hdfs的读写数据流
hdfs的读:
hdfs的读写数据流的更多相关文章
- HDFS 文件读写过程
HDFS 文件读写过程 HDFS 文件读取剖析 客户端通过调用FileSystem对象的open()来读取希望打开的文件.对于HDFS来说,这个对象是分布式文件系统的一个实例. Distributed ...
- hdfs api读写文写件个人练习
看下hdfs的读写原理,主要是打开FileSystem,获得InputStream or OutputStream: 那么主要用到的FileSystem类是一个实现了文件系统的抽象类,继承来自org. ...
- HDFS04 HDFS的读写流程
HDFS的读写流程(面试重点) 目录 HDFS的读写流程(面试重点) HDFS写数据流程 网络拓扑-节点距离计算 机架感知(副本存储节点的选择) HDFS的读数据流程 HDFS写数据流程 客服端把D: ...
- HDFS的读写流程——宏观与微观
HDFS的读写流程--宏观与微观 HDFS:分布式文件系统,负责存放数据 分布式文件系统:就是将我们的数据放到多台电脑上存储. 写数据:就是将客户端上的数据上传到HDFS 宏观过程 客户端向HDFS发 ...
- HDFS中的读写数据流
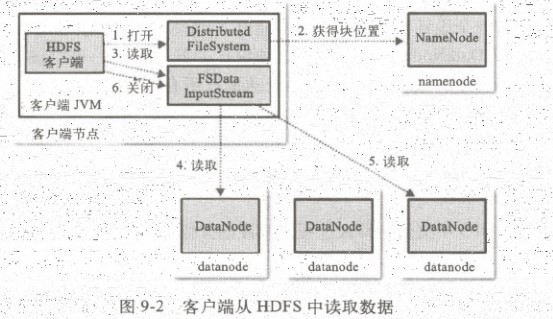
1.文件的读取 在客户端执行读取操作时,客户端和HDFS交互过程以及NameNode和各DataNode之间的数据流是怎样的?下面将围绕图1进行具体讲解. 图 1 客户端从HDFS中读取数据 1)客户 ...
- 【Hadoop】二、HDFS文件读写流程
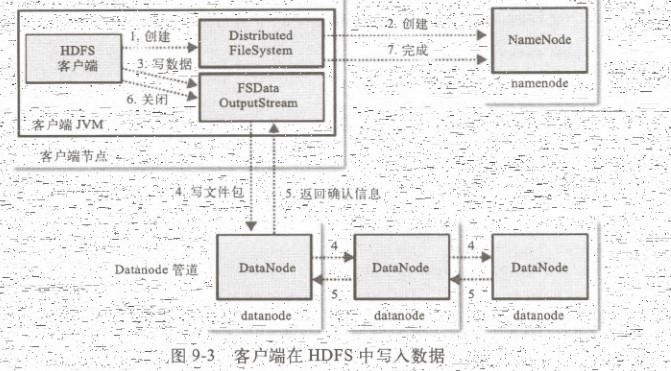
(二)HDFS数据流 作为一个文件系统,文件的读和写是最基本的需求,这一部分我们来了解客户端是如何与HDFS进行交互的,也就是客户端与HDFS,以及构成HDFS的两类节点(namenode和dat ...
- hadoop笔记-hdfs文件读写
概念 文件系统 磁盘进行读写的最小单位:数据块,文件系统构建于磁盘之上,文件系统的块大小是磁盘块的整数倍. 文件系统块一般为几千字节,磁盘块一般512字节. hdfs的block.pocket.chu ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- HDFS文件读写过程
参考自<Hadoop权威指南> [http://www.cnblogs.com/swanspouse/p/5137308.html] HDFS读文件过程: 客户端通过调用FileSyste ...
随机推荐
- 微信跳转浏览器来下载不同系统的app
在微信里面,是不能通过应用宝以外的方式去直接下载app的,但是却可以通过跳转到浏览器去下载app,因此如果刚好各位公司有刚刚上线的app,来不及放到微信应用宝那里,可以试试这种办法. 实现思路: 1. ...
- VB.net Wcf事件广播(订阅、发布)
这篇东西原写在csdn.net上,最近新开通了博客想把零散在各处的都转移到一处. 一.源起 学WCF有一段时间了,可是无论是微软的WebCast还是其他网上的教程,亦或我购买的几本书中,都没有怎么 ...
- [noip科普]关于LIS和一类可以用树状数组优化的DP
预备知识 DP(Dynamic Programming):一种以无后效性的状态转移为基础的算法,我们可以将其不严谨地先理解为递推.例如斐波那契数列的递推求法可以不严谨地认为是DP.当然DP的状态也可以 ...
- Alpha阶段发布说明
Alpha版本功能介绍 机器法官功能已实现 这是我们统计了当下所有存在的狼人APP的共同缺点.也是用户最主要的痛点.现在所有已知存在的类似APP都不能提供法官功能,我们的APP将该功能革命性的自动实现 ...
- php工厂方法
<?php interface db{ function conn(); } interface Factory{ function createDB(); } class dbmysql im ...
- 高版本api在低版本中的兼容
直接上例子,看如何避免crash. eg:根据给出路径,获取此路径所在分区的总空间大小. 文档说明:获取文件系统用量情况,在API level 9及其以上的系统,可直接调用File对象的相关方法,以下 ...
- linux 命令行 光标移动技巧
linux 命令行 光标移动技巧 看一个真正的专家操作命令行绝对是一种很好的体验-光标在单词之间来回穿梭,命令行不同的滚动.在这里强烈建立适应GUI节目的开发者尝试一下在提示符下面工作.但是事情也不是 ...
- Android 实现分页(使用TabWidget/TabHost)
注:本文为转载,但该内容本人已亲身尝试,确认该方法可行,代码有点小的改动,转载用作保存与分享. 原作者地址:http://gundumw100.iteye.com/blog/853967 个人吐嘈:据 ...
- (四)SQL Server分区管理
一.拆分分区(SPLIT) 在已有分区上添加一个新分区. 如下图所示,将分区03拆分成03和04分区,拆分方式先锁定旧03分区的所有数据,后将旧03分区相关数据迁移到分区04,最后删除旧03上的对应分 ...
- DTD总结
DTD 可以检测 XNM 文档的结构是否正确,就好像文章中用来保证结构正确的语法规则一样. 引入 DTD 1.引入私有的 DTD 文件,URI 可以使相对地址或绝对地址 <!DOCTYPE 根元 ...