Python/spss-多元回归建模-共线性诊断1(推荐A)
python风控建模实战lendingClub(博主录制,包含大量回归建模脚本,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源

在一个回归方程中,假如两个或两个以上解释变量彼此高度相关,那么回归分析的结果将有可能无法分清每一个变量与因变量之间的真实关系。例如我们要知道吸毒对SAT考试分数的影响,我们会询问对象是否吸收过可卡因或海洛因,并用软件计算它们之间的系数。
虽然求出了海洛因和可卡因额回归系数,但两者相关性发生重叠,使R平方变大,依然无法揭开真实的情况。
因为吸食海洛因的人常常吸食可卡因,单独吸食一种毒品人很少。
当两个变量高度相关时,我们通常在回归方程中只采用其中一个,或创造一个新的综合变量,如吸食可卡因或海洛因。
又例如当研究员想要控制学生的整体经济背景时,他们会将父母双方的受教育程度都纳入方程式中。
如果单独把父亲或母亲的教育程度分离考虑,会引起混淆,分析变得模糊,因为丈夫和妻子的教育程度有很大相关性。
多元共线性带来问题:
(1)自变量不显著
(2)参数估计值的正负号产生影响
共线性统计量:
(1)容忍度tolerance
tolerance<0.1 表示存在严重多重共线
(2)方差扩大因子 variance inflation factor (VIF)
VIF>10表示存在严重多重共线性
http://blog.csdn.net/baimafujinji/article/details/49799409
回归分析是数据挖掘中最基本的方法,其中基于普通最小二乘法的多元线性回归要求模型中的特征数据不能存在有多重共线性,否则模型的可信度将大打折扣。但是就是技术而言,如何确定模型中的各各特征之间是否有多重共线性呢?
先来看一组数据


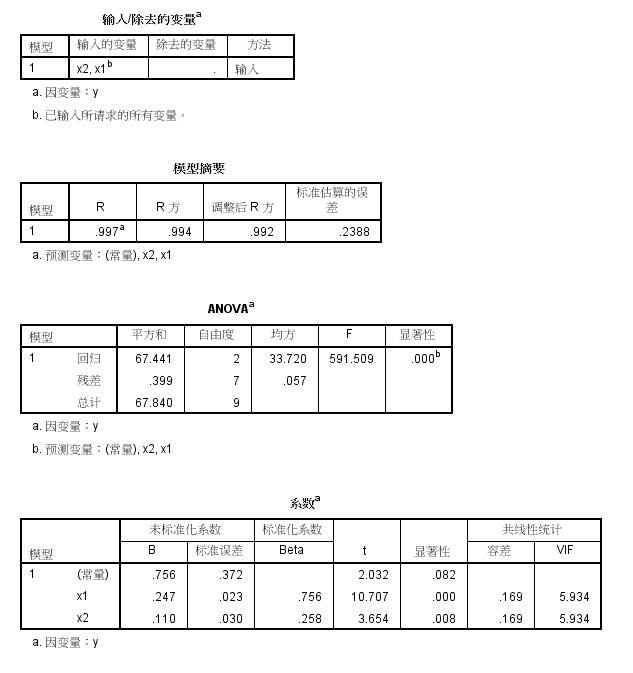
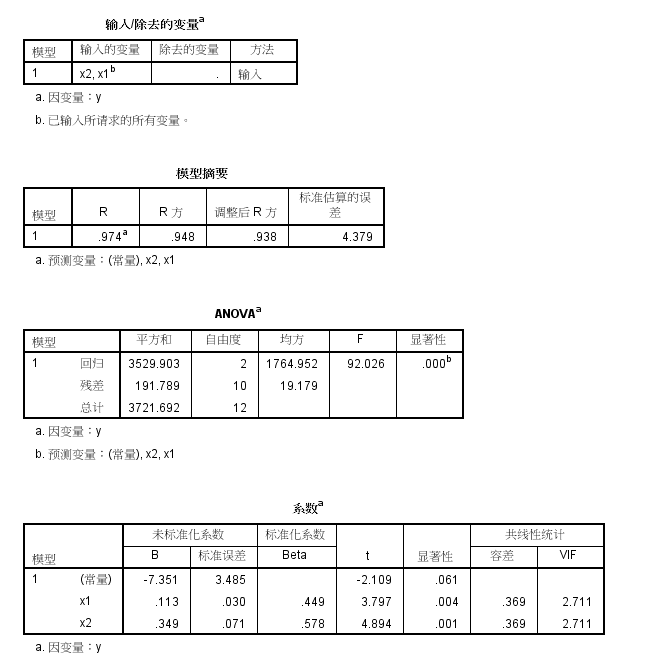
然后单击菜单栏上的【分析】->【回归】->【线性...】,则进入如下图所示的线性回归对话框。当选择好因变量和自变量之后,选择右上角的【Statistics...】,然后在弹出的新对话框里选定【共线性诊断】

