Hadoop整理四(Hadoop分布式计算框架MapReduce)
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN是在MRv1基础上演化而来的,它克服了MRv1中的各种局限性。
扩展性差:在 MRv1 中,JobTracker 同时兼备了资源管理和作业控制两个功能,这成为系统的一个最大瓶颈,严重制约了 Hadoop 集群扩展性。
可靠性差:MRv1采用了master/slave结构,其中master存在单点故障问题,一旦它出现故障将导致整个集群不可用。
资源利用率低:MRv1采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源划分单位,通常一个任务不会用完槽位对应的资源,其他任务也无法使用这些空闲资源。此外,Hadoop将槽位分为Map Slot和Reduce Slot两种,且不允许它们之间共享, 常常会导致一种槽位资源紧张而另外一种闲置(比如一个作业刚刚提交时,只会运行Map Task,此时Reduce Slot闲置)。
无法支持多种计算框架:随着互联网高速发展,MapReduce这种基于磁盘的离线计算框架已经不能满足应用要求,从而出现了一些新的计算框架,包括内存计算框架、流式计算框架和迭代式计算框架等,而MRv1不能支持多种计算框架并存。
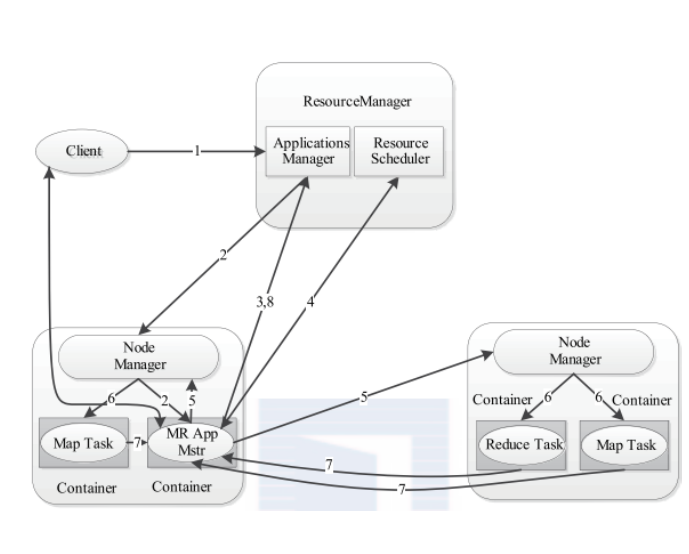
yarn的工作流程:
1.用户向YARN提交应用程序,其中包括ApplicationMaster程序,启动AM的命令,用户程序。
2.RM为该应用程序分配第一个Container,并与对应的NM通信,要求它在这个Container中启动应用程序对应的AM。
3.AM启动后向RM注册,用户可以直接通过RM查看应用程序的运行状态。重复4~7。
4.AM采用轮询的方式通过RPC协议向RM申请和领取资源。
5.一旦AM申请到资源后,与对应的NM通信,要求它启动任务。
6.NM为任务设置好运行环境(包括环境变量、JAR包、二级制程序等)后,将任务启动命令写入一个脚本中,通过该脚本启动任务。
7.各个任务通过RPC协议向AM汇报自己的状态和进度,以让AM随时掌握任务的运行状态,从而可以在任务失败时重启任务。
8.任务运行完成后,AM向RM注销并关闭自己。
资源调度器是YARN中最核心的组件之一,且是插拔式的,它定义了一整套接口规范以便用户可按照需要实现自己的调度器。YARN自带了FIFO、Capacity Scheduler和Fair Scheduler三种常用资源调度器,当然,用户可按照接口规范编写一个新的资源调度器,并通过简单的配置使它运行起来。
YARN采用了双层资源调度模型:在第一层中,ResourceManager中的资源调度器将资源分配给各个ApplicationMaster;在第二层中,ApplicationMaster再进一步将资源分配给它内部的各个任务。这里资源调度器主要关注的是第一层的调度问题,至于第二层的调度策略,完全由用户应用程序自己决定。
YARN采用的是pull-base通信模型,而不是push-base通信模型。资源调度器将资源分配给一个应用程序后,它不会立刻push给对应的ApplicationMaster,而是暂时放到一个缓冲区中,等待ApplicationMaster通过周期性的心跳主动来取。
在资源调度器中,每个队列可设置一个最小资源量和最大资源量,其中,最小资源量是资源紧缺情况下每个队列需保证的资源量,而最大资源量则是极端情况下队列也不能超过的资源使用量。资源抢占发生的原因则完全是由于“最小资源量”这一概念。通常而言,为了提高资源利用率,资源调度器(包括Capacity Scheduler和Fair Scheduler) 会将负载较轻的队列的资源暂时分配给负载重的队列(即最小资源量并不是硬资源保证,当队列不需要任何资源时,并不会满足它的最小资源量,而是暂时将空闲资源分配给其他需要资源的队列),仅当负载较轻队列突然收到新提交的应用程序时,调度器才进一步将本属于该队列的资源分配给它。但由于此时资源可能正被其他队列使用,因此调度器必须等待其他队列释放资源后,才能将这些资源“物归原主”,这通常需要一段不确定的等待时间。为了防止应用程序等待时间过长, 调度器等待一段时间后若发现资源并未得到释放,则进行资源抢占。
Hadoop整理四(Hadoop分布式计算框架MapReduce)的更多相关文章
- Hadoop 三剑客之 —— 分布式计算框架 MapReduce
一.MapReduce概述 二.MapReduce编程模型简述 三.combiner & partitioner 四.MapReduce词频统计案例 4.1 项目简介 ...
