spark streaming 整合 kafka(一)
转载:https://www.iteblog.com/archives/1322.html
Apache Kafka是一个分布式的消息发布-订阅系统。可以说,任何实时大数据处理工具缺少与Kafka整合都是不完整的。本文将介绍如何使用Spark Streaming从Kafka中接收数据,这里将会介绍两种方法:(1)、使用Receivers和Kafka高层次的API;(2)、使用Direct API,这是使用低层次的KafkaAPI,并没有使用到Receivers,是Spark 1.3.0中开始引入的。这两种方法有不同的编程模型,性能特点和语义担保。下文将会一一介绍。
1、基于reciver的方式
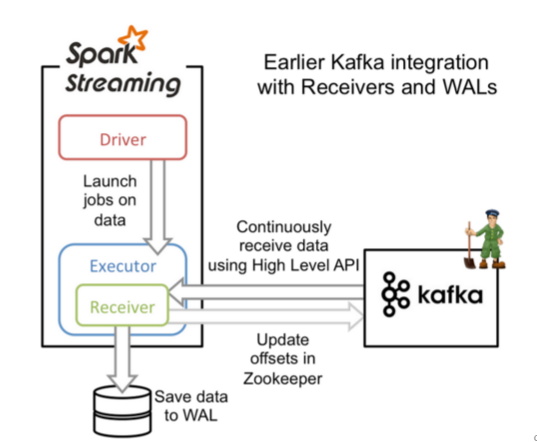
然而,在默认的配置下,这种方法在失败的情况下会丢失数据,为了保证零数据丢失,你可以在Spark Streaming中使用WAL日志,这是在Spark 1.2.0才引入的功能,这使得我们可以将接收到的数据保存到WAL中(WAL日志可以存储在HDFS上),所以在失败的时候,我们可以从WAL中恢复,而不至于丢失数据。
1、引入依赖(依据版本需要进行更改)。
对于Scala和Java项目,你可以在你的pom.xml文件引入以下依赖:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_2.10</artifactId> <version>1.3.0</version></dependency> |
如果你是使用SBT,可以这么引入:
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka_2.10" % "1.3.0" |
2、编程
在Streaming程序中,引入KafkaUtils,并创建一个输入DStream:
import org.apache.spark.streaming.kafka._val kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume]) |
在创建DStream的时候,你也可以指定数据的Key和Value类型,并指定相应的解码类。
1、Kafka中Topic的分区和Spark Streaming生成的RDD中分区不是一个概念。所以,在
KafkaUtils.createStream()增加特定主题分区数仅仅是增加一个receiver中消费Topic的线程数。并不增加Spark并行处理数据的数量;
2、对于不同的Group和tpoic我们可以使用多个receivers创建不同的DStreams来并行接收数据;
3、如果你启用了WAL,这些接收到的数据将会被持久化到日志中,因此,我们需要将storage level 设置为StorageLevel.MEMORY_AND_DISK_SER ,也就是:
KafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER) |
3、部署
对应任何的Spark 应用,我们都是用spark-submit来启动你的应用程序,对于Scala和Java用户,如果你使用的是SBT或者是Maven,你可以将spark-streaming-kafka_2.10及其依赖打包进应用程序的Jar文件中,并确保spark-core_2.10和 spark-streaming_2.10标记为provided,因为它们在Spark 安装包中已经存在:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.10</artifactId> <version>1.3.0</version> <scope>provided</scope></dependency><dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.3.0</version> <scope>provided</scope></dependency> |
然后使用spark-submit来启动你的应用程序。
[iteblog@ spark]$ spark-1.3.0-bin-2.6.0/bin/spark-submit --master yarn-cluster --class iteblog.KafkaTest --jars lib/spark-streaming-kafka_2.10-1.3.0.jar, lib/spark-streaming_2.10-1.3.0.jar, lib/kafka_2.10-0.8.1.1.jar,lib/zkclient-0.3.jar, lib/metrics-core-2.2.0.jar ./iteblog-1.0-SNAPSHOT.jar |
下面是一个完整的例子:
object KafkaWordCount { def main(args: Array[String]) { if (args.length < 4) { System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>") System.exit(1) } StreamingExamples.setStreamingLogLevels() val Array(zkQuorum, group, topics, numThreads) = args val sparkConf = new SparkConf().setAppName("KafkaWordCount") val ssc = new StreamingContext(sparkConf, Seconds(2)) ssc.checkpoint("checkpoint") val topicMap = topics.split(",").map((_,numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2) val words = lines.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1L)) .reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2) wordCounts.print() ssc.start() ssc.awaitTermination() }} |
spark streaming 整合 kafka(一)的更多相关文章
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
- Spark 系列(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark 针对 Kafka 的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10,其主要区别如下 ...