红色框所标出的条件指数高达23.973(>10),可见共线性是确凿无疑的了!

python代码
# -*- coding: utf-8 -*-
"""
Created on Thu Feb 22 17:12:03 2018 @author: Administrator
"""
import pandas as pd
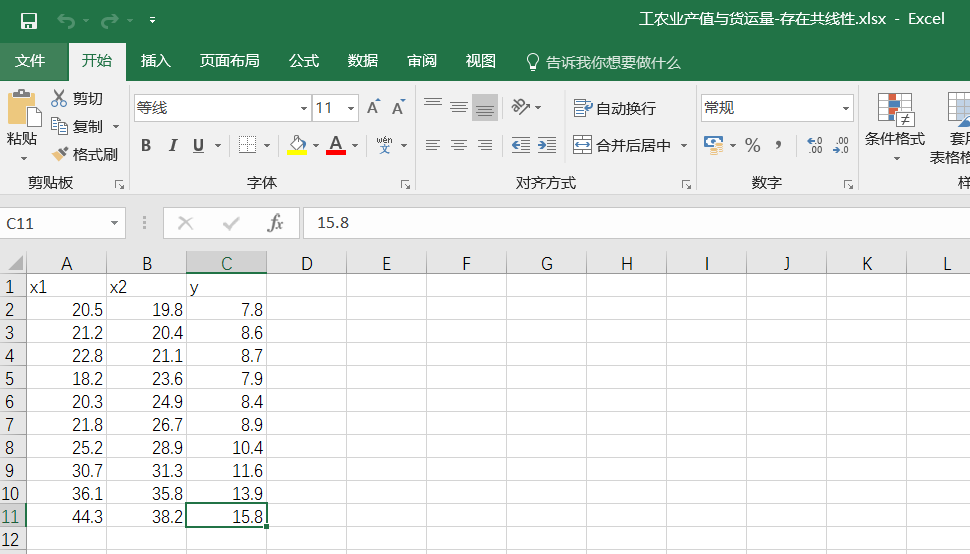
from statsmodels.formula.api import ols df=pd.read_excel("工农业产值与货运量-存在共线性.xlsx") #多元回归函数
def MulitiLinear_regressionModel(df):
'''Multilinear regression model, calculating fit, P-values, confidence intervals etc.'''
# --- >>> START stats <<< ---
# Fit the model
model = ols("y ~ x1 + x2", df).fit()
# Print the summary
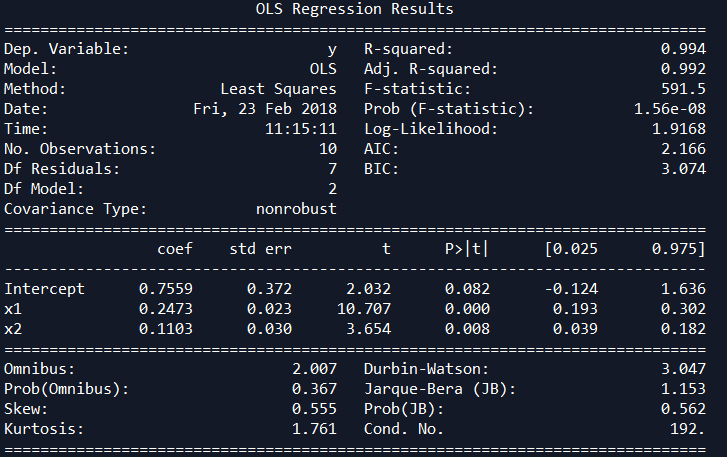
print((model.summary()))
# --- >>> STOP stats <<< ---
return model._results.params # should be array([-4.99754526, 3.00250049, -0.50514907]) MulitiLinear_regressionModel(df)
condition num=192
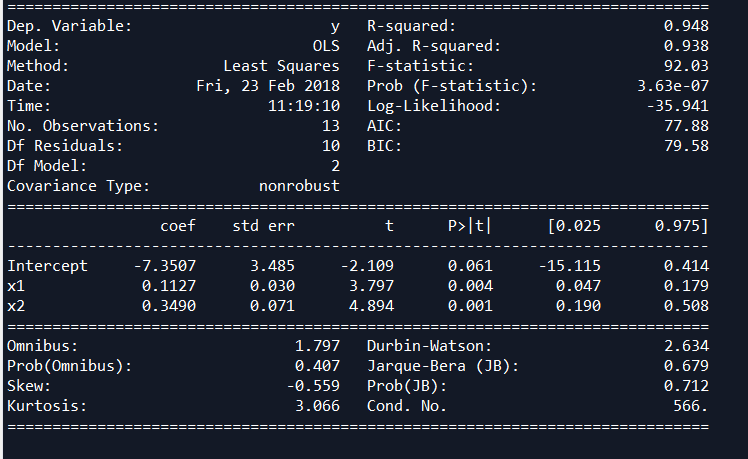
R **2 为0.992,和spss的结果一致
