201904Online Human Action Recognition Based on Incremental Learning of Weighted Covariance Descriptors
论文标题:Online Human Action Recognition Based on Incremental Learning of Weighted Covariance Descriptors
来源/作者机构情况:

卧龙岗大学(世界排名230~),第一次听说这个学校。竟然是在澳大利亚的一个学校。好吧,华人果然全球了
李老师是本硕都是浙大的,李老师个人链接如下:
https://www.uow.edu.au/~wanqing/#UOWActionDatasets
解决问题/主要思想贡献:
使用一个加权协方差因子,来积累前几帧的信息,使用增强学习来实现online learning,可以不用使用分好段的视频来预测动作
成果/优点:
1.延时,错误率和丢失率都有很多提升
缺点:
反思改进/灵感:
#############################################################
论文主要内容与关键点:
1.Introduction

前人研究的主要分类方法,缺点是没有办法实时检测

视频动作的特征表现,主要依靠这两种
2.Related Work
主要介绍了一下,上面两种分类方法,主要的几个研究方法,讲了一下这些的缺点。

特别强调了一个苏联人的一个方法,并讲解自己的文字解决了他的两个问题:没有权重的对待不同帧
3.The proposed method
权重方差因子:


时间权重的变化:
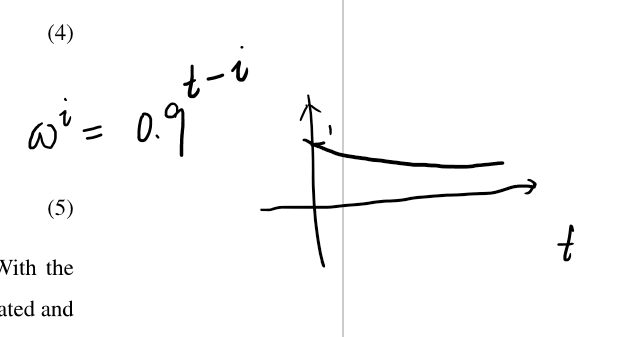
帧权重的变化:

这里,能量是结点的动量和势能。

增量学习:

后面还给予了证明。
4.Experimental Results
一些度量性能。还有结果展示

后面使用了一些去噪和归一化
动作特征向量的选取:

使用KNN和SVM进行特征分类
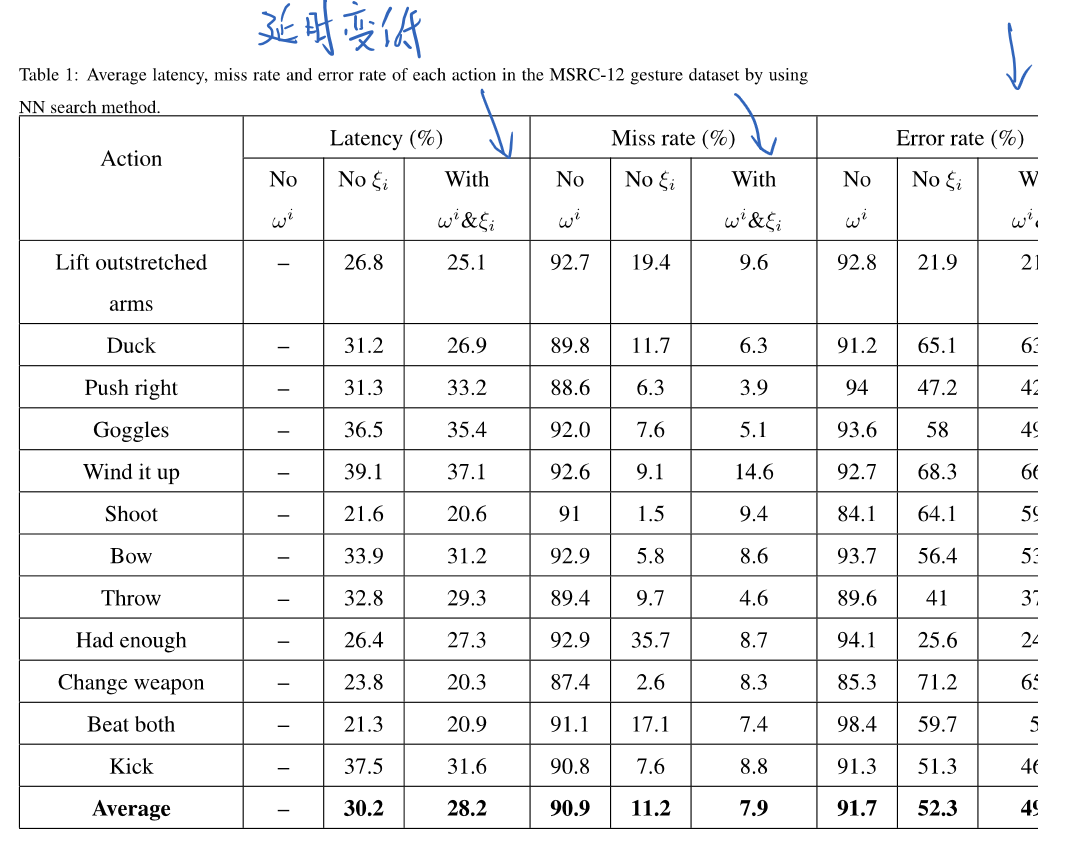
展示了在三个数据集上面的结果:



最后一种数据集,是卧龙岗大学自己创造的,适合增量学习。
5The depth and skeleton data will be made available after the paper being accepted for publication at:
http://www.uow.edu.au/˜wanqing/#UOWActionDatasets
https://www.uow.edu.au/~wanqing/#UOWActionDatasets
最后讲解了使用的硬件情况:

以及对比,KNN和SVM的情况:

5.Conclusion
6.附录,
一些公式的证明和推导
代码实现:
201904Online Human Action Recognition Based on Incremental Learning of Weighted Covariance Descriptors的更多相关文章
- Object Detection / Human Action Recognition 项目
https://towardsdatascience.com/real-time-and-video-processing-object-detection-using-tensorflow-open ...
- 201904:Action recognition based on 2D skeletons extracted from RGB videos
论文标题:Action recognition based on 2D skeletons extracted from RGB videos 发表时间:02 April 2019 解决问题/主要思想 ...
- 基于3D卷积神经网络的行为识别:3D Convolutional Neural Networks for Human Action Recognition
简介: 这是一片发表在TPAMI上的文章,可以看见作者有余凯(是百度的那个余凯吗?) 本文提出了一种3D神经网络:通过在神经网络的输入中增加时间这个维度(连续帧),赋予神经网络行为识别的功能. 相应提 ...
- 行为识别(action recognition)相关资料
转自:http://blog.csdn.net/kezunhai/article/details/50176209 ================华丽分割线=================这部分来 ...
- Recent papers on Action Recognition | 行为识别最新论文
CVPR2019 1.An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognit ...
- 【计算机视觉】行为识别(action recognition)相关资料
================华丽分割线=================这部分来自知乎==================== 链接:http://www.zhihu.com/question/3 ...
- 【论文笔记】Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition 2018-01-28 15:4 ...
- Survey of single-target visual tracking methods based on online learning 翻译
基于在线学习的单目标跟踪算法调研 摘要 视觉跟踪在计算机视觉和机器人学领域是一个流行和有挑战的话题.由于多种场景下出现的目标外貌和复杂环境变量的改变,先进的跟踪框架就有必要采用在线学习的原理.本论文简 ...
- 论文列表 for Action recognition
要读的论文: https://www.cnblogs.com/hizhaolei/p/10565405.html 骨架动作识别论文汇总 https://blog.csdn.net/bianxuewei ...
随机推荐
- Ajax实现的城市二级联动三
把之前2篇整合在一起 1.html <select id="province"> <option>请选择</option> </selec ...
- AOP,过滤器,监听器,拦截器【转载】
面向切面编程(AOP是Aspect Oriented Program的首字母缩写) ,我们知道,面向对象的特点是继承.多态和封装.而封装就要求将功能分散到不同的对象中去,这在软件设计中往往称为职责分配 ...
- HDU2196(SummerTrainingDay13-D tree dp)
Computer Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Su ...
- css实现照片上传的加号框
css实现照片上传的加号框
- Docker 镜像运行时区不准确处理
启动 tomcat 容器时发现容器时间与本地时间不一致,相差 8 个小时 docker run -d --rm -p 8888:8080 tomcat:latest # 查看容器 ID docker ...
- 对GIL的一些理解
GIL:全局解释器锁 GIL设计理念与限制: python的代码执行由python虚拟机(也叫解释器主循环,CPython版本)来控制,python在设计之初就考虑到在解释器的主循环中,同时只有一个线 ...
- 【读书笔记】iOS-使用蓝牙
蓝牙是由Sony Ericsso公司研发出来的,它是一种无线通讯协议,主要用于短程和低耗电设备,其有效通讯范围约30ft,传输速度为1MB/s.与Wifi设计初衷不同,蓝牙适用于无线的外围设备,进行小 ...
- CSS盒模型的介绍
CSS盒模型的概念与分类 CSS盒模型就是一个盒子,封装周围的HTML元素,它包括内容content.边框border.内边距padding.外边距margin. CSS盒模型分为标准模型和 ...
- Windows下判断jdk是否安装好以及环境变量是否配置好
cmd下执行: 1.java 2.javac 3.where java 如果三个都没问题,说明安装成功&环境变量配置成功
- Angular2 富文本编辑器 ng2-ckeditor 的使用
本文介绍如何在 Angular 中使用 ng2-ckeditor 控件,示例代码基于 angular 6.0.2,node 8.11.2, ng2-ckeditor 4.9.2 环境 1. 安装 ...