- Spark之 Spark Streaming整合kafka(并演示reduceByKeyAndWindow、updateStateByKey算子使用)
Kafka0.8版本基于receiver接受器去接受kafka topic中的数据(并演示reduceByKeyAndWindow的使用) 依赖 <dependency> <grou ...
- spark streaming 整合kafka(二)
转载:https://www.iteblog.com/archives/1326.html 和基于Receiver接收数据不一样,这种方式定期地从Kafka的topic+partition中查询最新的 ...
- Spark之 Spark Streaming整合kafka(Java实现版本)
pom依赖 <properties> <scala.version>2.11.8</scala.version> <hadoop.version>2.7 ...
- spark streaming整合kafka
版本说明:spark:2.2.0: kafka:0.10.0.0 object StreamingDemo { def main(args: Array[String]): Unit = { Logg ...
- Spark Streaming 整合 Kafka
一:通过设置检查点,实现单词计数的累加功能 object StatefulKafkaWCnt { /** * 第一个参数:聚合的key,就是单词 * 第二个参数:当前批次产生批次该单词在每一个分区出现 ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- Spark Streaming和Kafka整合是如何保证数据零丢失
转载:https://www.iteblog.com/archives/1591.html 当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢 ...
随机推荐
- iOS 弹出菜单UIMenuController的基本使用
UIMenuController,弹出菜单@implementation DragView{ CGPoint startLocation; CGFloat rotation;}-(inst ...
- Fiddler修改图片显示
培训课讲修改请求值,记录一下操作步骤: 步骤如下: 1. 点击人人网图片另存为到桌面 2. 打开fiddler,找到图片发送的请求(单击图片的链接,点击右边面板的Inspectors.查看ImageV ...
- C#:进程
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...
- 记使用talend从oracle抽取数据时,数字变为0的问题
数据源为oracle,字段类型为number. 发现通过mainline连接到一个logrow控件,输入的该字段的值为0 经过多次测试还是没发现有什么规律. 通过查看代码发现有这一句内容. if (r ...
- Java 中的E,K,V,T,U,S
Java泛型中的标记符含义: E - Element (在集合中使用,因为集合中存放的是元素) T - Type(Java 类) K - Key(键) V - Value(值) N - Number ...
- [Android] TextView上同时显示图标和文字
需求场景 +----------------------------+ | Icon TEXT | +----------------------------+ 当然,可以使用LineLayout,包 ...
- Delphi7打开项目提示'one or more lines were too long and has been truncated'
打开主项目文件直接显示一排'口'形状!查了下资料也问了下伙伴,这多半应该是文件损坏了,解决办法: 1. 不关D7的事,所以重装D7应该是无效的,最好看看自己是不是有备份文件,我之前有备份的所以直接覆盖 ...
- introduce myself
大家好啊,我是来自计算机一班的喻达龙,是2018届的萌新一个,很高兴与大家相约在这里.我想,大家都是怀抱相同的梦想带着一样的抱负走进涉外.我们从稚嫩蜕化为成熟,我相信我们在这里会从菜鸟变为大佬的,当然 ...
- P1996 约瑟夫问题
P1996 约瑟夫问题 广度优先搜索 我竟然寄几做对了 这个题用到了队列 下面详细解释: 我的代码: #include<iostream> #include<cstdio> # ...
- Collections.sort 的日期排序
public static void main(String[] args) throws ParseException { // sort降序排列 List<Date> dates = ...