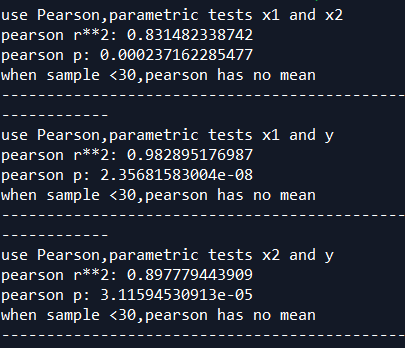
x1和x2, x1和y,x2和y的相关系数对比
# -*- coding: utf-8 -*-
"""
Created on Thu Feb 22 11:35:50 2018 @author: Administrator
"""
import pandas as pd
import scipy.stats as stats df=pd.read_excel("工农业产值与货运量-存在共线性.xlsx")
array_values=df.values
x1=[i[0] for i in array_values]
x2=[i[1] for i in array_values]
y=[i[2] for i in array_values]
sample=len(x1) print("use Pearson,parametric tests x1 and x2")
r,p=stats.pearsonr(x1,x2)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100) print("use Pearson,parametric tests x1 and y")
r,p=stats.pearsonr(x1,y)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100) print("use Pearson,parametric tests x2 and y")
r,p=stats.pearsonr(x2,y)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100)
程序结果:
x1和x2的R平方0.83,相关性强 -------暗示变量多重共线性问题
x1和y的R平方0.98,相关性强
x2和y的R平方0.897,相关性强
例子2

