[转]Hadoop 读写数据流
Hadoop文件读取
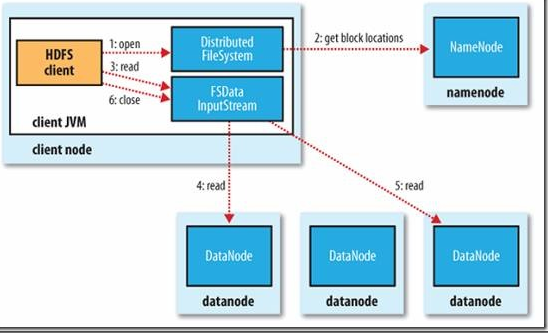
1)客户端通过调用FileSystem对象中的open()函数来读取它做需要的数据。FileSystem是HDFS中DistributedFileSystem的一个实例。
2)DistributedFileSystem会通过RPC协议调用NameNode来确定请求文件块所在的位置。
这里需要注意的是,NameNode只会返回所调用文件中开始的几个块而不是全部返回。对于每个返回的块,都包含块所在的DataNode地址。随后,这些返回的DataNode会按照Hadoop定义的集群拓扑结构得出客户端的距离,然后再进行排序。如果客户端本身就是一个DataNode,那么它就从本地读取文件。其次,DistributedFileSystem会向客户端返回一个支持文件定位的输入流对象FSDataInputStream,用于给客户端读取数据。FSDataInputStream包含一个DFSInputStream对象,这个对象用来管理DataNode和NameNode之间的IO。
3)当以上步骤完成时,客户端便会在这个输入流上调用read()函数。
4)DFSInputStream对象中包含文件开始部分数据块所在的DataNode地址,首先它会连接文件第一个块最近的DataNode。随后,在数据流中重复调用read()函数,直到这个块完全读完为止。
5)当第一个块读取完毕时,DFSInputStream会关闭连接,并查找存储下一个数据库距离客户端最近的DataNode。以上这些步骤对于客户端来说都是透明的。
6)客户端按照DFSInputStream打开和DataNode连接返回的数据流的顺序读取该块,它也会调用NameNode来检索下一组块所在的DataNode的位置信息。当完成所有文件的读取时,客户端则会在DFSInputStream中调用close()函数。
那么如果客户端正在读取数据时节点出现故障HDFS会怎么办呢?目前HDFS是这样处理的:如果客户端和所连接的DataNode在读取时出现故障,那么它就会去尝试连接存储这个块的下一个最近的DataNode,同时它会记录这个节点的故障,以免后面再次连接该节点。客户端还会验证从DataNode传送过来的数据校验和。如果发现一个损坏块,那么客户端将再尝试从别的DataNode读取数据块,向NameNode报告这个信息,NameNode也会更新保存的文件信息。
这里关注的一个设计要点是,客户端通过NameNode引导获取最合适的DataNode地址,然后直接连接DataNode读取数据。这样设计的好处在于,可以使HDFS扩展到更大规模的客户端并行处理,这是因为数据的流动是在所有DataNode之间分散进行的;同时NameNode的压力也变小了,使得NameNode只用提供请求块所在的位置信息就可以了,而不用通过它提供数据,这样就避免了NameNode随着客户端数量的增长而成为系统瓶颈。
Hadoop文件写入
Highlight:DataNode中的副本是异步完成的

1)客户端通过调用DistributedFileSystem对象中的create()函数创建一个文件。DistributedFileSystem通过RPC调用在NameNode的文件系统命名空间中创建一个新文件,此时还没有相关的DataNode与之相关。
2)NameNode会通过多种验证保证新的文件不存在文件系统中,并且确保请求客户端拥有创建文件的权限。当所有验证通过时,NameNode会创建一个新文件的记录,如果创建失败,则抛出一个IOException异常;如果成功,则DistributedFileSystem返回一个FSDataOutputStream给客户端用来写入数据。这里FSDataOutputStream和读取数据时的FSDataOutputStream一样都包含一个数据流对象DFSOutputStream,客户端将使用它来处理和DataNode及NameNode之间的通信。
3)当客户端写入数据时,DFSOutputStream会将文件分割成包,然后放入一个内部队列,我们称为“数据队列”。DataStreamer会将这些小的文件包放入数据流中,DataStreamer的作用是请求NameNode为新的文件包分配合适的DataNode存放副本。返回的DataNode列表形成一个“管道”,假设这里的副本数是3,那么这个管道中就会有3个DataNode。DataStreamer将文件包以流的方式传送给队列中的第一个DataNode。第一个DataNode会存储这个包,然后将它推送到第二个DataNode中,随后照这样进行,直到管道中的最后一个DataNode。
4)DFSOutputStream同时也会保存一个包的内部队列,用来等待管道中的DataNode返回确认信息,这个队列被称为确认队列(ask queue)。只有当所有的管道中的DataNode都返回了写入成功的信息文件包,才会从确认队列中删除。
当然HDFS会考虑写入失败的情况,当数据写入节点失败时,HDFS会作出以下反应.首先管道会被关闭,任何在确认通知队列中的文件包都会被添加到数据队列的前端,这样管道中失败的DataNode都不会丢失数据。当前存放于正常工作DataNode之上的文件块会被赋予一个新的身份,并且和NameNode进行关联,这样,如果失败的DataNode过段时间从故障中恢复过来,其中的部分数据块就会被删除。然后管道会把失败的DataNode删除,文件会继续被写到管道中的另外两个DataNode中。最后NameNode会注意到现在的文件块副本数没有到达配置属性要求,会在另外的DataNode上重新安排创建一个副本。随后的文件会正常执行写入操作。
当然,在文件块写入期间,多个DataNode同时出现故障的可能性存在,但是很小。只要dfs.replication.min的属性值(默认为1)成功写入,这个文件块就会被异步复制到其他DataNode中,直到满足dfs.replictaion属性值(默认值为3)。
客户端成功完成数据写入的操作后,就会调用close()函数关闭数据流。这步操作会在连接NameNode确认文件写入完全之前将所有剩下的文件包放入DataNode管道,等待通知确认信息。NameNode会知道哪些块组成一个文件(通过DataStreamer获得块的位置信息),这样NameNode只要在返回成功标志前等待块被最小量(dfs.replication.min)复制即可。
参考文献:
《Hadoop实战》第9章 HDFS详解
[转]Hadoop 读写数据流的更多相关文章
- hdfs的读写数据流
hdfs的读: 首先客户端通过调用fileSystem对象中的open()函数读取他需要的的数据,fileSystem是DistributedFileSystem的一个实例, Distrib ...
