[01-01] 示例:用Java爬取新闻
1、分析url
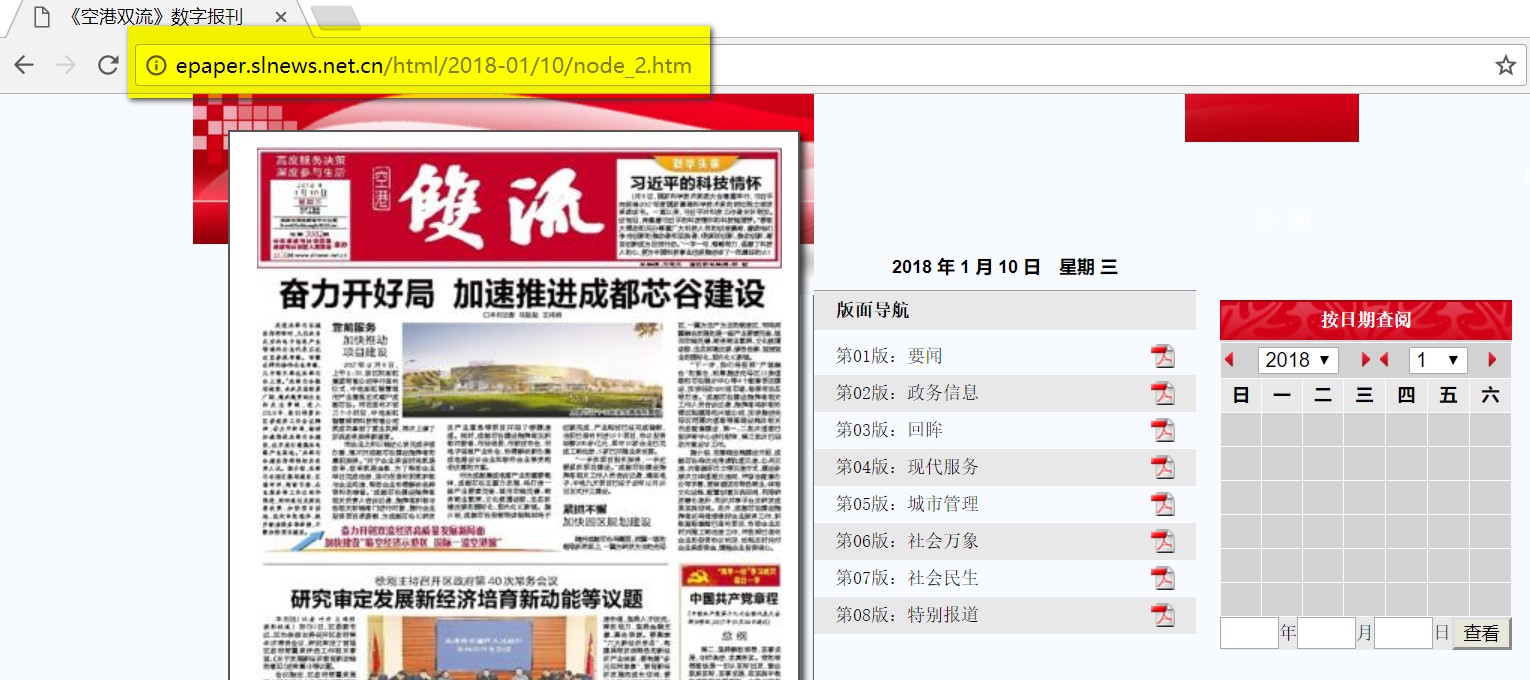
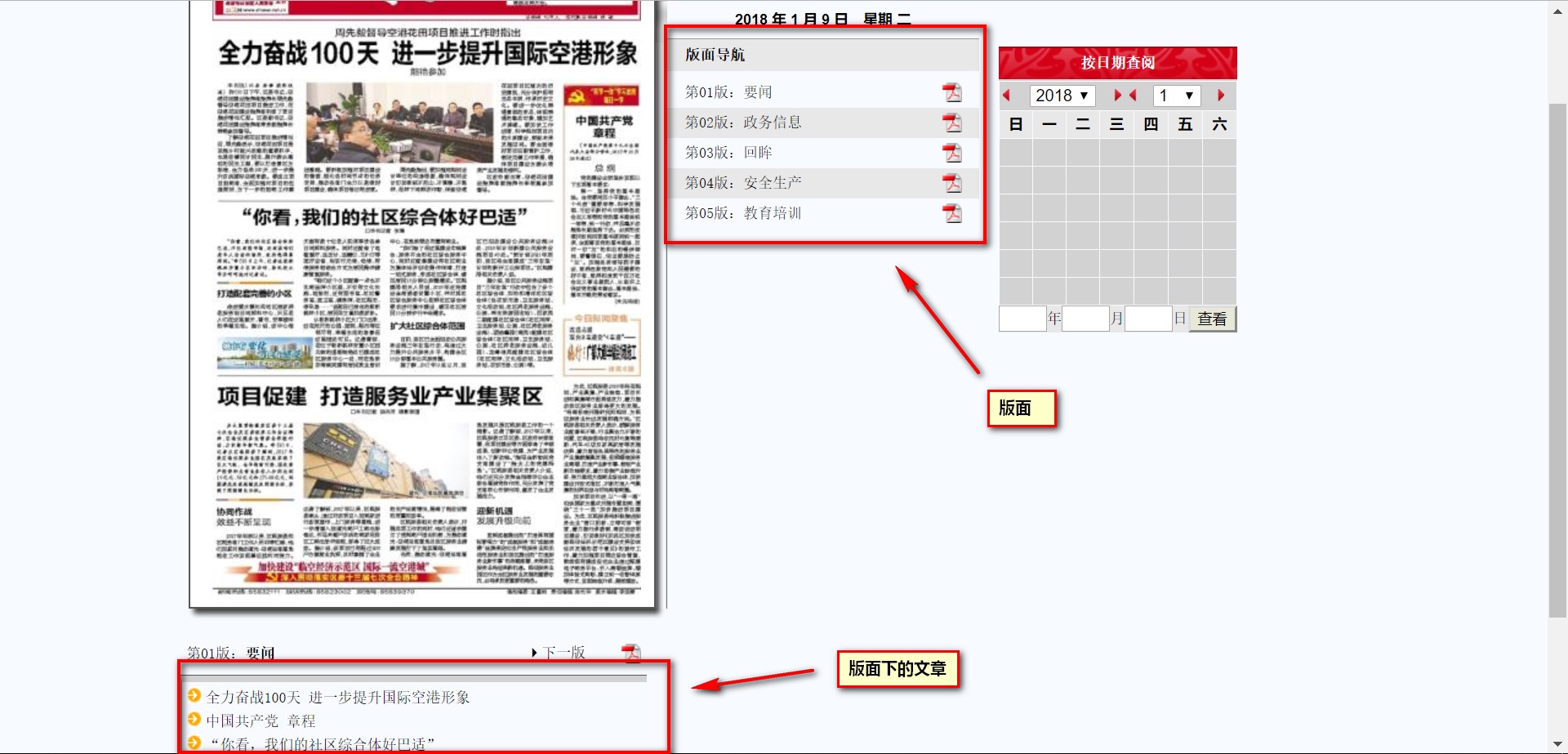
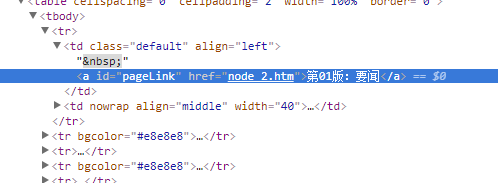

- 先得到所有版面的url
- 访问版面网页并抓取其中的所有文章的url
- 最后访问文章url就可以得到新闻网页内容了
2、代码部分
public class CrawlerUtil {
/**
* 获取主网页的内容
*
* @param url 网页url
* @param requestMethod 请求方式
* @param refer post内容
* @return 网页内容
*/
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {
refer = refer == null || "".equals(refer) ? null : refer;
StringBuffer buffer = new StringBuffer();
try {
//建立连接
URL requestUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();
connection.setRequestMethod(requestMethod.getValue());
switch (requestMethod) {
case GET:
connection.connect();
break;
case POST:
if (refer != null) {
OutputStream out = connection.getOutputStream();
out.write((refer.getBytes("UTF-8")));
out.close();
}
break;
default:
break;
}
//获取网页内容
InputStream in = connection.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
//关闭资源
bufferedReader.close();
inputStreamReader.close();
in.close();
in = null;
connection.disconnect();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
}public class CrawlerUtil {
/**
* 获取主网页的内容
*
* @param url 网页url
* @param requestMethod 请求方式
* @param refer post内容
* @return 网页内容
*/
public static String sendHttpRequest(String url, RequestMethod requestMethod, String refer) {
refer = refer == null || "".equals(refer) ? null : refer;
StringBuffer buffer = new StringBuffer();
try {
//建立连接
URL requestUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) requestUrl.openConnection();
connection.setRequestMethod(requestMethod.getValue());
switch (requestMethod) {
case GET:
connection.connect();
break;
case POST:
if (refer != null) {
OutputStream out = connection.getOutputStream();
out.write((refer.getBytes("UTF-8")));
out.close();
}
break;
default:
break;
}
//获取网页内容
InputStream in = connection.getInputStream();
InputStreamReader inputStreamReader = new InputStreamReader(in, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
//关闭资源
bufferedReader.close();
inputStreamReader.close();
in.close();
in = null;
connection.disconnect();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
}
/**
* 双流新闻网地址
*/
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";
/**
* 获取特定日期的新闻网的版面地址url
* <p>
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_2
* </p>
*
* @param date 日期
* @param factor 板面,形式为node_?