我们能否用这组数据来建立多元线性回归模型呢?同样再来绘制散点图如下,自变量之间似乎还是有点共线性,但是又不像上面例子中的那么明显,现在该怎么办?

所以我们还是建议采用一种更加能够便于量化的方法来描述问题的严重性,而不是仅仅通过肉眼观察来做感性的决定。下面我演示在SPSS 22中检验多重共线性的方法。首先导入数据,如下所示

然后单击菜单栏上的【分析】->【回归】->【线性...】,则进入如下图所示的线性回归对话框。当选择好因变量和自变量之后,选择右上角的【Statistics...】,然后在弹出的新对话框里选定【共线性诊断】
回到上图左边的对话框之后,选择确定,SPSS给出了线性回归分析的结果。我们来看其中共线性诊断的部分,如下所示,如果有条件指数>10,则表明有共线性。现在最大的是9.659,仍然处于可以接受的范围。

Python脚本
# -*- coding: utf-8 -*-
"""
Created on Thu Feb 22 17:12:03 2018 @author: Administrator
"""
import pandas as pd
from statsmodels.formula.api import ols df=pd.read_excel("土壤沉淀物吸收能力采样数据-不存在共线性.xlsx") #多元回归函数
def MulitiLinear_regressionModel(df):
'''Multilinear regression model, calculating fit, P-values, confidence intervals etc.'''
# --- >>> START stats <<< ---
# Fit the model
model = ols("y ~ x1 + x2", df).fit()
# Print the summary
print((model.summary()))
# --- >>> STOP stats <<< ---
return model._results.params # should be array([-4.99754526, 3.00250049, -0.50514907]) MulitiLinear_regressionModel(df)
condition num=566
R平方=0.948,和spss一样准确
x1和x2, x1和y,x2和y的相关系数对比
# -*- coding: utf-8 -*-
"""
Created on Thu Feb 22 11:35:50 2018 @author: Administrator
"""
import pandas as pd
import scipy.stats as stats df=pd.read_excel("土壤沉淀物吸收能力采样数据-不存在共线性.xlsx")
array_values=df.values
x1=[i[0] for i in array_values]
x2=[i[1] for i in array_values]
y=[i[2] for i in array_values]
sample=len(x1) print("use Pearson,parametric tests x1 and x2")
r,p=stats.pearsonr(x1,x2)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100) print("use Pearson,parametric tests x1 and y")
r,p=stats.pearsonr(x1,y)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100) print("use Pearson,parametric tests x2 and y")
r,p=stats.pearsonr(x2,y)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100)
程序结果:
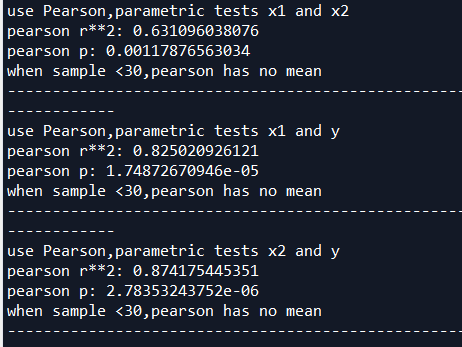
x1和x2的R平方0.63,相关性弱
x1和y的R平方0.825,相关性强
x2和y的R平方0.874,相关性强
案例
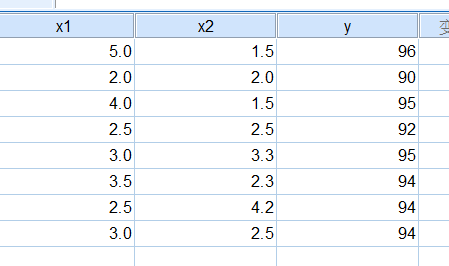
# -*- coding: utf-8 -*-
"""
Created on Thu Feb 22 11:35:50 2018 @author: Administrator
"""
import pandas as pd
import scipy.stats as stats df=pd.read_excel("两元回归测试.xlsx")
array_values=df.values
x1=[i[0] for i in array_values]
x2=[i[1] for i in array_values]
y=[i[2] for i in array_values]
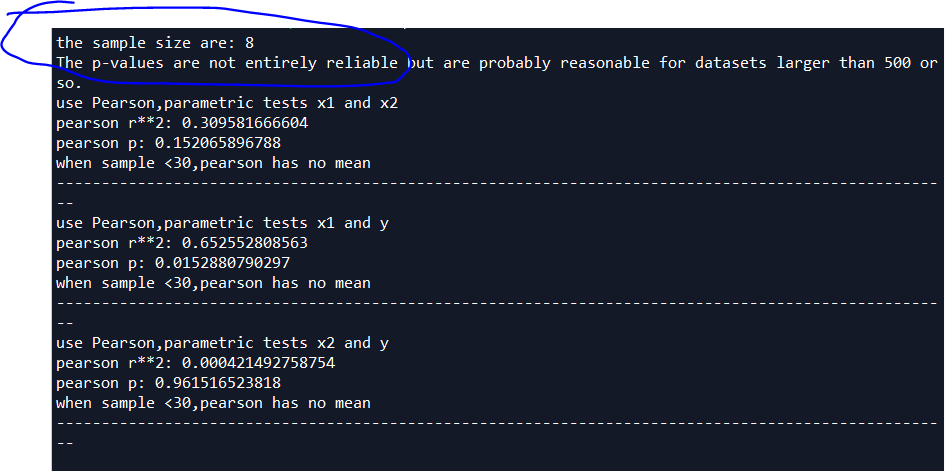
sample=len(x1) if sample<500:
print("the sample size are:",sample)
print("The p-values are not entirely reliable but are probably reasonable for datasets larger than 500 or so.")
print("use Pearson,parametric tests x1 and x2")
r,p=stats.pearsonr(x1,x2)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100) print("use Pearson,parametric tests x1 and y")
r,p=stats.pearsonr(x1,y)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100) print("use Pearson,parametric tests x2 and y")
r,p=stats.pearsonr(x2,y)
print("pearson r**2:",r**2)
print("pearson p:",p)
if sample<30:
print("when sample <30,pearson has no mean")
print("-"*100)
python信用评分卡建模(附代码,博主录制)