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- Hadoop 系列(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集. MapReduce ...
- hadoop基础----hadoop理论(四)-----hadoop分布式并行计算模型MapReduce具体解释
我们在前一章已经学习了HDFS: hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详细解释 我们已经知道Hadoop=HDFS(文件系统,数据存储技术相关)+ ...
- 2_分布式计算框架MapReduce
一.mr介绍 1.MapReduce设计理念是移动计算而不是移动数据,就是把分析计算的程序,分别拷贝一份到不同的机器上,而不是移动数据. 2.计算框架有很多,不是谁替换谁的问题,是谁更适合的问题.mr ...
- Hadoop整理三(Hadoop分布式计算框架MapReduce)
一.概念 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",是它们的主要思想.它极大 ...
- 分布式计算框架-MapReduce 基本原理(MP用于分布式计算)
hadoop最主要的2个基本的内容要了解.上次了解了一下HDFS,本章节主要是了解了MapReduce的一些基本原理. MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并 ...
- hadoop深入研究:(十三)——序列化框架
hadoop深入研究:(十三)--序列化框架 Mapreduce之序列化框架(转自http://blog.csdn.net/lastsweetop/article/details/9376495) 框 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
随机推荐
- 【mybatis笔记】 resultType与resultMap的区别
序言: 昨天做一个项目,看到很多刚开始用mybatis的同事对于resultType和resultMap的理解与使用含糊不清,这里我试图用最好理解的说法写一写,欢迎大家勘误. 两者异同: 相同点:re ...
- idea 常用快捷使用
一.智能提示 1.快速移动到错误代码 :Shift+F2 或者 f2/ 2.快速修复:Alt+Enter 3.快速生成括号:Ctrl+Shift+Enter 二.重构 1.重构功能汇总:Ctrl+Sh ...
- eclipse初始设置
1.界面显示设置 2.快捷创建的设置 window->Customize Perspective->Shortcuts 3.修改编码为utf-8 Preferences->Gener ...
- NYOJ 116 士兵杀敌(二) (树状数组)
题目链接 描述 南将军手下有N个士兵,分别编号1到N,这些士兵的杀敌数都是已知的.小工是南将军手下的军师,南将军经常想知道第m号到第n号士兵的总杀敌数,请你帮助小工来回答南将军吧.南将军的某次询问之后 ...
- [转]GCC常用参数详解
简介gcc and g++现在是gnu中最主要和最流行的c & c++编译器 .gcc/g++在执行编译工作的时候,总共需要以下几步:1.预处理,生成.i的文件[预处理器cpp]2.将预处理后 ...
- CSS权重的问题
important > 内联 > ID > 类 > 标签 | 伪类 | 属性选择 > 伪对象 > 继承 > 通配符 1.行内样式,指的是html文档中定义的s ...
- excel导入时候日期格式转成date
最近在做导入的时候发现,excel中设置数值格式是不能有日期的那些符号出现的,/ - : 之类的,否则就会变成数字到了java后台,设置成日期,比如 yyyy-mm-dd 到了后台也是数字,即距离19 ...
- Runtime - Associated Objects (关联对象) 的实现原理
主要围绕3个方面说明runtime-Associated Objects (关联对象) 1. 使用场景 2.如何使用 3.底层实现 3.1 实现原理 3.2 关联对象被存储在什么地方,是不是存放在被 ...
- C 语言问题
1. 如何生成 "半全局变量", 就是那种只能被部分源文件中的部分函数访问变量? 答: 这在C语言中办不到. 如果不能或不方便在一个源文件中放下所有的函数, 那么有三种的解决方案 ...
- C++如何判断大小端
http://bbs.chinaunix.net/thread-1257205-1-1.html #include <stdio.h>#include <string.h>#i ...