* 文章,形式为content_?
* @return 新闻网地址url
*/
public static String takePageUrl(Date date, String factor) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");
factor = factor == null ? "node_2" : factor;
return String.format(NEWS_URL, format.format(date), factor);
}/**
* 双流新闻网地址
*/
private static final String NEWS_URL = "http://epaper.slnews.net.cn/html/%s/%s.htm";
/**
* 获取特定日期的新闻网的版面地址url
* <p>
* 默认不填写factor参数的话,则url为第一版面链接,填入factor值node_2
* </p>
*
* @param date 日期
* @param factor 板面,形式为node_?
* 文章,形式为content_?
* @return 新闻网地址url
*/
public static String takePageUrl(Date date, String factor) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM/dd");
factor = factor == null ? "node_2" : factor;
return String.format(NEWS_URL, format.format(date), factor);
}
/**
* 获取内容匹配的元素集合
*
* @param content 网页内容
* @param reg 匹配正则
* @return 元素集合
*/
private static List<String> takeElementList(String content, String reg) {
log.debug("start take elements from content by Reg");
List<String> list = new ArrayList<String>();
//定义正则规则
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String element = matcher.group(1);
list.add(element);
log.debug(element);
}
log.debug("take elements end");
return list;
}/**
* 获取内容匹配的元素集合
*
* @param content 网页内容
* @param reg 匹配正则
* @return 元素集合
*/
private static List<String> takeElementList(String content, String reg) {
log.debug("start take elements from content by Reg");
List<String> list = new ArrayList<String>();
//定义正则规则
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String element = matcher.group(1);
list.add(element);
log.debug(element);
}
log.debug("take elements end");
return list;
}
/**
* 获取特定日期新闻网的版面链接元素
*
* @param date 日期
* @return 版面链接的元素集合
*/
public static List<String> takeNodeUrlEleList(Date date) {
String url = takePageUrl(date, null);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a id=pageLink href=.*?(node_\\d+?)\\.htm>.*?<\\/a>";
return takeElementList(content, reg);
}
/**
* 获取指定日期指定版面的所有文章链接元素集合
*
* @param date 日期
* @param node 版面元素,格式为node_?
* @return 文章链接的元素集合
*/
public static List<String> takeNewsUrlEleList(Date date, String node) {
String url = takePageUrl(date, node);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a href=.*?(content_\\d+?)\\.htm>";
return takeElementList(content, reg);
}/**
* 获取特定日期新闻网的版面链接元素
*
* @param date 日期
* @return 版面链接的元素集合
*/
public static List<String> takeNodeUrlEleList(Date date) {
String url = takePageUrl(date, null);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a id=pageLink href=.*?(node_\\d+?)\\.htm>.*?<\\/a>";
return takeElementList(content, reg);
}
/**
* 获取指定日期指定版面的所有文章链接元素集合
*
* @param date 日期
* @param node 版面元素,格式为node_?
* @return 文章链接的元素集合
*/
public static List<String> takeNewsUrlEleList(Date date, String node) {
String url = takePageUrl(date, node);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
String reg = "<a href=.*?(content_\\d+?)\\.htm>";
return takeElementList(content, reg);
}
/**
* 抓取指定日期新闻页面内容集合
*
* @param date 日期
* @return 新闻页面内容
*/
public static List<String> takeNewsPageList(Date date) {
log.info("start crawl news page content. date:" + date);
List<String> newsList = new ArrayList<String>();
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);
for (String nodeEle : nodeEleList) {
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);
for (String newsEle : newsEleList) {
String url = NewsCrawler.takePageUrl(date, newsEle);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
newsList.add(content);
}
}
log.info("crawl news page content end. page amount:" + newsList.size());
return newsList;
}/**
* 抓取指定日期新闻页面内容集合
*
* @param date 日期
* @return 新闻页面内容
*/
public static List<String> takeNewsPageList(Date date) {
log.info("start crawl news page content. date:" + date);
List<String> newsList = new ArrayList<String>();
List<String> nodeEleList = NewsCrawler.takeNodeUrlEleList(date);
for (String nodeEle : nodeEleList) {
List<String> newsEleList = NewsCrawler.takeNewsUrlEleList(date, nodeEle);
for (String newsEle : newsEleList) {
String url = NewsCrawler.takePageUrl(date, newsEle);
String content = CrawlerUtil.sendHttpRequest(url, RequestMethod.GET, null);
newsList.add(content);
}
}
log.info("crawl news page content end. page amount:" + newsList.size());
return newsList;
}
[01-01] 示例:用Java爬取新闻的更多相关文章
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- MinerConfig.java 爬取配置类
MinerConfig.java 爬取配置类 package com.iteye.injavawetrust.miner; import java.util.List; /** * 爬取配置类 * @ ...
