hadoop学习笔记(八):MapReduce
一、MapReduce编程模型
一种分布式计算框架,解决海量数据的计算问题。
MapReduce将整个并行计算过程抽象到两个函数:
Map(映射):对一些独立元素组成的列表的每一个元素进行制定的操作,可以高度并行。
Reduce(化简):对一个列表的元素进行合并。
一个简单的MapReduce程序只需要指定Map()、reduce()、input和output,剩下的事情由框架完成。
二、Map过程(以wordcount为例):
1 一行一行读,每一行都解析成key/value形式。每一个键值对,都调用一次Map函数。
假设有一个文件的内容是:
hello hadoop!
hello world!
那么Map的读取过程为:
| key | value | operate |
| 0 | hello hadoop! | --> hello:1 hadoop!:1 |
| 13 | hello world! | --> hello:1 world!:1 |
2 写自己的逻辑,对输入的key/value处理,转换成新的key/value输出。
| key | value |
| hello | 1 |
| hadoop! | 1 |
| hello | 1 |
| world! | 1 |
3 对输出的key/value进行分区。
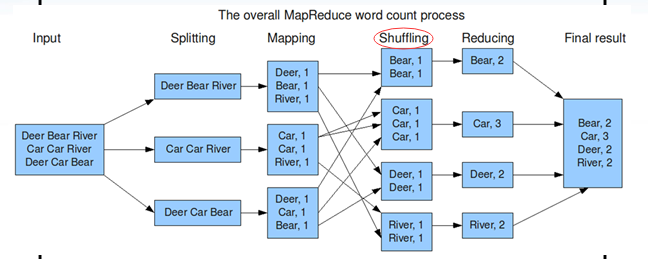
注意:Shuffling囊括了:partition和sort。
4 对不同分区的数据,按照key进行排序、分组。把相同的key的value放到一个集合中。
| key | list<value> |
| hello | 2 |
| hadoop! | 1 |
| world! | 1 |
5 (可选)分组后的数据进行归约。
三、Reduce过程:
1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key/value处理,转换成新的key/value输出。
3 把reduce的输出保存到文件中。
hadoop学习笔记(八):MapReduce的更多相关文章
- hadoop 学习笔记:mapreduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- Hadoop学习笔记:MapReduce框架详解
开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- 【Big Data - Hadoop - MapReduce】hadoop 学习笔记:MapReduce框架详解
开始聊MapReduce,MapReduce是Hadoop的计算框架,我学Hadoop是从Hive开始入手,再到hdfs,当我学习hdfs时候,就感觉到hdfs和mapreduce关系的紧密.这个可能 ...
- hadoop 学习笔记:mapreduce框架详解(转)
原文:http://www.cnblogs.com/sharpxiajun/p/3151395.html(有删减) Mapreduce运行机制 下面我贴出几张图,这些图都是我在百度图片里找到的比较好的 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop学习笔记—12.MapReduce中的常见算法
一.MapReduce中有哪些常见算法 (1)经典之王:单词计数 这个是MapReduce的经典案例,经典的不能再经典了! (2)数据去重 "数据去重"主要是为了掌握和利用并行化思 ...
- Hadoop学习笔记: MapReduce二次排序
本文给出一个实现MapReduce二次排序的例子 package SortTest; import java.io.DataInput; import java.io.DataOutput; impo ...
- Hadoop学习笔记: MapReduce Java编程简介
概述 本文主要基于Hadoop 1.0.0后推出的新Java API为例介绍MapReduce的Java编程模型.新旧API主要区别在于新API(org.apache.hadoop.mapreduce ...
- 三、Hadoop学习笔记————从MapReduce到Yarn
Yarn减轻了JobTracker的负担,对其进行了解耦
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- js插件开发的一些感想和心得
起因 如果大家平时做过一些前端开发方面的工作,一定会有这样的体会:页面需要某种效果或者插件的时候,我们一般会有两种选择:1.上网查找相关的JS插件,学习其用法2.自己造轮子,开发插件. 寻找存在的插件 ...
- clob 转 String
import javax.sql.rowset.serial.SerialClob; import java.io.BufferedReader; import java.io.IOException ...
- 修改jenkins启动的默认用户
# 背景 通过yum命令安装的jenkins,通过service jenkins去启动jenkins的话,默认的用户是jenkins,但jenkins这个用户是无法通过su切换过去的 ,在某些环节可能 ...
- asp.net mvc5 分析器错误消息: 未能加载类型“XXX.MvcApplication”
描述 今天忽然碰到一个这个错误: “/”应用程序中的服务器错误. 分析器错误 说明: 在分析向此请求提供服务所需资源时出错.请检查下列特定分析错误详细信息并适当地修改源文件. 分析器错误消息: 未能加 ...
- BitAdminCore框架更新日志20180523
20180523更新内容 本次更新两个内容,一是增加视频处理功能,二是增加定时服务功能. 视频处理 定时服务 BitAdminCore框架,用最少的代码,实现最多的功能 本次新暂未发布,后续有空发布 ...
- phpmailer SMTP Error: Could not connect to SMTP host. 错误解决
今天发邮件遇到了这么一个问题:SMTP Error: Could not connect to SMTP host.在网上找了好多,都不管用.在这里我要提醒大家下 1.确保发送者邮箱密码正确,代码编写 ...
- Visual Studio 编译信息细度显示设置
visual studio 项目在编译时,可根据调试需要设置output窗口输出内容的详细程度,这对于bug或warning的解决具有很大帮助.具体设置如下: 依次点击:"Tools&quo ...
- day 59 pymysql
PyMySQL介绍 PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb. PYmysql安装 pip install pymys ...
- poj1122
FDNY to the Rescue! Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 2917 Accepted: 89 ...
- mysql编写存储过程(1)
存储过程:其实就是存储在数据库中,有一些逻辑语句与SQL语句组成的函数.由于是已经编译好的语句,所以执行速度快,而且也安全. 打开mysql的控制台,开始编写存储过程. 实例1: 编写存储过程: 执行 ...