- HDFS中的读写数据流
1.文件的读取 在客户端执行读取操作时,客户端和HDFS交互过程以及NameNode和各DataNode之间的数据流是怎样的?下面将围绕图1进行具体讲解. 图 1 客户端从HDFS中读取数据 1)客户 ...
- Hadoop读写mysql
需求 两张表,一张click表记录某广告某一天的点击量,另一张total_click表记录某广告的总点击量 建表 CREATE TABLE `click` ( `id` ) NOT NULL AUTO ...
- Hadoop读写流程
写流程 读流程 HDFS写数据流程 HDFS读数据流程 网络拓扑-节点距离计算 节点距离:两个节点到达最近的共同祖先的距离总和
- 大数据时代之hadoop(三):hadoop数据流(生命周期)
了解hadoop,首先就需要先了解hadoop的数据流,就像了解servlet的生命周期似的.hadoop是一个分布式存储(hdfs)和分布式计算框架(mapreduce),但是hadoop也有一个很 ...
- Hadoop集群(第8期)_HDFS初探之旅
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- 非常不错 Hadoop 的HDFS (Hadoop集群(第8期)_HDFS初探之旅)
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- 【转载 Hadoop&Spark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Go ...
- 大数据框架:Spark vs Hadoop vs Storm
大数据时代,TB级甚至PB级数据已经超过单机尺度的数据处理,分布式处理系统应运而生. 知识预热 「专治不明觉厉」之“大数据”: 大数据生态圈及其技术栈: 关于大数据的四大特征(4V) 海量的数据规模( ...
随机推荐
- Head First Python学习笔记2——文件与异常
文件处理 1.用open()就可以打开文件,但是请注意:文件里有中文请设置编码,如 :open("filepath","r",encoding="ut ...
- Python第三方库____jieba
jieba是优秀的中文分词第三方库 中文文本需要通过分词获得单个词语 jieba是优秀的中文分词第三方库,需要额外安装 (pip install jieba) jieba库提供三种分词模式,最简单只 ...
- C#中深拷贝和浅拷贝
一:概念 内存:用来存储程序信息的介质. 指针:指向一块内存区域,通过它可以访问该内存区域中储存的程序信息.(C#也是有指针的) 值类型:struct(整形.浮点型.decimal的内部实现都是str ...
- 三角形-->九九乘法表
使用嵌套循环打印九行*组成的三角形: * ** *** ...... *********(9个) public class Triangle { /** * 使用嵌套循环打印九行*组成的三角形 */ ...
- zookeeper 选举
选举概述: 1.启动时期的选举 所有的服务器状态为 LOOKING. 1.1.每个Server 会投出一票(投票规则为:SID.ZXID ,即 服务器ID 和 最大事务ID). 1.2.处理选票 (A ...
- mysql安装配置、主从复制配置详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/8213723.html 邮箱:moyi@moyib ...
- JavaScript-点击表格的表头进行排序
HTML如下: <table class="heroinfo"> <thead title="点击排序"> <tr> < ...
- 教程:RSS全文输出,自己动手做。(一)
这里以PHP版为例,尽量说得通俗点吧,水平实在有限,见谅. 目前我这里所有的获取全文输出的网站大概是三种情况: 要输出的内容集中在一页上,也就是看似列表页的页面里集中了你想要的所有内容,并不需要点击“ ...
- opencv3.2.0形态学滤波之膨胀
//名称:膨胀 //日期:12月21日 //平台:QT5.7.1+opencv3.2.0 /* 膨胀(dilate)的含义: 膨胀就是求局部最大值的操作,就是将图像(或图像的一部分,A)与核 B 进行 ...
- TCP报文发送工具
该工具用于向Socket服务端发送XML报文,软件功能界面如下图所示: 配置好IP和端口后,单击"载入报文文件"按钮,在文件选择对话框中选择报文文件,如图: 报文文件打开后,可在右 ...