- Java爬取网络博客文章
前言 近期本人在某云上购买了个人域名,本想着以后购买与服务器搭建自己的个人网站,由于需要筹备的太多,暂时先搁置了,想着先借用GitHub Pages搭建一个静态的站,搭建的过程其实也曲折,主要是域名地 ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- java爬取网页内容 简单例子(2)——附jsoup的select用法详解
[背景] 在上一篇博文java爬取网页内容 简单例子(1)——使用正则表达式 里面,介绍了如何使用正则表达式去解析网页的内容,虽然该正则表达式比较通用,但繁琐,代码量多,现实中想要想出一条简单的正则表 ...
- java爬取并下载酷狗TOP500歌曲
是这样的,之前买车送的垃圾记录仪不能用了,这两天狠心买了好点的记录仪,带导航.音乐.蓝牙.4G等功能,寻思,既然有这些功能就利用起来,用4G听歌有点奢侈,就准备去酷狗下点歌听,居然都是需要办会员才能下 ...
- Java爬取并下载酷狗音乐
本文方法及代码仅供学习,仅供学习. 案例: 下载酷狗TOP500歌曲,代码用到的代码库包含:Jsoup.HttpClient.fastJson等. 正文: 1.分析是否可以获取到TOP500歌单 打开 ...
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
随机推荐
- CSS之fontAwesome代替网页icon小图标
引言 奥森图标(Font Awesome)提供丰富的矢量字体图标—通过CSS可以任意控制所有图标的大小 ,颜色,阴影. 网页小图标到处可见,如果一个网页都是干巴巴的文字和图片,而没有小图标,会显得非常 ...
- 【代码笔记】Web-利用Dreamweaver实现form
一,打开Dreamweaver---->File---New---->如下图所示.选择HTML,点击OK. 二,会出现如下图所示界面.把光标放到Body处. 三,将上面的栏切换到Desig ...
- 基于angular2x+ng-bootstrap构建后台管理系统界面
写在前面的话 近来公司要做一个后台管理系统,人手比较少,于是作为一个前端也参与进来,其实据我所知,大部分的公司还是后台自己捣鼓的. 在后台没有到位的情况下,前端应该使用什么技术也着实让我为难了一把.经 ...
- 自定义控件详解(三):Canvas效果变换
Canvas 画布 从前面我们已经知道了 Canvas 类可以绘出 各种形状. 这里学习一下Canvas 类的变换效果(平移,旋转等) 首先需要了解一下Canvas 画布, 我们用Canvas.Dra ...
- 通过url动态获取图片大小方法总结
很多时候再项目中,我们往往需要先获取图片的大小再加载图片,但是某些特定场景,如用过cocos2d-js的人都知道,在它那里只能按比例缩放大小,是无法设置指定大小的图片的,这就是cocos2d-js 的 ...
- [20171227]表的FULL_HASH_VALUE值的计算.txt
[20171227]表的FULL_HASH_VALUE值的计算.txt --//sql_id的计算是使用MD5算法进行哈希,生成一个128位的Hash Value,其中低32位作为HASH VALUE ...
- MySql数据库基础笔记(一)
一.表与库的概念 数据库管理数据,它是以什么样的形式组成的? 生活中的表---->表 table多行多列,传统的数据库都是这样的;声明了表头,一个表创建好了,剩下的就是往表中添加数据 多张表放在 ...
- 3.2Python数据处理篇之Numpy系列(二)--- ndarray数组的创建与变换
目录 (一)ndarray数组的创建 1.从列表以元组中创建: 2.使用函数创建: (二)ndarray数组的变换 1.维度的变换: 2.类型的变换: 目录: 1.ndarray数组的创建 2.nda ...
- VRS的GPS/BDS双系统网元固定存在的问题
问题如下:部分网元固定卫星数少于2个. 另外:北方xinkong的网元组网也存在问题
- Java设计模式之四 ----- 适配器模式和桥接模式
前言 在上一篇中我们学习了创建型模式的建造者模式和原型模式.本篇则来学习下结构型模式的适配器模式和桥接模式. 适配器模式 简介 适配器模式是作为两个不兼容的接口之间的桥梁.这种类型的设计模式属于结构型 ...