssd,focal loss,dssd 3.fast-rcnn,faster-rcnn,r-fcn,Light-Head R-CNN,R-FCN ...
- 卷积神经网络CNN在自然语言处理的应用
摘要:CNN作为当今绝大多数计算机视觉系统的核心技术,在图像分类领域做出了巨大贡献.本文从计算机视觉的用例开始,介绍CNN及其在自然语言处理中的优势和发挥的作用. 当我们听到卷积神经网络(Convol ...