Python/spss-多元回归建模-共线性诊断1(推荐A)的更多相关文章
- Python/spss-多元回归建模-共线性诊断2(推荐AA)
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- python抓取51CTO博客的推荐博客的全部博文,对标题分词存入mongodb中
原文地址: python抓取51CTO博客的推荐博客的全部博文,对标题分词存入mongodb中
- 支持向量机SVM原理_python sklearn建模乳腺癌细胞分类器(推荐AAA)
项目合作联系QQ:231469242 sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?cours ...
- 优秀Python学习资源收集汇总(强烈推荐)
Python是一种面向对象.直译式计算机程序设计语言.它的语法简捷和清晰,尽量使用无异义的英语单词,与其它大多数程序设计语言使用大括号不一样,它使用縮进来定义语句块.与Scheme.Ruby.Perl ...
- Python 黑客相关电子资源和书籍推荐
原创 2017-06-03 玄魂工作室 玄魂工作室 继续上一次的Python编程入门的资源推荐,本次为大家推荐的是Python网络安全相关的资源和书籍. 在去年的双11送书的时候,其实送过几本Pyth ...
- 神经网络1_neuron network原理_python sklearn建模乳腺癌细胞分类器(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- 5款Python程序员高频使用开发工具推荐
很多Python学习者想必都会有如下感悟:最开始学习Python的时候,因为没有去探索好用的工具,吃了很多苦头.后来工作中深刻体会到,合理使用开发的工具的便利和高效.今天,我就把Python程序员使用 ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- Python实现性能自动化测试的方法【推荐好文】
1.什么是性能自动化测试? ◆ 性能 △ 系统负载能力 △ 超负荷运行下的稳定性 △ 系统瓶颈 ◆ 自动化测试 △ 使用程序代替手工 △ 提升测试效率 ◆ 性能自动化 △ 使用代码模拟大批量用户 △ ...
随机推荐
- HDOJ2010_水仙花数
一道水题.一直出现Output Limit Exceeded的原因是在while循环中没有终止条件的时候会自动判断并报错,写的时候忘记加!=EOF结束标识了. HDOJ2010_水仙花数 #inclu ...
- git学习笔记2——ProGit2
先附上教程--<ProGit 2> 配置信息 Git 自带一个 git config 的工具来帮助设置控制 Git 外观和行为的配置变量. 这些变量存储在三个不同的位置: /etc/git ...
- 传输层中的协议 TCP & UDP
面向连接的TCP协议 “面向连接”就是在正式通信前必须要与对方建立起连接.比如你给别人打电话,必须等线路接通了.对方拿起话筒才能相互通话.TCP(Transmission Control Protoc ...
- Oracle18c Exadata 版本安装介质安装失败。
下载下来的介质安装失败 白费一早上的功夫.. 一会儿问问云和恩墨的人呢.. INFO: [-- ::] Skipping line: 复制数据库文件 INFO: [-- ::] Skipping li ...
- 数据类型+内置方法 python学习第六天
元组 用途:不可变的列表,能存多个值,但多个值只有取的需求而没有改的需求. 定义方式:在()内用逗号分隔开多个元素,可以存放任意类型的值. names=(‘alex’,’blex’,’clex’) 强 ...
- Sql保留两位小数方法
2.176544保留两位小数 1.select Convert(decimal(18,2),2.176544) 结果:2.18 2.select Round(2.176544,2) 结果:2.180 ...
- Java之相对路径找不到文件问题解决方法
1.问题: 在程序需要通过相对路径引用文件,使用Junit可以正常执行,但是直接使用main方法找不到对应问题. 2.分析: 因为不同运行方式所使用的环境变量中的用户工作目录不同所致. 3.解决: 修 ...
- BZOJ4502串——AC自动机(fail树)
题目描述 兔子们在玩字符串的游戏.首先,它们拿出了一个字符串集合S,然后它们定义一个字 符串为“好”的,当且仅当它可以被分成非空的两段,其中每一段都是字符串集合S中某个字符串的前缀. 比如对于字符串集 ...
- LOJ121 动态图连通性(LCT)
用LCT维护一下删除时间的最大生成树即可.当然也可以线段树分治. #include<iostream> #include<cstdio> #include<cmath&g ...
- python 解释器交互模块 -- sys
sys模块是与python解释器交互的一个接口 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.getdefaultencoding(): 获取系统当前编码,一般默认为asci ...